Fitur yang tidak digunakan lagi¶
Kata kunci khusus yang tidak digunakan lagi dan agregasi count masih didukung di Hayabusa tetapi tidak akan digunakan di dalam aturan di masa mendatang.
Kata kunci khusus yang tidak digunakan lagi¶
Saat ini, kata kunci khusus berikut dapat ditentukan:
value: mencocokkan berdasarkan string (wildcard dan pipe juga dapat ditentukan).min_length: mencocokkan ketika jumlah karakter lebih besar dari atau sama dengan angka yang ditentukan.regexes: mencocokkan jika salah satu ekspresi reguler dalam file yang Anda tentukan di kolom ini cocok.allowlist: aturan akan dilewati jika ada kecocokan yang ditemukan dalam daftar ekspresi reguler dalam file yang Anda tentukan di kolom ini.
Pada contoh di bawah ini, aturan akan cocok jika hal-hal berikut benar:
ServiceNamebernamamalicious-serviceatau berisi ekspresi reguler di./rules/config/regex/detectlist_suspicous_services.txt.ImagePathmemiliki minimal 1000 karakter.ImagePathtidak memiliki kecocokan apa pun diallowlist.
detection:
selection:
Channel: System
EventID: 7045
ServiceName:
- value: malicious-service
- regexes: ./rules/config/regex/detectlist_suspicous_services.txt
ImagePath:
min_length: 1000
allowlist: ./rules/config/regex/allowlist_legitimate_services.txt
condition: selection
File contoh kata kunci regexes dan allowlist¶
Hayabusa memiliki dua file ekspresi reguler bawaan yang digunakan untuk file ./rules/hayabusa/default/alerts/System/7045_CreateOrModiftySystemProcess-WindowsService_MaliciousServiceInstalled.yml:
./rules/config/regex/detectlist_suspicous_services.txt: untuk mendeteksi nama layanan yang mencurigakan./rules/config/regex/allowlist_legitimate_services.txt: untuk mengizinkan layanan yang sah
File yang didefinisikan di regexes dan allowlist dapat diedit untuk mengubah perilaku semua aturan yang merujuknya tanpa harus mengubah file aturan itu sendiri.
Anda juga dapat menggunakan file teks detectlist dan allowlist berbeda yang Anda buat.
Kondisi agregasi yang tidak digunakan lagi (aturan count)¶
Ini masih didukung di Hayabusa tetapi akan diganti dengan aturan korelasi Sigma di masa mendatang.
Dasar-dasar¶
Kata kunci condition yang dijelaskan di atas mengimplementasikan tidak hanya logika AND dan OR, tetapi juga mampu menghitung atau "mengagregasi" peristiwa.
Fungsi ini disebut "kondisi agregasi" dan ditentukan dengan menghubungkan suatu kondisi dengan pipe.
Pada contoh deteksi password spray di bawah ini, ekspresi kondisional digunakan untuk menentukan apakah ada 5 atau lebih nilai TargetUserName dari satu sumber IpAddress dalam rentang waktu 5 menit.
detection:
selection:
Channel: Security
EventID: 4648
condition: selection | count(TargetUserName) by IpAddress > 5
timeframe: 5m
Kondisi agregasi dapat didefinisikan dalam format berikut:
count() {operator} {number}: Untuk peristiwa log yang cocok dengan kondisi pertama sebelum pipe, kondisi akan cocok jika jumlah log yang cocok memenuhi ekspresi kondisi yang ditentukan oleh{operator}dan{number}.
{operator} dapat berupa salah satu dari berikut:
==: Jika nilai sama dengan nilai yang ditentukan, maka diperlakukan sebagai memenuhi kondisi.>=: Jika nilai lebih besar dari atau sama dengan nilai yang ditentukan, kondisi dianggap telah terpenuhi.>: Jika nilai lebih besar dari nilai yang ditentukan, kondisi dianggap telah terpenuhi.<=: Jika nilai kurang dari atau sama dengan nilai yang ditentukan, kondisi dianggap telah terpenuhi.<: Jika nilai kurang dari nilai yang ditentukan, maka akan diperlakukan seolah-olah kondisi terpenuhi.
{number} harus berupa angka.
timeframe dapat didefinisikan dalam berikut:
15s: 15 detik30m: 30 menit12h: 12 jam7d: 7 hari3M: 3 bulan
Empat pola untuk kondisi agregasi¶
- Tidak ada argumen count atau kata kunci
by. Contoh:selection | count() > 10Jika
selectioncocok lebih dari 10 kali dalam rentang waktu, kondisi akan cocok. Ini diganti dengan aturan korelasi Event Count yang tidak menggunakan kolomgroup-by. - Tidak ada argumen count tetapi ada kata kunci
by. Contoh:selection | count() by IpAddress > 10selectionharus benar lebih dari 10 kali untukIpAddressyang sama. Aturan #2 ini lebih umum daripada aturan #1. Anda juga dapat menentukan beberapa kolom untuk dikelompokkan. Misalnya:by IpAddress, ComputerIni diganti dengan aturan korelasi Event Count yang menggunakan kolomgroup-by. - Ada argumen count tetapi tidak ada kata kunci
by. Contoh:selection | count(TargetUserName) > 10Jika
selectioncocok danTargetUserNameberbeda lebih dari 10 kali dalam rentang waktu, kondisi akan cocok. Ini diganti dengan aturan korelasi Value Count yang tidak menggunakan kolomgroup-by. - Ada argumen count dan kata kunci
by. Contoh:selection | count(Users) by IpAddress > 10Untuk
IpAddressyang sama, perlu ada lebih dari 10TargetUserNameyang berbeda agar kondisi cocok. Aturan #4 ini lebih umum daripada aturan #3. Ini diganti dengan aturan korelasi Value Count yang menggunakan kolomgroup-by.
Contoh Pola 1¶
Ini adalah pola yang paling dasar: count() {operator} {number}. Aturan di bawah ini akan cocok jika selection terjadi 3 kali atau lebih.

