Panduan Performa Rust untuk Pengembang Hayabusa¶
Penulis¶
Fukusuke Takahashi
Terjemahan bahasa Inggris¶
Zach Mathis (@yamatosecurity)
Tentang dokumen ini¶
Hayabusa (bahasa Inggris: "peregrine falcon") adalah alat analisis forensik cepat yang dikembangkan oleh kelompok Yamato Security di Jepang. Alat ini dikembangkan dengan Rust agar dapat melakukan (threat) hunting secepat seekor elang peregrine. Rust sendiri adalah bahasa yang cepat, namun ada banyak jebakan yang dapat mengakibatkan kecepatan lambat dan penggunaan memori tinggi. Kami membuat dokumen ini berdasarkan peningkatan performa nyata di Hayabusa (lihat changelog di sini), tetapi teknik-teknik ini seharusnya juga dapat diterapkan pada program Rust lainnya. Kami berharap Anda dapat memperoleh manfaat dari pengetahuan yang kami peroleh melalui proses coba-coba.
Peningkatan kecepatan¶
Ganti memory allocator¶
Hanya dengan mengganti memory allocator bawaan dapat meningkatkan kecepatan secara signifikan. Sebagai contoh, menurut benchmark ini, dua memory allocator berikut
jauh lebih cepat daripada memory allocator bawaan. Kami dapat memastikan peningkatan kecepatan yang signifikan dengan mengganti memory allocator kami dari jemalloc ke mimalloc, sehingga kami menjadikan mimalloc sebagai bawaan sejak versi 1.8.0. (Meskipun mimalloc memang menggunakan memori sedikit lebih banyak daripada jemalloc.)
Sebelum ¶
Sesudah ¶
Anda hanya perlu melakukan 2 langkah berikut untuk mengganti memory allocator global:
- Tambahkan crate mimalloc ke bagian [dependencies] pada file
Cargo.toml: - Definisikan bahwa Anda ingin menggunakan mimalloc di bawah #[global_allocator] di suatu tempat dalam program: Hanya itu yang perlu Anda lakukan untuk mengganti memory allocator.
Efektivitas(Contoh nyata dari sebuah Pull Request) ¶
Seberapa besar kecepatan meningkat akan bergantung pada program, tetapi pada contoh berikut
mengganti memory allocator menjadi mimalloc menghasilkan peningkatan performa 20-30% pada CPU Intel. (Entah mengapa, tidak ada peningkatan performa yang sesignifikan itu pada perangkat macOS berbasis ARM.)
Kurangi pemrosesan IO di dalam loop¶
Pemrosesan IO disk jauh lebih lambat daripada pemrosesan di memori. Oleh karena itu, sebaiknya hindari pemrosesan IO sebanyak mungkin, terutama di dalam loop.
Sebelum ¶
Contoh di bawah ini menunjukkan pembukaan file yang terjadi satu juta kali di dalam loop:
use std::fs;
fn main() {
for _ in 0..1000000 {
let f = fs::read_to_string("sample.txt").unwrap();
f.len();
}
}
Sesudah ¶
Dengan membuka file di luar loop seperti berikut
use std::fs;
fn main() {
let f = fs::read_to_string("sample.txt").unwrap();
for _ in 0..1000000 {
f.len();
}
}
Efektivitas(Contoh nyata dari sebuah Pull Request) ¶
Pada contoh berikut, pemrosesan IO saat menangani satu hasil deteksi pada satu waktu berhasil dilakukan di luar loop:
Ini menghasilkan peningkatan kecepatan sekitar 20%.
Hindari kompilasi ekspresi reguler di dalam loop¶
Kompilasi ekspresi reguler adalah proses yang sangat mahal dibandingkan dengan pencocokan ekspresi reguler. Oleh karena itu, disarankan untuk menghindari kompilasi ekspresi reguler sebanyak mungkin, terutama di dalam loop.
