- Importieren von Ergebnissen in SOF-ELK (Elastic Stack)
- SOF-ELK installieren und starten
- SOF-ELK aktualisieren!
- Hayabusa ausführen
- Optional: Löschen alter importierter Daten
- Die Hayabusa-Logstash-Konfigurationsdatei in SOF-ELK konfigurieren
- Hayabusa-Ergebnisse in SOF-ELK importieren
- Überprüfen, ob der Import in Kibana funktioniert hat
- Ergebnisse in Discover anzeigen
- Ergebnisse analysieren
- Zukünftige Pläne
Importieren von Ergebnissen in SOF-ELK (Elastic Stack)¶
SOF-ELK installieren und starten¶
Hayabusa-Ergebnisse können einfach in Elastic Stack importiert werden. Wir empfehlen die Verwendung von SOF-ELK, einer kostenlosen Elastic-Stack-Linux-Distribution, die auf DFIR-Untersuchungen ausgerichtet ist.
Laden Sie zunächst das SOF-ELK 7-Zip-VMware-Image von https://github.com/philhagen/sof-elk/wiki/Virtual-Machine-README herunter und entpacken Sie es.
Es gibt zwei Versionen, x86 für Intel-CPUs und eine ARM-Version für Apple-Computer der M-Serie.
Wenn Sie die VM starten, erhalten Sie einen Bildschirm, der diesem ähnelt:
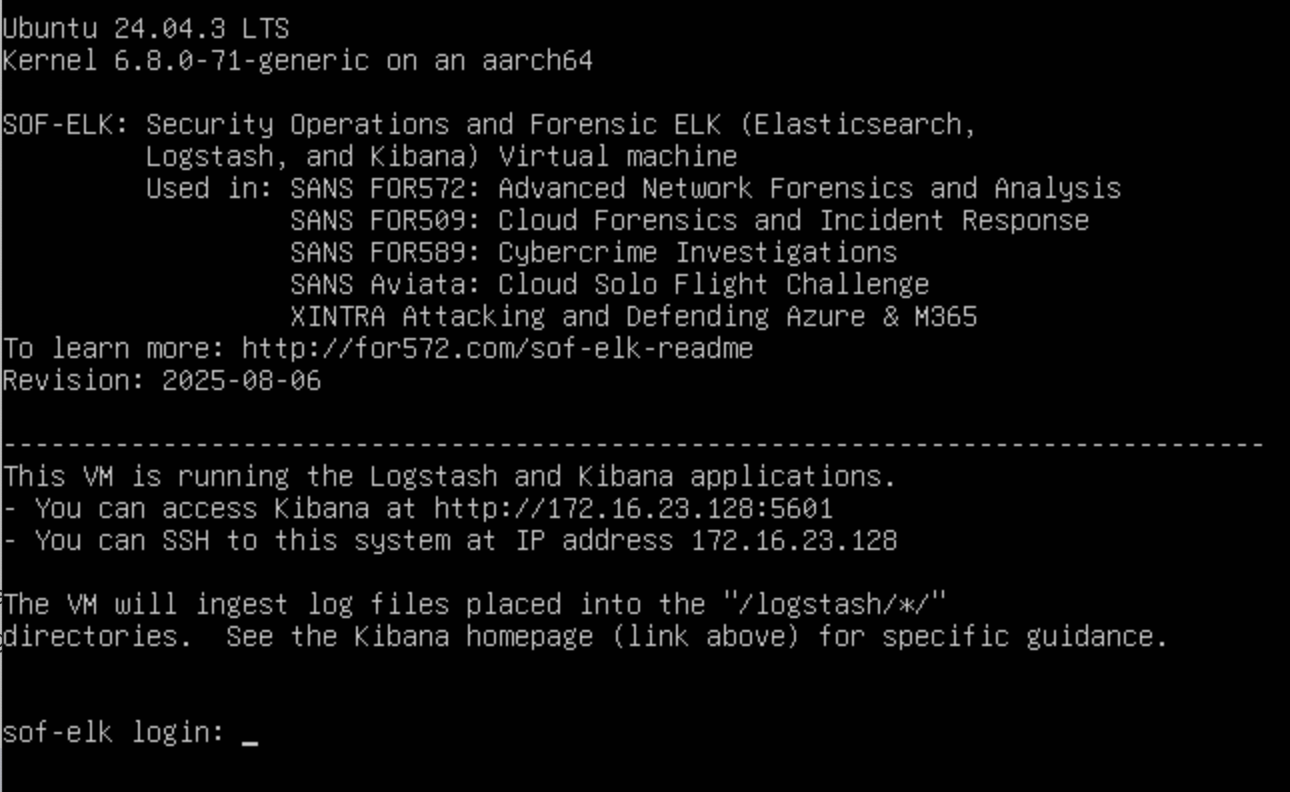
Notieren Sie sich die Kibana-URL und die IP-Adresse des SSH-Servers.
