Fonctionnalités obsolètes¶
Les mots-clés spéciaux obsolètes et l'agrégation count sont toujours pris en charge dans Hayabusa mais ne seront plus utilisés à l'intérieur des règles à l'avenir.
Mots-clés spéciaux obsolètes¶
Actuellement, les mots-clés spéciaux suivants peuvent être spécifiés :
value: correspond par chaîne de caractères (des caractères génériques et des pipes peuvent également être spécifiés).min_length: correspond lorsque le nombre de caractères est supérieur ou égal au nombre spécifié.regexes: correspond si l'une des expressions régulières contenues dans le fichier que vous spécifiez dans ce champ correspond.allowlist: la règle sera ignorée s'il existe une correspondance dans la liste des expressions régulières contenues dans le fichier que vous spécifiez dans ce champ.
Dans l'exemple ci-dessous, la règle correspondra si les conditions suivantes sont vraies :
ServiceNames'appellemalicious-serviceou contient une expression régulière dans./rules/config/regex/detectlist_suspicous_services.txt.ImagePathcomporte au minimum 1000 caractères.ImagePathn'a aucune correspondance dans l'allowlist.
detection:
selection:
Channel: System
EventID: 7045
ServiceName:
- value: malicious-service
- regexes: ./rules/config/regex/detectlist_suspicous_services.txt
ImagePath:
min_length: 1000
allowlist: ./rules/config/regex/allowlist_legitimate_services.txt
condition: selection
Fichiers d'exemple pour les mots-clés regexes et allowlist¶
Hayabusa disposait de deux fichiers d'expressions régulières intégrés utilisés pour le fichier ./rules/hayabusa/default/alerts/System/7045_CreateOrModiftySystemProcess-WindowsService_MaliciousServiceInstalled.yml :
./rules/config/regex/detectlist_suspicous_services.txt: pour détecter les noms de services suspects./rules/config/regex/allowlist_legitimate_services.txt: pour autoriser les services légitimes
Les fichiers définis dans regexes et allowlist peuvent être modifiés afin de changer le comportement de toutes les règles qui y font référence, sans avoir à modifier le fichier de règle lui-même.
Vous pouvez également utiliser différents fichiers texte detectlist et allowlist que vous créez vous-même.
Conditions d'agrégation obsolètes (règles count)¶
Cette fonctionnalité est toujours prise en charge dans Hayabusa mais sera remplacée par les règles de corrélation Sigma à l'avenir.
Notions de base¶
Le mot-clé condition décrit ci-dessus implémente non seulement la logique AND et OR, mais est également capable de compter ou « d'agréger » les événements.
Cette fonction est appelée la « condition d'agrégation » et est spécifiée en connectant une condition avec un pipe.
Dans l'exemple de détection de pulvérisation de mots de passe ci-dessous, une expression conditionnelle est utilisée pour déterminer s'il y a 5 valeurs TargetUserName ou plus provenant d'une seule IpAddress source dans un intervalle de temps de 5 minutes.
detection:
selection:
Channel: Security
EventID: 4648
condition: selection | count(TargetUserName) by IpAddress > 5
timeframe: 5m
Les conditions d'agrégation peuvent être définies au format suivant :
count() {operator} {number}: pour les événements de journal qui correspondent à la première condition avant le pipe, la condition correspondra si le nombre de journaux correspondants satisfait l'expression conditionnelle spécifiée par{operator}et{number}.
{operator} peut être l'un des suivants :
==: si la valeur est égale à la valeur spécifiée, elle est considérée comme correspondant à la condition.>=: si la valeur est supérieure ou égale à la valeur spécifiée, la condition est considérée comme remplie.>: si la valeur est supérieure à la valeur spécifiée, la condition est considérée comme remplie.<=: si la valeur est inférieure ou égale à la valeur spécifiée, la condition est considérée comme remplie.<: si la valeur est inférieure à la valeur spécifiée, elle est traitée comme si la condition était remplie.
{number} doit être un nombre.
timeframe peut être défini comme suit :
15s: 15 secondes30m: 30 minutes12h: 12 heures7d: 7 jours3M: 3 mois
Quatre modèles de conditions d'agrégation¶
- Pas d'argument count ni de mot-clé
by. Exemple :selection | count() > 10Si
selectioncorrespond plus de 10 fois dans l'intervalle de temps, la condition correspondra. Celles-ci sont remplacées par des règles de corrélation Event Count qui n'utilisent pas le champgroup-by. - Pas d'argument count mais il y a un mot-clé
by. Exemple :selection | count() by IpAddress > 10selectiondevra être vraie plus de 10 fois pour la mêmeIpAddress. Ces règles n°2 sont plus courantes que les règles n°1. Vous pouvez également spécifier plusieurs champs pour le regroupement. Par exemple :by IpAddress, ComputerCelles-ci sont remplacées par des règles de corrélation Event Count qui utilisent le champgroup-by. - Il y a un argument count mais pas de mot-clé
by. Exemple :selection | count(TargetUserName) > 10Si
selectioncorrespond et queTargetUserNameest différent plus de 10 fois dans l'intervalle de temps, la condition correspondra. Celles-ci sont remplacées par des règles de corrélation Value Count qui n'utilisent pas le champgroup-by. - Il y a à la fois un argument count et un mot-clé
by. Exemple :selection | count(Users) by IpAddress > 10Pour la même
IpAddress, il devra y avoir plus de 10TargetUserNamedifférents pour que la condition corresponde. Ces règles n°4 sont plus courantes que les règles n°3. Celles-ci sont remplacées par des règles de corrélation Value Count qui utilisent le champgroup-by.
Exemple du modèle 1¶
C'est le modèle le plus basique : count() {operator} {number}. La règle ci-dessous correspondra si selection se produit 3 fois ou plus.