Sebelum ¶
Sebagai contoh, proses berikut membuat 100.000 percobaan untuk mencocokkan ekspresi reguler di dalam loop:
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..100000 {
if Regex::new(match_str).unwrap().is_match(text){ // Regular expression compilation in a loop
println!("matched!");
}
}
}
Sesudah ¶
Dengan melakukan kompilasi ekspresi reguler di luar loop, seperti yang ditunjukkan di bawah ini
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap(); // Compile the regular expression outside the loop
for _ in 0..100000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Efektivitas(Contoh nyata dari sebuah Pull Request) ¶
Pada contoh berikut, kompilasi ekspresi reguler dilakukan di luar loop dan di-cache.
Ini menghasilkan peningkatan kecepatan yang signifikan.
Gunakan buffer IO¶
Tanpa buffer IO, IO file menjadi lambat. Dengan buffer IO, operasi IO dilakukan melalui buffer di memori, mengurangi jumlah system call dan meningkatkan kecepatan.
Sebelum ¶
Sebagai contoh, pada proses berikut, write terjadi 1.000.000 kali.
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
for _ in 0..1000000 {
f.write(b"hello world!");
}
}
Sesudah ¶
Dengan menggunakan BufWriter seperti berikut
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
let mut writer = BufWriter::new(f);
for _ in 0..1000000 {
writer.write(b"some text");
}
writer.flush().unwrap();
}
Efektivitas(Contoh nyata dari sebuah Pull Request) ¶
Metode yang dijelaskan di atas diimplementasikan di sini
dan telah menghasilkan peningkatan kecepatan yang signifikan dalam pemrosesan output.
Gunakan metode String standar alih-alih ekspresi reguler¶
Meskipun ekspresi reguler dapat mencakup pola pencocokan yang kompleks, ekspresi tersebut lebih lambat daripada metode String standar. Oleh karena itu, lebih cepat menggunakan metode String standar untuk pencocokan string sederhana seperti berikut.
- Pencocokan starts-with(Regex:
foo.*)-> String::starts_with() - Pencocokan ends-with(Regex:
.*foo)-> String::ends_with() - Pencocokan contains(Regex:
.*foo.*)-> String::contains()
Sebelum ¶
Sebagai contoh, kode berikut melakukan pencocokan ends-with dalam ekspresi reguler satu juta kali.
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = ".*abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Sesudah ¶
Dengan menggunakan String::ends_with() seperti berikut
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..1000000 {
if text.ends_with(match_str) {
println!("matched!");
}
}
}
Efektivitas(Contoh nyata dari sebuah Pull Request) ¶
Karena Hayabusa memerlukan perbandingan string yang tidak peka huruf besar/kecil, kami menggunakan to_lowercase() lalu menerapkan metode di atas. Bahkan dengan begitu, pada contoh-contoh berikut
- Imporving speed by changing wildcard search process from regular expression match to starts_with/ends_with match #890
- Improving speed by using eq_ignore_ascii_case() before regular expression match #884
kecepatan meningkat sekitar 15% dibandingkan sebelumnya.
Filter berdasarkan panjang string¶
Tergantung pada karakteristik string yang ditangani, menambahkan filter sederhana dapat mengurangi jumlah percobaan pencocokan string dan mempercepat proses. Jika Anda sering membandingkan string dengan panjang yang tidak tetap dan tidak cocok, Anda dapat mempercepat proses dengan menggunakan panjang string sebagai filter utama.
Sebelum ¶
Sebagai contoh, kode berikut mencoba satu juta pencocokan ekspresi reguler.
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Sesudah ¶
Dengan menggunakan String::len() sebagai filter utama, seperti yang ditunjukkan di bawah ini
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if text.len() == match_str.len() { // Primary filter by string length
if r.is_match(text) {
println!("matched!");
}
}
}
}
Efektivitas(Contoh nyata dari sebuah Pull Request) ¶
Pada contoh berikut, metode di atas digunakan.
Ini meningkatkan kecepatan sekitar 15%.
Jangan kompilasi dengan codegen-units=1¶
Banyak artikel tentang optimasi performa dengan Rust menyarankan untuk menambahkan codegen-units = 1 di bawah bagian [profile.release].
Ini akan menyebabkan waktu kompilasi yang lebih lambat karena defaultnya adalah mengompilasi secara paralel, tetapi secara teori seharusnya menghasilkan kode yang lebih teroptimasi dan lebih cepat.
