အသုံးပြုခြင်းရပ်ဆိုင်းထားသော features များ¶
အသုံးပြုခြင်းရပ်ဆိုင်းထားသော special keywords များနှင့် count aggregation ကို Hayabusa တွင် ဆက်လက်အသုံးပြုနိုင်သေးသော်လည်း အနာဂတ်တွင် rules များအတွင်း၌ အသုံးပြုတော့မည်မဟုတ်ပါ။
အသုံးပြုခြင်းရပ်ဆိုင်းထားသော special keywords များ¶
လောလောဆယ်တွင် အောက်ပါ special keywords များကို သတ်မှတ်နိုင်ပါသည်-
value: string ဖြင့် ကိုက်ညီမှုရှာသည် (wildcards နှင့် pipes များကိုလည်း သတ်မှတ်နိုင်သည်)။min_length: စာလုံးအရေအတွက်သည် သတ်မှတ်ထားသော အရေအတွက်ထက် ကြီးသည် သို့မဟုတ် တူညီသည့်အခါ ကိုက်ညီသည်။regexes: ဤ field တွင် သင်သတ်မှတ်ထားသော file အတွင်းရှိ regular expressions များထဲမှ တစ်ခုခုကိုက်ညီပါက ကိုက်ညီသည်။allowlist: ဤ field တွင် သင်သတ်မှတ်ထားသော file အတွင်းရှိ regular expressions စာရင်းတွင် ကိုက်ညီမှုတစ်ခုခုတွေ့ရှိပါက rule ကို ကျော်သွားမည်ဖြစ်သည်။
အောက်ပါဥပမာတွင် အောက်ပါအချက်များမှန်ကန်ပါက rule သည် ကိုက်ညီမည်ဖြစ်သည်-
ServiceNameကိုmalicious-serviceဟုခေါ်သည် သို့မဟုတ်./rules/config/regex/detectlist_suspicous_services.txtအတွင်းရှိ regular expression တစ်ခုပါဝင်သည်။ImagePathတွင် အနည်းဆုံး စာလုံး ၁၀၀၀ ရှိသည်။ImagePathတွင်allowlistအတွင်း ကိုက်ညီမှုတစ်စုံတစ်ရာ မရှိပါ။
detection:
selection:
Channel: System
EventID: 7045
ServiceName:
- value: malicious-service
- regexes: ./rules/config/regex/detectlist_suspicous_services.txt
ImagePath:
min_length: 1000
allowlist: ./rules/config/regex/allowlist_legitimate_services.txt
condition: selection
regexes နှင့် allowlist keyword နမူနာ file များ¶
Hayabusa တွင် ./rules/hayabusa/default/alerts/System/7045_CreateOrModiftySystemProcess-WindowsService_MaliciousServiceInstalled.yml file အတွက် အသုံးပြုသော built-in regular expression file နှစ်ခုရှိသည်-
./rules/config/regex/detectlist_suspicous_services.txt: သံသယဖြစ်ဖွယ် service နာမည်များကို ထောက်လှမ်းရန်./rules/config/regex/allowlist_legitimate_services.txt: တရားဝင် service များကို ခွင့်ပြုရန်
regexes နှင့် allowlist တွင် သတ်မှတ်ထားသော file များကို rule file ကိုယ်တိုင်ကို မပြောင်းလဲဘဲ ၎င်းတို့ကို ကိုးကားသော rule အားလုံး၏ အပြုအမူကို ပြောင်းလဲရန် တည်းဖြတ်နိုင်သည်။
သင်ဖန်တီးထားသော မတူညီသော detectlist နှင့် allowlist textfiles များကိုလည်း အသုံးပြုနိုင်သည်။
အသုံးပြုခြင်းရပ်ဆိုင်းထားသော aggregation conditions များ (count rules)¶
ဤအရာကို Hayabusa တွင် ဆက်လက်အသုံးပြုနိုင်သေးသော်လည်း အနာဂတ်တွင် Sigma correlation rules များဖြင့် အစားထိုးမည်ဖြစ်သည်။
အခြေခံများ¶
အထက်တွင် ဖော်ပြခဲ့သော condition keyword သည် AND နှင့် OR logic ကိုသာ implement လုပ်သည်မဟုတ်ဘဲ events များကို ရေတွက်ခြင်း သို့မဟုတ် "aggregate" လုပ်နိုင်သည်။