Sie können sich mit den folgenden Anmeldedaten anmelden:
- Benutzername:
elk_user - Passwort:
forensics
Öffnen Sie Kibana in einem Webbrowser entsprechend der angezeigten URL. Zum Beispiel: http://172.16.23.128:5601/
Hinweis: Es kann eine Weile dauern, bis Kibana geladen ist.
Sie sollten eine Webseite wie die folgende sehen:
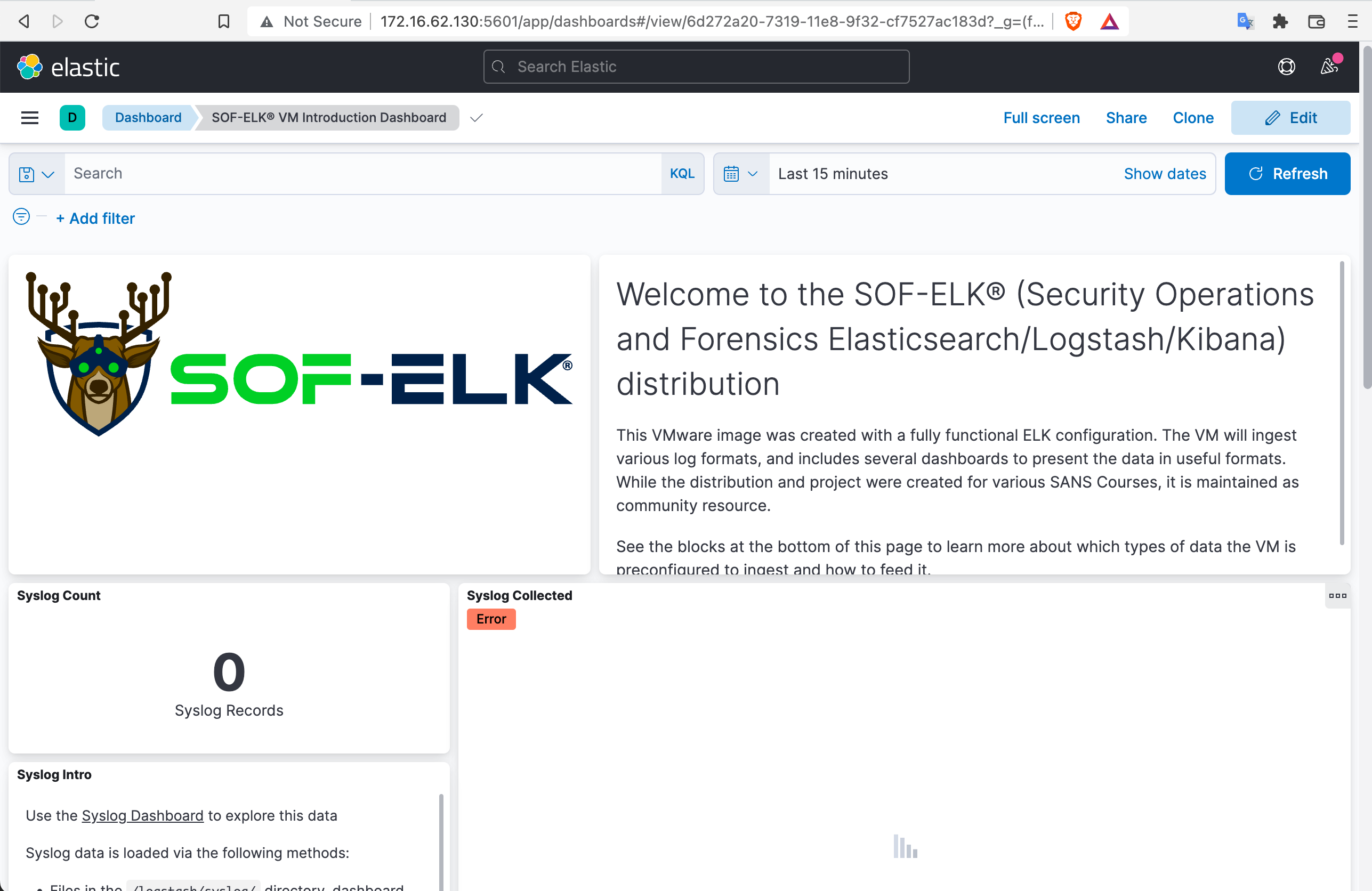
Wir empfehlen, sich per SSH mit der VM zu verbinden, anstatt Befehle innerhalb der VM mit ssh elk_user@172.16.23.128 einzugeben.