Namun, dalam pengujian kami, Hayabusa justru berjalan lebih lambat dengan opsi ini diaktifkan dan kompilasi memakan waktu lebih lama sehingga kami menonaktifkannya.
Ukuran biner dari executable sekitar 100kb lebih kecil sehingga ini mungkin ideal untuk sistem tertanam (embedded) yang ruang hard disk-nya terbatas.
Mengurangi penggunaan memori¶
Hindari penggunaan clone(), to_string(), dan to_owned() yang tidak perlu¶
Menggunakan clone() atau to_string() adalah cara mudah untuk menyelesaikan error kompilasi terkait ownership. Namun, biasanya hal tersebut akan menghasilkan penggunaan memori yang tinggi dan sebaiknya dihindari. Selalu lebih baik untuk pertama-tama melihat apakah Anda dapat menggantinya dengan referensi berbiaya rendah.
Sebelum ¶
Sebagai contoh, jika Anda ingin melakukan iterasi pada Vec yang sama beberapa kali, Anda dapat menggunakan clone() untuk menghilangkan error kompilasi.
fn main() {
let lst = vec![1, 2, 3];
for x in lst.clone() { // In order to eliminate compile errors
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
Sesudah ¶
Namun, dengan menggunakan referensi seperti yang ditunjukkan di bawah ini, Anda dapat menghilangkan kebutuhan untuk menggunakan clone().
fn main() {
let lst = vec![1, 2, 3];
for x in &lst { // Eliminate compile errors with a reference
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
Efektivitas(Contoh nyata dari sebuah Pull Request) ¶
Pada contoh berikut, dengan mengganti penggunaan clone(), to_string(), dan to_owned() yang tidak perlu,
kami berhasil mengurangi penggunaan memori secara signifikan.
Gunakan Iterator alih-alih Vec¶
Vec menyimpan semua elemen di memori, sehingga menggunakan banyak memori sebanding dengan jumlah elemen. Jika memproses satu elemen pada satu waktu sudah cukup, maka menggunakan Iterator sebagai gantinya akan menggunakan memori yang jauh lebih sedikit.
Sebelum ¶
Sebagai contoh, fungsi return_lines() berikut membaca file sekitar 1 GB dan mengembalikan sebuah Vec:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> Vec<String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
.collect()
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
Sesudah ¶
Sebagai gantinya Anda harus mengembalikan sebuah Iterator Trait seperti berikut:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> impl Iterator<Item=String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
// ここでcollect()せずに、Iteratorを戻り値として返す
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
Box<dyn Iterator<Item = T>> seperti berikut:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines(need_filter:bool) -> Box<dyn Iterator<Item = String>> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
if need_filter {
let result= buf.lines()
.filter_map(|l| l.ok())
.map(|l| l.replace("A", "B"));
return Box::new(result)
}
let result= buf.lines()
.map(|l| l.expect("Could not parse line"));
Box::new(result)
}
fn main() {
let lines = return_lines(true);
for line in lines {
println!("{}", line)
}
}
Efektivitas(Contoh nyata dari sebuah Pull Request) ¶
Contoh berikut menggunakan metode yang dijelaskan di atas:
Ketika diuji pada file JSON berukuran 1,7GB, memori berkurang 75%.
Gunakan crate compact_str saat menangani string pendek¶
Saat menangani sejumlah besar string pendek yang kurang dari 24 byte, crate compact_str dapat digunakan untuk mengurangi penggunaan memori.
Sebelum ¶
Pada contoh di bawah ini, Vec menyimpan 10 juta string.
fn main() {
let v: Vec<String> = vec![String::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
Sesudah ¶
Lebih baik menggantinya dengan sebuah CompactString:
use compact_str::CompactString;
fn main() {
let v: Vec<CompactString> = vec![CompactString::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
Efektivitas(Contoh nyata dari sebuah Pull Request) ¶
Pada contoh berikut, string pendek ditangani dengan CompactString:
Ini memberikan pengurangan penggunaan memori sekitar 20%.
Hapus field yang tidak perlu dalam struktur yang berumur panjang¶
Struktur yang terus dipertahankan di memori selama proses berjalan dapat memengaruhi keseluruhan penggunaan memori. Di Hayabusa, struktur berikut (per versi 2.2.2), khususnya, dipertahankan dalam jumlah besar.