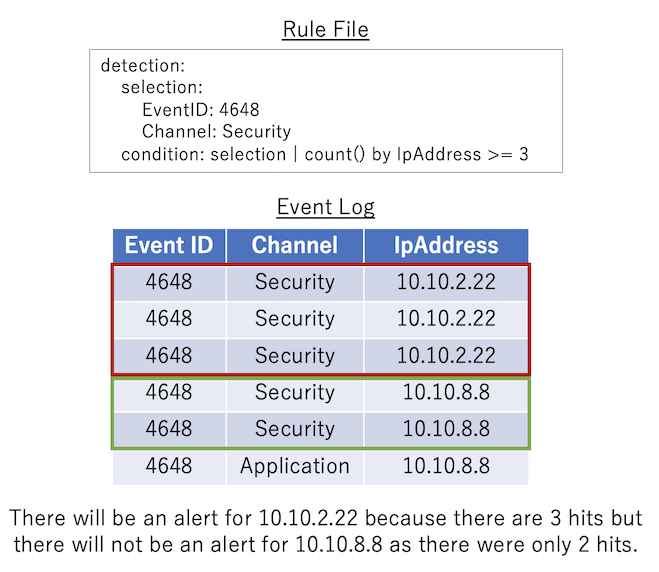
Contoh Pola 2¶
count() by {eventkey} {operator} {number}: Peristiwa log yang cocok dengan condition sebelum pipe dikelompokkan berdasarkan {eventkey} yang sama. Jika jumlah peristiwa yang cocok untuk setiap pengelompokan memenuhi kondisi yang ditentukan oleh {operator} dan {number}, maka kondisi akan cocok.
Contoh Pola 3¶
count({eventkey}) {operator} {number}: Menghitung berapa banyak nilai {eventkey} yang berbeda yang ada dalam peristiwa log yang cocok dengan kondisi sebelum pipe kondisi. Jika jumlahnya memenuhi ekspresi kondisional yang ditentukan dalam {operator} dan {number}, kondisi dianggap telah terpenuhi.

Contoh Pola 4¶
count({eventkey_1}) by {eventkey_2} {operator} {number}: Log yang cocok dengan kondisi sebelum pipe kondisi dikelompokkan berdasarkan {eventkey_2} yang sama, dan jumlah nilai {eventkey_1} yang berbeda di setiap grup dihitung. Jika nilai yang dihitung untuk setiap pengelompokan memenuhi ekspresi kondisional yang ditentukan oleh {operator} dan {number}, kondisi akan cocok.

Output aturan count¶
Output detail untuk aturan count bersifat tetap dan akan mencetak kondisi count asli di [condition] diikuti oleh eventkey yang direkam di [result].
Pada contoh di bawah ini, daftar nama pengguna TargetUserName yang sedang di-bruteforce diikuti oleh sumber IpAddress:
[condition] count(TargetUserName) by IpAddress >= 5 in timeframe [result] count:41 TargetUserName:jorchilles/jlake/cspizor/lpesce/bgalbraith/jkulikowski/baker/eskoudis/dpendolino/sarmstrong/lschifano/drook/rbowes/ebooth/melliott/econrad/sanson/dmashburn/bking/mdouglas/cragoso/psmith/bhostetler/zmathis/thessman/kperryman/cmoody/cdavis/cfleener/gsalinas/wstrzelec/jwright/edygert/ssims/jleytevidal/celgee/Administrator/mtoussain/smisenar/tbennett/bgreenwood IpAddress:10.10.2.22 timeframe:5m
Timestamp peringatan akan menjadi waktu dari peristiwa pertama yang terdeteksi.