Hinweis: Das Standard-Tastaturlayout ist die US-Tastatur.
Probleme mit der Netzwerkverbindung auf Macs¶
Wenn Sie macOS verwenden und im Terminal einen no route to host-Fehler erhalten oder nicht auf Kibana in Ihrem Browser zugreifen können, liegt dies wahrscheinlich an den Datenschutzeinstellungen für lokale Netzwerke von macOS.
Öffnen Sie in den System Settings die Einstellungen Privacy & Security -> Local Network und stellen Sie sicher, dass Ihr Browser und Ihr Terminalprogramm aktiviert sind, um mit Geräten in Ihrem lokalen Netzwerk kommunizieren zu können.
SOF-ELK aktualisieren!¶
Bevor Sie Daten importieren, stellen Sie sicher, dass Sie SOF-ELK mit dem Befehl sudo sof-elk_update.sh aktualisieren.
Hayabusa ausführen¶
Führen Sie Hayabusa aus und speichern Sie die Ergebnisse im JSONL-Format.
Bsp.: ./hayabusa json-timeline -L -d ../hayabusa-sample-evtx -w -p super-verbose -G /opt/homebrew/var/GeoIP -o results.jsonl
Optional: Löschen alter importierter Daten¶
Wenn dies nicht das erste Mal ist, dass Sie Hayabusa-Ergebnisse importieren, und Sie alles bereinigen möchten, können Sie dies wie folgt tun:
- Überprüfen Sie, welche Datensätze sich derzeit in SOF-ELK befinden:
sof-elk_clear.py -i list - Löschen Sie die aktuellen Daten:
sof-elk_clear.py -a - Löschen Sie die Dateien im Logstash-Verzeichnis:
rm /logstash/hayabusa/*
Die Hayabusa-Logstash-Konfigurationsdatei in SOF-ELK konfigurieren¶
In SOF-ELK ist bereits eine Hayabusa-Logstash-Konfigurationsdatei enthalten, die Feldnamen in das Elastic-Common-Schema-Format umwandelt. Wenn Sie mit Hayabusa-Feldnamen besser vertraut sind, empfehlen wir die Verwendung der von uns bereitgestellten Datei.
- Verbinden Sie sich zunächst per SSH mit SOF-ELK:
ssh elk_user@172.16.23.128 - Löschen oder verschieben Sie die aktuelle Logstash-Konfigurationsdatei:
sudo rm /etc/logstash/conf.d/6650-hayabusa.conf - Laden Sie die neue Datei 6650-hayabusa-jsonl.conf nach
/etc/logstash/conf.d/hoch:sudo wget https://raw.githubusercontent.com/Yamato-Security/hayabusa/main/doc/ElasticStackImport/6650-hayabusa-jsonl.conf -O /etc/logstash/conf.d/6650-hayabusa.conf. - Starten Sie Logstash neu:
sudo systemctl restart logstash
Diese Konfigurationsdatei erstellt konsolidierte DetailsText- und ExtraFieldInfoText-Felder, mit denen Sie die wichtigsten Felder schnell auf einen Blick sehen können, anstatt jeden Datensatz einzeln öffnen zu müssen, um alle Felder durchzusehen.
Hayabusa-Ergebnisse in SOF-ELK importieren¶
Logs werden in SOF-ELK aufgenommen, indem die Logs in das entsprechende Verzeichnis innerhalb des Verzeichnisses /logstash kopiert werden.
exiten Sie zunächst aus SSH und kopieren Sie dann die von Ihnen erstellte Hayabusa-Ergebnisdatei:
scp ./results.jsonl elk_user@172.16.23.128:/logstash/hayabusa
Überprüfen, ob der Import in Kibana funktioniert hat¶
Notieren Sie sich zunächst die Werte Total detections, First Timestamp und Last Timestamp in der Results Summary Ihres Hayabusa-Scans.