Penghapusan field yang terkait dengan struktur di atas memberikan efek dalam mengurangi keseluruhan penggunaan memori.
Sebelum ¶
Sebagai contoh, field DetectInfo adalah, hingga versi 1.8.1, sebagai berikut:
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
pub record_information: CompactString,
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
Sesudah ¶
Dengan menghapus field record_information seperti berikut
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
// remove record_information field
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
Efektivitas(Contoh nyata dari sebuah Pull Request) ¶
Pada contoh berikut, ketika diuji terhadap data dengan jumlah record hasil deteksi sekitar 1,5 juta,
- Reduced memory usage of DetectInfo/EvtxRecordInfo #837
- Reduce memory usage by removing unnecessary regex #894
kami berhasil mencapai pengurangan penggunaan memori sekitar 300MB.
Benchmarking¶
Gunakan fungsi statistik dari memory allocator.¶
Beberapa memory allocator menyimpan statistik penggunaan memori mereka sendiri. Sebagai contoh, di mimalloc, fungsi mi_stats_print_out() dapat dipanggil untuk memperoleh penggunaan memori.
Cara memperoleh statistik ¶
Prasyarat: Anda perlu menggunakan mimalloc seperti yang dijelaskan di bagian Ganti memory allocator.
- Di bagian dependencies pada
Cargo.toml, tambahkan crate libmimalloc-sys: - Kapan pun Anda ingin mencetak statistik penggunaan memori, tulis kode berikut dan di dalam blok
unsafe, panggil mi_stats_print_out(). Statistik penggunaan memori akan dikeluarkan ke standard out. -
Nilai
peak/reserveddi kiri atas adalah penggunaan memori maksimum.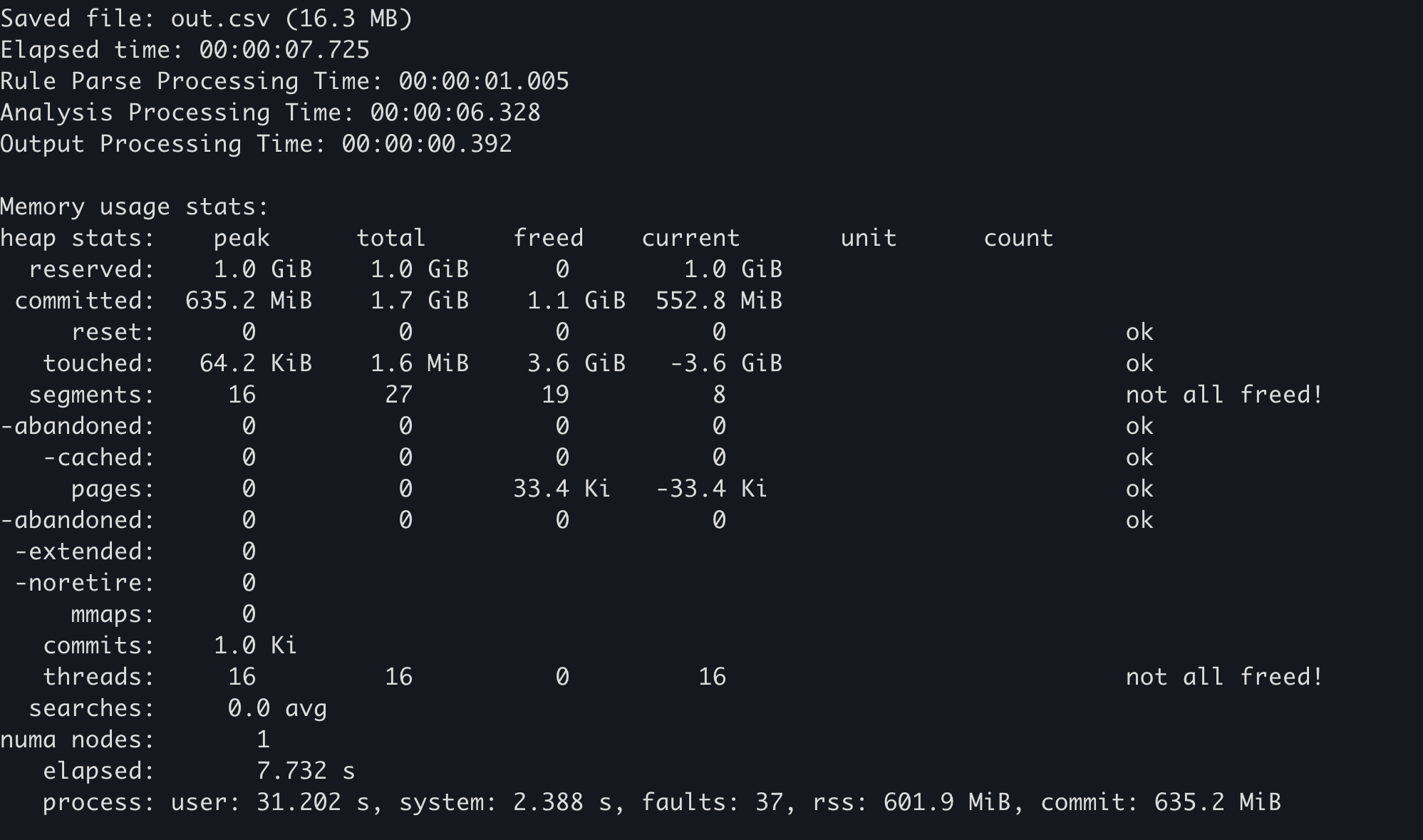
Contoh ¶
Implementasi di atas diterapkan pada berikut:
Di Hayabusa, jika Anda menambahkan opsi --debug, statistik penggunaan memori akan dikeluarkan di akhir.
Gunakan performance counter Windows¶
Berbagai penggunaan sumber daya dapat diperiksa dari statistik yang dapat diperoleh dari sisi OS. Dalam hal ini, dua hal berikut perlu diperhatikan.
