已棄用的功能¶
已棄用的特殊關鍵字與 count 聚合功能在 Hayabusa 中仍然受到支援,但未來將不會在規則中使用。
已棄用的特殊關鍵字¶
目前可以指定下列特殊關鍵字:
value:以字串進行比對(也可以指定萬用字元與管線符號)。min_length:當字元數大於或等於指定數值時即比對成功。regexes:如果您在此欄位指定的檔案中的其中一個正規表示式比對成功,即視為比對成功。allowlist:如果在您於此欄位指定的檔案中的正規表示式清單裡找到任何相符項目,則會跳過該規則。
在下方範例中,當以下條件全部成立時,該規則即比對成功:
ServiceName名為malicious-service或包含./rules/config/regex/detectlist_suspicous_services.txt中的某個正規表示式。ImagePath至少有 1000 個字元。ImagePath在allowlist中沒有任何相符項目。
detection:
selection:
Channel: System
EventID: 7045
ServiceName:
- value: malicious-service
- regexes: ./rules/config/regex/detectlist_suspicous_services.txt
ImagePath:
min_length: 1000
allowlist: ./rules/config/regex/allowlist_legitimate_services.txt
condition: selection
regexes 與 allowlist 關鍵字範例檔案¶
Hayabusa 內建兩個正規表示式檔案,供 ./rules/hayabusa/default/alerts/System/7045_CreateOrModiftySystemProcess-WindowsService_MaliciousServiceInstalled.yml 檔案使用:
./rules/config/regex/detectlist_suspicous_services.txt:用於偵測可疑的服務名稱./rules/config/regex/allowlist_legitimate_services.txt:用於允許合法的服務
在 regexes 與 allowlist 中定義的檔案可以加以編輯,藉此變更所有參照它們的規則的行為,而不需要變更任何規則檔案本身。
您也可以使用自己建立的不同 detectlist 與 allowlist 文字檔。
已棄用的聚合條件(count 規則)¶
此功能在 Hayabusa 中仍然受到支援,但未來將由 Sigma 關聯規則取代。
基礎¶
上述的 condition 關鍵字不僅實作了 AND 與 OR 邏輯,也能夠對事件進行計數或「聚合」。
此功能稱為「聚合條件」,透過以管線符號連接條件來指定。
在下方的密碼噴灑偵測範例中,使用條件運算式來判斷在 5 分鐘的時間範圍內,來自同一個來源 IpAddress 是否有 5 個或更多的 TargetUserName 值。
detection:
selection:
Channel: Security
EventID: 4648
condition: selection | count(TargetUserName) by IpAddress > 5
timeframe: 5m
聚合條件可以用下列格式定義:
count() {operator} {number}:對於符合管線符號前第一個條件的記錄事件,如果相符記錄的數量滿足由{operator}與{number}指定的條件運算式,則該條件即比對成功。
{operator} 可以是下列其中之一:
==:如果數值等於指定值,即視為符合條件。>=:如果數值大於或等於指定值,即視為已滿足條件。>:如果數值大於指定值,即視為已滿足條件。<=:如果數值小於或等於指定值,即視為已滿足條件。<:如果數值小於指定值,即視為已滿足條件。
{number} 必須是數字。
timeframe 可以用下列方式定義:
15s:15 秒30m:30 分鐘12h:12 小時7d:7 天3M:3 個月
聚合條件的四種模式¶
- 沒有 count 引數,也沒有
by關鍵字。範例:selection | count() > 10如果
selection在時間範圍內比對成功超過 10 次,則該條件即比對成功。 這些會由不使用group-by欄位的 Event Count 關聯規則取代。 - 沒有 count 引數,但有
by關鍵字。範例:selection | count() by IpAddress > 10對於相同的
IpAddress,selection必須為真超過 10 次。 這些 #2 規則比 #1 規則更為常見。 您也可以指定多個欄位進行分組。例如:by IpAddress, Computer這些會由使用group-by欄位的 Event Count 關聯規則取代。 - 有 count 引數,但沒有
by關鍵字。範例:selection | count(TargetUserName) > 10如果
selection比對成功,且TargetUserName在時間範圍內不同超過 10 次,則該條件即比對成功。 這些會由不使用group-by欄位的 Value Count 關聯規則取代。 - 同時有 count 引數與
by關鍵字。範例:selection | count(Users) by IpAddress > 10對於相同的
IpAddress,必須有超過 10 個不同的TargetUserName,該條件才會比對成功。 這些 #4 規則比 #3 規則更為常見。 這些會由使用group-by欄位的 Value Count 關聯規則取代。
模式 1 範例¶
這是最基本的模式:count() {operator} {number}。下方規則會在 selection 發生 3 次或更多次時比對成功。