ဤfunction ကို "aggregation condition" ဟုခေါ်ပြီး condition တစ်ခုကို pipe ဖြင့်ချိတ်ဆက်ခြင်းဖြင့် သတ်မှတ်သည်။
အောက်ပါ password spray ထောက်လှမ်းခြင်းဥပမာတွင် မိနစ် ၅ အတွင်း source IpAddress တစ်ခုမှ TargetUserName တန်ဖိုး ၅ ခု သို့မဟုတ် ထို့ထက်ပိုရှိမရှိ ဆုံးဖြတ်ရန် conditional expression ကို အသုံးပြုသည်။
detection:
selection:
Channel: Security
EventID: 4648
condition: selection | count(TargetUserName) by IpAddress > 5
timeframe: 5m
Aggregation conditions များကို အောက်ပါ format ဖြင့် သတ်မှတ်နိုင်သည်-
count() {operator} {number}: pipe မတိုင်မီ ပထမ condition နှင့် ကိုက်ညီသော log events များအတွက် ကိုက်ညီသော log အရေအတွက်သည်{operator}နှင့်{number}ဖြင့် သတ်မှတ်ထားသော condition expression ကို ပြည့်မီပါက condition သည် ကိုက်ညီမည်ဖြစ်သည်။
{operator} သည် အောက်ပါတို့မှ တစ်ခုဖြစ်နိုင်သည်-
==: တန်ဖိုးသည် သတ်မှတ်ထားသော တန်ဖိုးနှင့် တူညီပါက condition နှင့် ကိုက်ညီသည်ဟု သတ်မှတ်သည်။>=: တန်ဖိုးသည် သတ်မှတ်ထားသော တန်ဖိုးထက် ကြီးသည် သို့မဟုတ် တူညီပါက condition ပြည့်မီသည်ဟု သတ်မှတ်သည်။>: တန်ဖိုးသည် သတ်မှတ်ထားသော တန်ဖိုးထက် ကြီးပါက condition ပြည့်မီသည်ဟု သတ်မှတ်သည်။<=: တန်ဖိုးသည် သတ်မှတ်ထားသော တန်ဖိုးထက် ငယ်သည် သို့မဟုတ် တူညီပါက condition ပြည့်မီသည်ဟု သတ်မှတ်သည်။<: တန်ဖိုးသည် သတ်မှတ်ထားသော တန်ဖိုးထက် ငယ်ပါက condition ပြည့်မီသကဲ့သို့ သတ်မှတ်မည်ဖြစ်သည်။
{number} သည် ဂဏန်းဖြစ်ရမည်။
timeframe ကို အောက်ပါအတိုင်း သတ်မှတ်နိုင်သည်-
15s: ၁၅ စက္ကန့်30m: ၃၀ မိနစ်12h: ၁၂ နာရီ7d: ၇ ရက်3M: ၃ လ
Aggregation conditions များအတွက် ပုံစံ လေးမျိုး¶
- count argument သို့မဟုတ်
bykeyword မရှိ။ ဥပမာ-selection | count() > 10selectionသည် time frame အတွင်း ၁၀ ကြိမ်ထက်ပို၍ ကိုက်ညီပါက condition သည် ကိုက်ညီမည်ဖြစ်သည်။ ၎င်းတို့ကိုgroup-byfield ကို အသုံးမပြုသော Event Count correlation rules များဖြင့် အစားထိုးသည်။ - count argument မရှိသော်လည်း
bykeyword ရှိ။ ဥပမာ-selection | count() by IpAddress > 10တူညီသော
IpAddressအတွက်selectionသည် ၁၀ ကြိမ်ထက်ပို၍ မှန်ကန်ရမည်။ ဤ #2 rules များသည် #1 rules များထက် ပိုမိုအဖြစ်များသည်။ group-by လုပ်ရန် field များစွာကိုလည်း သတ်မှတ်နိုင်သည်။ ဥပမာ-by IpAddress, Computer၎င်းတို့ကိုgroup-byfield ကို အသုံးပြုသော Event Count correlation rules များဖြင့် အစားထိုးသည်။ - count argument ရှိသော်လည်း
bykeyword မရှိ။ ဥပမာ-selection | count(TargetUserName) > 10selectionကိုက်ညီပြီးTargetUserNameသည် time frame အတွင်း ၁၀ ကြိမ်ထက်ပို၍ မတူညီပါက condition သည် ကိုက်ညီမည်ဖြစ်သည်။ ၎င်းတို့ကိုgroup-byfield ကို အသုံးမပြုသော Value Count correlation rules များဖြင့် အစားထိုးသည်။ - count argument နှင့်