- Pengaruh dari perangkat lunak anti-virus (Windows Defender)
- Hanya proses pertama yang dipengaruhi oleh pemindaian dan lebih lambat, sehingga hasil dari proses kedua dan selanjutnya setelah build cocok untuk perbandingan. (Atau Anda dapat menonaktifkan anti-virus Anda untuk hasil yang lebih akurat.)
- Pengaruh dari caching file
- Hasil dari kali kedua dan selanjutnya setelah OS dinyalakan lebih cepat daripada kali pertama karena evtx dan IO file lainnya dibaca dari cache file di memori, sehingga hasil dari kali pertama setelah OS booting lebih ideal untuk mengambil benchmark.
Cara memperoleh ¶
Prasyarat:Prosedur berikut hanya valid untuk lingkungan di mana PowerShell 7 sudah terpasang di Windows.
- Restart OS
- Jalankan perintah Get-Counter dari
PowerShell 7yang akan terus merekam performance counter setiap detik ke file CSV. (Jika Anda ingin mengukur sumber daya selain yang tercantum di bawah ini, artikel ini adalah referensi yang baik.) - Eksekusi proses yang ingin Anda ukur.
Contoh ¶
Berikut ini berisi contoh prosedur untuk mengukur performa dengan Hayabusa.
Gunakan heaptrack¶
heaptrack adalah memory profiler canggih yang tersedia untuk Linux dan macOS. Dengan menggunakan heaptrack, Anda dapat menyelidiki bottleneck secara menyeluruh.
Cara memperoleh ¶
Prasyarat: Berikut adalah prosedur untuk Ubuntu 22.04. Anda tidak dapat menggunakan heaptrack di Windows.
- Pasang heaptrack dengan dua perintah berikut.
- Hapus kode mimalloc berikut dari Hayabusa. (Anda tidak dapat menggunakan memory profiler heaptrack dengan mimalloc.
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L32-L33
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L59-L60
-
https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L632-L634
-
Hapus bagian [profile.release] di file
Cargo.tomlHayabusa dan ubah menjadi berikut: -
Build sebuah release build:
cargo build --release - Jalankan
heaptrack hayabusa csv-timeline -d sample -o out.csv
Sekarang ketika Hayabusa selesai berjalan, hasil heaptrack akan otomatis terbuka di aplikasi GUI.