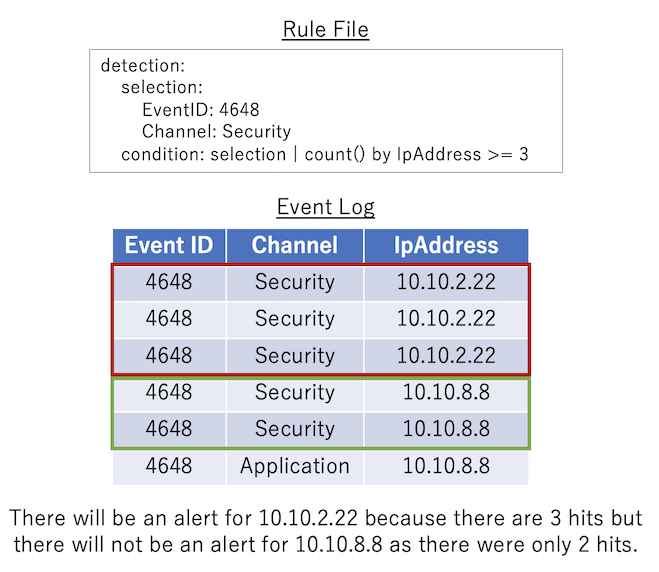
Exemple du modèle 2¶
count() by {eventkey} {operator} {number} : les événements de journal qui correspondent à la condition avant le pipe sont regroupés par la même {eventkey}. Si le nombre d'événements correspondants pour chaque regroupement satisfait la condition spécifiée par {operator} et {number}, alors la condition correspondra.
Exemple du modèle 3¶
count({eventkey}) {operator} {number} : compte le nombre de valeurs différentes de {eventkey} présentes dans l'événement de journal qui correspond à la condition avant le pipe de condition. Si le nombre satisfait l'expression conditionnelle spécifiée dans {operator} et {number}, la condition est considérée comme remplie.

Exemple du modèle 4¶
count({eventkey_1}) by {eventkey_2} {operator} {number} : les journaux qui correspondent à la condition avant le pipe de condition sont regroupés par la même {eventkey_2}, et le nombre de valeurs différentes de {eventkey_1} dans chaque groupe est compté. Si les valeurs comptées pour chaque regroupement satisfont l'expression conditionnelle spécifiée par {operator} et {number}, la condition correspondra.

Sortie des règles count¶
La sortie détaillée des règles count est fixe et affichera la condition count d'origine dans [condition] suivie des eventkeys enregistrées dans [result].
Dans l'exemple ci-dessous, une liste de noms d'utilisateur TargetUserName qui faisaient l'objet d'une attaque par force brute, suivie de l'IpAddress source :
[condition] count(TargetUserName) by IpAddress >= 5 in timeframe [result] count:41 TargetUserName:jorchilles/jlake/cspizor/lpesce/bgalbraith/jkulikowski/baker/eskoudis/dpendolino/sarmstrong/lschifano/drook/rbowes/ebooth/melliott/econrad/sanson/dmashburn/bking/mdouglas/cragoso/psmith/bhostetler/zmathis/thessman/kperryman/cmoody/cdavis/cfleener/gsalinas/wstrzelec/jwright/edygert/ssims/jleytevidal/celgee/Administrator/mtoussain/smisenar/tbennett/bgreenwood IpAddress:10.10.2.22 timeframe:5m
Le timestamp de l'alerte sera l'heure du premier événement détecté.