bykeyword နှစ်ခုလုံးရှိ။ ဥပမာ-selection | count(Users) by IpAddress > 10တူညီသော
IpAddressအတွက် condition ကိုက်ညီရန် မတူညီသောTargetUserName၁၀ ခုထက်ပို၍ လိုအပ်မည်ဖြစ်သည်။ ဤ #4 rules များသည် #3 rules များထက် ပိုမိုအဖြစ်များသည်။ ၎င်းတို့ကိုgroup-byfield ကို အသုံးပြုသော Value Count correlation rules များဖြင့် အစားထိုးသည်။
ပုံစံ ၁ ဥပမာ¶
ဤသည်မှာ အခြေခံအကျဆုံး ပုံစံဖြစ်သည်- count() {operator} {number}။ အောက်ပါ rule သည် selection သည် ၃ ကြိမ် သို့မဟုတ် ထို့ထက်ပိုဖြစ်ပါက ကိုက်ညီမည်ဖြစ်သည်။

ပုံစံ ၂ ဥပမာ¶
count() by {eventkey} {operator} {number}: pipe မတိုင်မီ condition နှင့် ကိုက်ညီသော log events များကို တူညီသော {eventkey} ဖြင့် အုပ်စုဖွဲ့သည်။ အုပ်စုတစ်ခုစီအတွက် ကိုက်ညီသော events အရေအတွက်သည် {operator} နှင့် {number} ဖြင့် သတ်မှတ်ထားသော condition ကို ပြည့်မီပါက condition သည် ကိုက်ညီမည်ဖြစ်သည်။
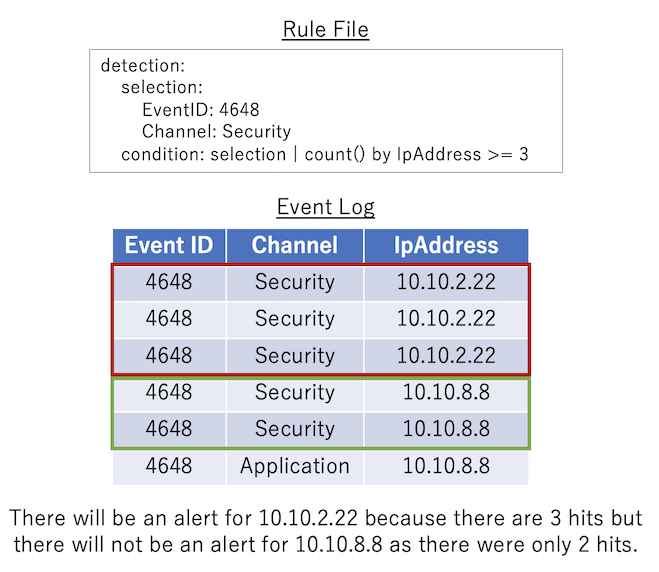
ပုံစံ ၃ ဥပမာ¶
count({eventkey}) {operator} {number}: condition pipe မတိုင်မီ condition နှင့် ကိုက်ညီသော log event အတွင်း {eventkey} ၏ မတူညီသော တန်ဖိုး မည်မျှရှိသည်ကို ရေတွက်သည်။ အရေအတွက်သည် {operator} နှင့် {number} တွင် သတ်မှတ်ထားသော conditional expression ကို ပြည့်မီပါက condition ပြည့်မီသည်ဟု သတ်မှတ်သည်။

ပုံစံ ၄ ဥပမာ¶
count({eventkey_1}) by {eventkey_2} {operator} {number}: condition pipe မတိုင်မီ condition နှင့် ကိုက်ညီသော logs များကို တူညီသော {eventkey_2} ဖြင့် အုပ်စုဖွဲ့ပြီး အုပ်စုတစ်ခုစီအတွင်း {eventkey_1} ၏ မတူညီသော တန်ဖိုး အရေအတွက်ကို ရေတွက်သည်။ အုပ်စုတစ်ခုစီအတွက် ရေတွက်ထားသော တန်ဖိုးများသည် {operator} နှင့် {number} ဖြင့် သတ်မှတ်ထားသော conditional expression ကို ပြည့်မီပါက condition သည် ကိုက်ညီမည်ဖြစ်သည်။

Count rule output¶
count rules များအတွက် details output သည် ပုံသေဖြစ်ပြီး မူရင်း count condition ကို [condition] တွင် print ထုတ်ပြီးနောက် မှတ်တမ်းတင်ထားသော eventkeys များကို [result] တွင် ဖော်ပြမည်ဖြစ်သည်။
အောက်ပါဥပမာတွင် bruteforce လုပ်ခံရသော TargetUserName usernames စာရင်းပြီးနောက် source IpAddress ပါဝင်သည်-
[condition] count(TargetUserName) by IpAddress >= 5 in timeframe [result] count:41 TargetUserName:jorchilles/jlake/cspizor/lpesce/bgalbraith/jkulikowski/baker/eskoudis/dpendolino/sarmstrong/lschifano/drook/rbowes/ebooth/melliott/econrad/sanson/dmashburn/bking/mdouglas/cragoso/psmith/bhostetler/zmathis/thessman/kperryman/cmoody/cdavis/cfleener/gsalinas/wstrzelec/jwright/edygert/ssims/jleytevidal/celgee/Administrator/mtoussain/smisenar/tbennett/bgreenwood IpAddress:10.10.2.22 timeframe:5m
alert ၏ timestamp သည် ပထမဆုံးထောက်လှမ်းတွေ့ရှိသော event မှ အချိန်ဖြစ်မည်ဖြစ်သည်။