Contoh ¶
Contoh hasil heaptrack ditunjukkan di bawah ini. Tab Flame Graph dan Top-Down memungkinkan Anda memeriksa secara visual fungsi-fungsi dengan penggunaan memori yang tinggi.
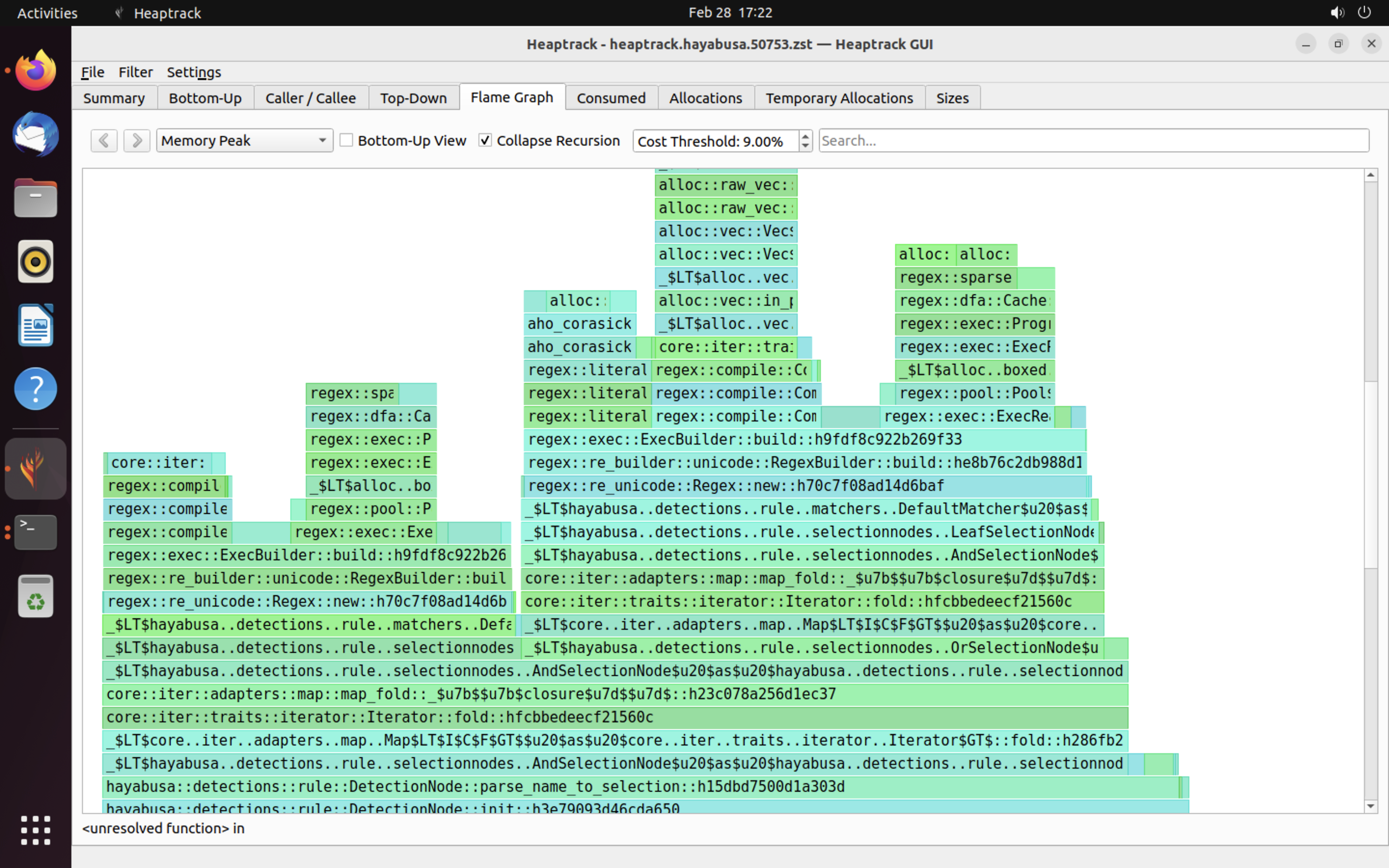
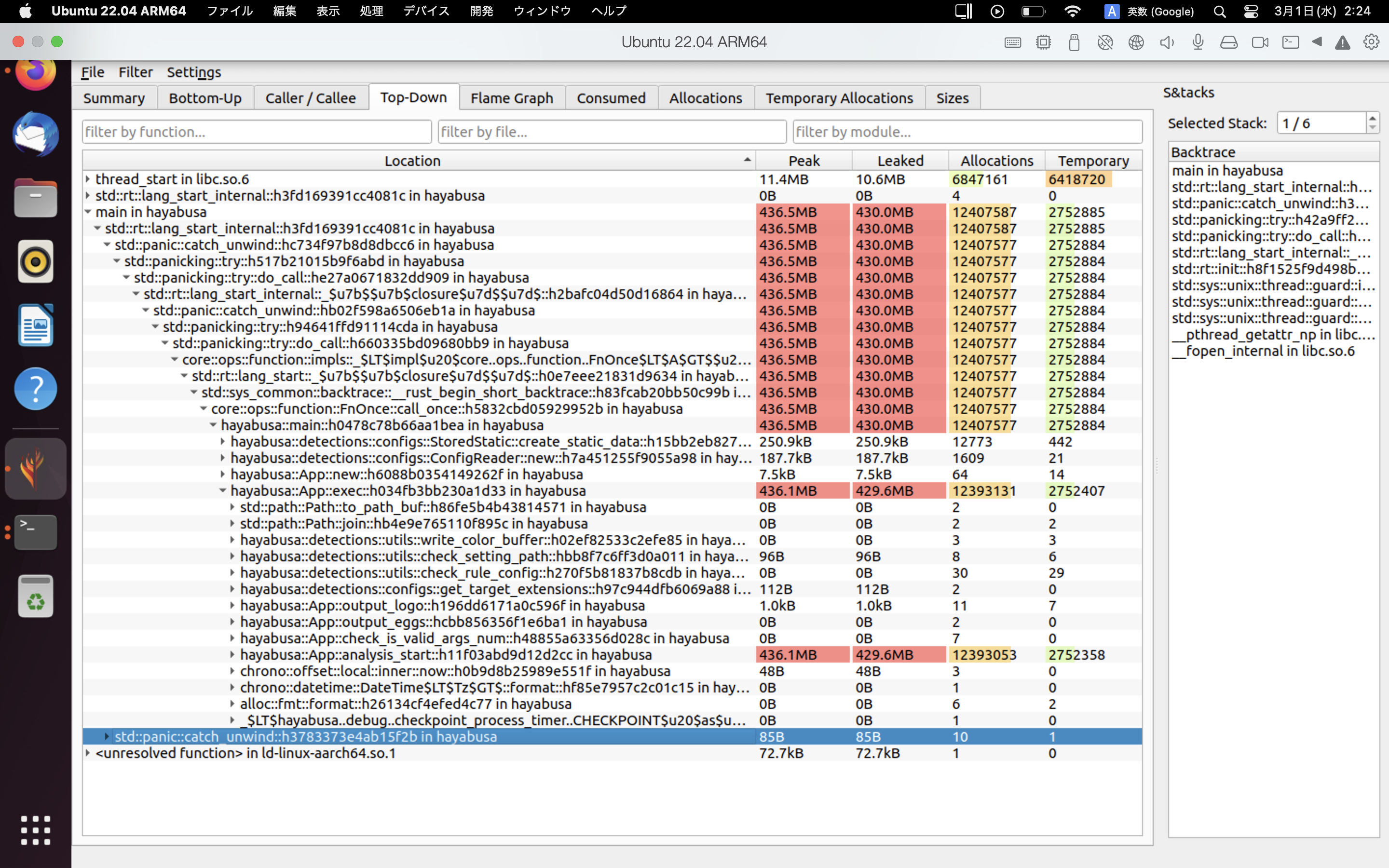
Referensi¶
Kontribusi¶
Dokumen ini didasarkan pada temuan dari kasus perbaikan nyata di Hayabusa. Jika Anda menemukan kesalahan atau teknik yang dapat meningkatkan performa, silakan kirimkan issue atau pull request kepada kami.