模式 2 範例¶
count() by {eventkey} {operator} {number}:符合管線符號前 condition 的記錄事件會依照相同的 {eventkey} 進行分組。如果每個分組的相符事件數量滿足由 {operator} 與 {number} 指定的條件,則該條件即比對成功。
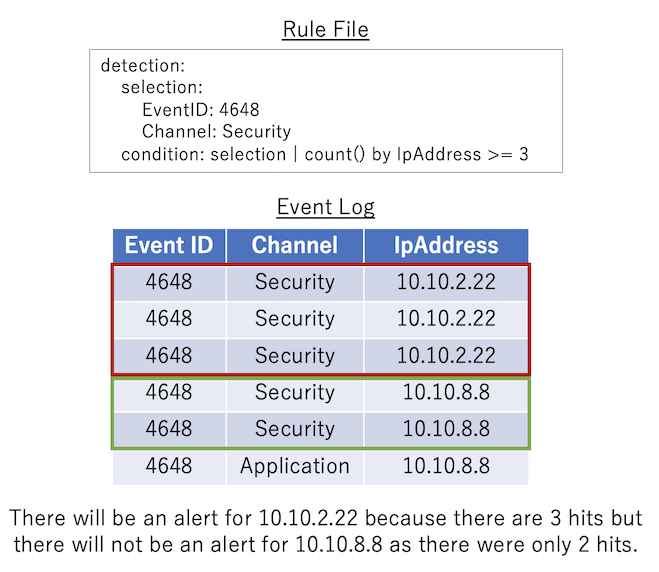
模式 3 範例¶
count({eventkey}) {operator} {number}:計算在符合條件管線符號前條件的記錄事件中,存在多少不同的 {eventkey} 值。如果該數量滿足由 {operator} 與 {number} 指定的條件運算式,則視為已滿足條件。

模式 4 範例¶
count({eventkey_1}) by {eventkey_2} {operator} {number}:符合條件管線符號前條件的記錄會依照相同的 {eventkey_2} 進行分組,並計算每個群組中不同的 {eventkey_1} 值的數量。如果每個分組所計算的值滿足由 {operator} 與 {number} 指定的條件運算式,則該條件即比對成功。

count 規則輸出¶
count 規則的詳細資訊輸出是固定的,會在 [condition] 中印出原始的 count 條件,接著在 [result] 中印出記錄到的 eventkeys。
在下方範例中,列出了遭到暴力破解的 TargetUserName 使用者名稱清單,接著是來源 IpAddress:
[condition] count(TargetUserName) by IpAddress >= 5 in timeframe [result] count:41 TargetUserName:jorchilles/jlake/cspizor/lpesce/bgalbraith/jkulikowski/baker/eskoudis/dpendolino/sarmstrong/lschifano/drook/rbowes/ebooth/melliott/econrad/sanson/dmashburn/bking/mdouglas/cragoso/psmith/bhostetler/zmathis/thessman/kperryman/cmoody/cdavis/cfleener/gsalinas/wstrzelec/jwright/edygert/ssims/jleytevidal/celgee/Administrator/mtoussain/smisenar/tbennett/bgreenwood IpAddress:10.10.2.22 timeframe:5m
警示的時間戳記將會是偵測到第一個事件的時間。