Wenn Sie diese Informationen nicht erhalten können, können Sie unter *nix wc -l results.jsonl ausführen, um die Gesamtzeilenzahl für Total detections zu erhalten.
Standardmäßig sortiert Hayabusa die Ergebnisse nicht, um die Leistung zu verbessern, sodass Sie nicht die erste und letzte Zeile betrachten können, um den ersten und letzten Zeitstempel zu erhalten.
Wenn Sie die genauen ersten und letzten Zeitstempel nicht kennen, setzen Sie einfach das erste Datum in Kibana auf das Jahr 2007 und den letzten Tag auf now, damit Sie alle Ergebnisse haben.
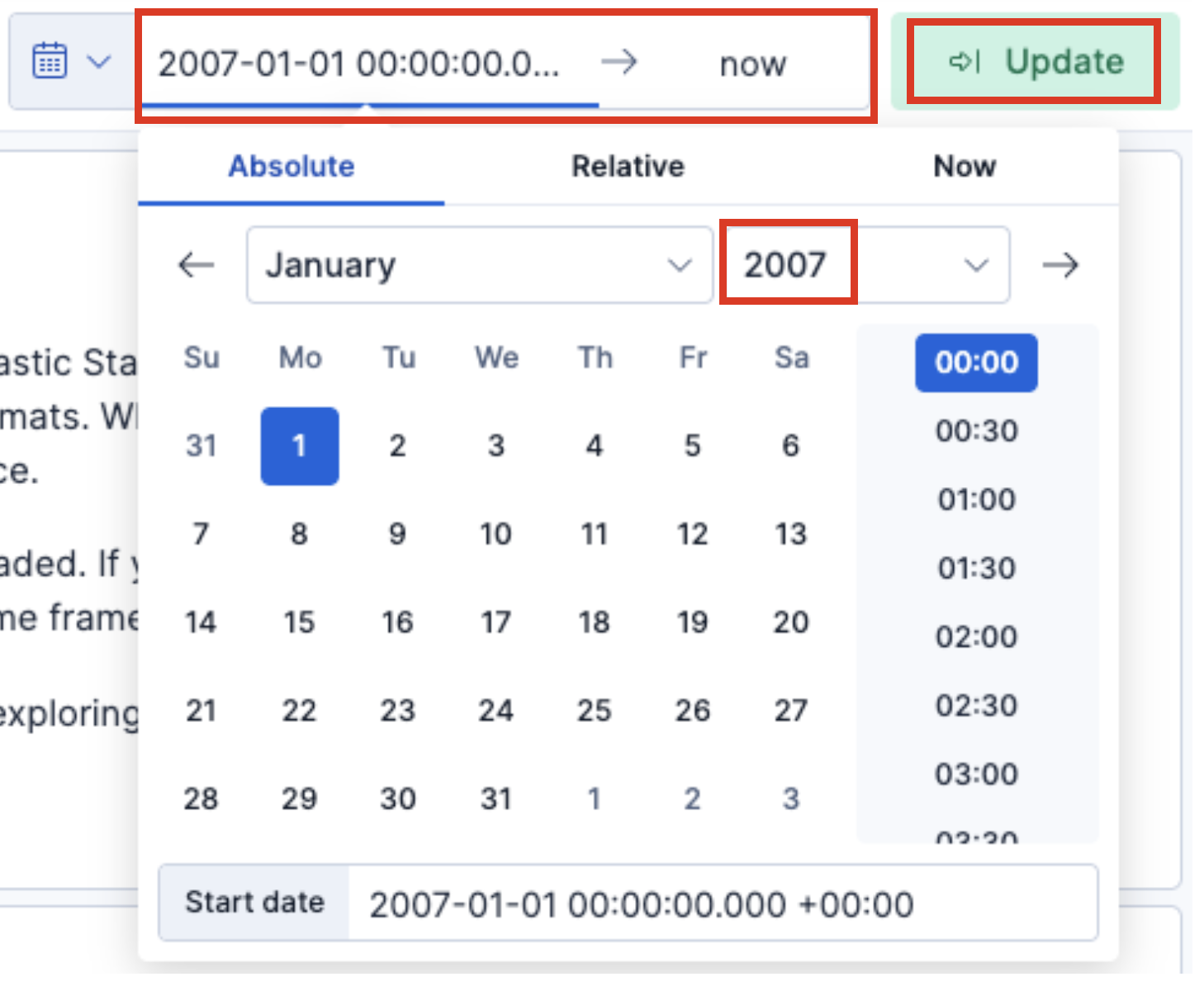
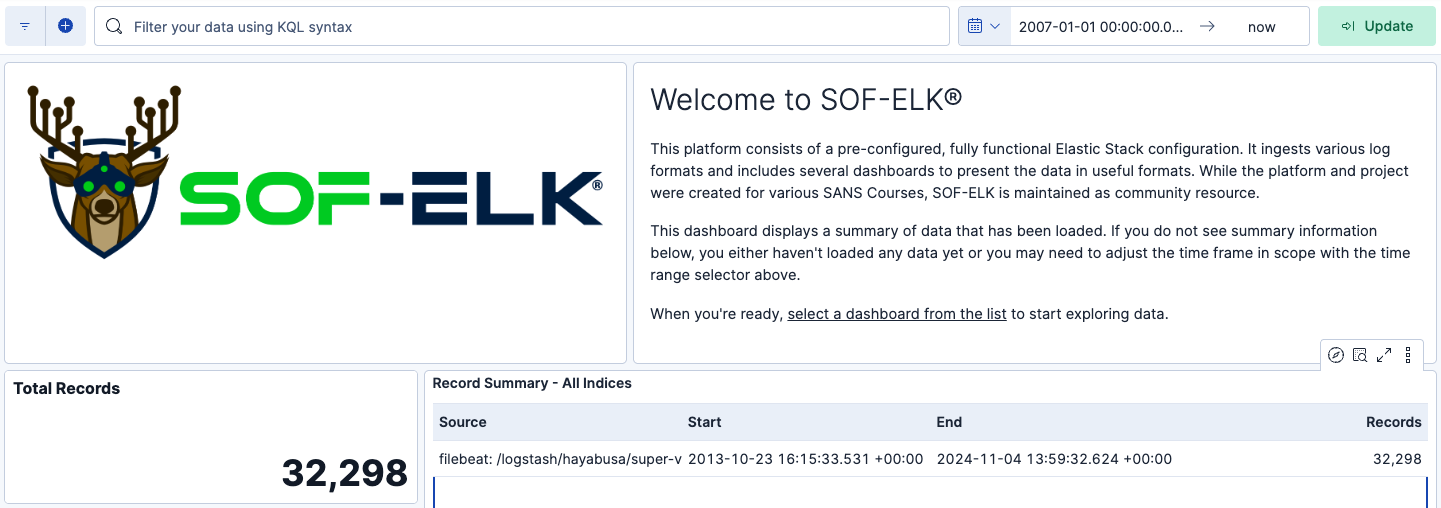
Sie sollten nun die Total Records sowie den ersten und letzten Zeitstempel der importierten Ereignisse sehen.
Manchmal dauert es eine Weile, alle Ereignisse zu importieren, aktualisieren Sie also einfach die Seite immer wieder, bis die Total Records die von Ihnen erwartete Anzahl erreichen.
Sie können dies auch vom Terminal aus überprüfen, indem Sie sof-elk_clear.py -i list ausführen, um zu sehen, ob der Import erfolgreich war.
Sie sollten sehen, dass Ihr evtxlogs-Index mehr Datensätze haben sollte:
Bitte erstellen Sie ein Issue auf GitHub, wenn beim Importieren Parsing-Fehler auftreten.
Sie können dies überprüfen, indem Sie sich das Ende der Logdatei /var/log/logstash/logstash-plain.log ansehen.
Ergebnisse in Discover anzeigen¶
Klicken Sie auf das Sidebar-Symbol oben links und klicken Sie auf Discover:
Sie werden wahrscheinlich No results match your search criteria sehen.
Klicken Sie in der oberen linken Ecke, wo logstash-*-Index steht, darauf und ändern Sie es in evtxlogs-*.
Sie sollten nun die Discover-Timeline sehen.
Ergebnisse analysieren¶
Die Standardansicht von Discover sollte ähnlich wie diese aussehen:
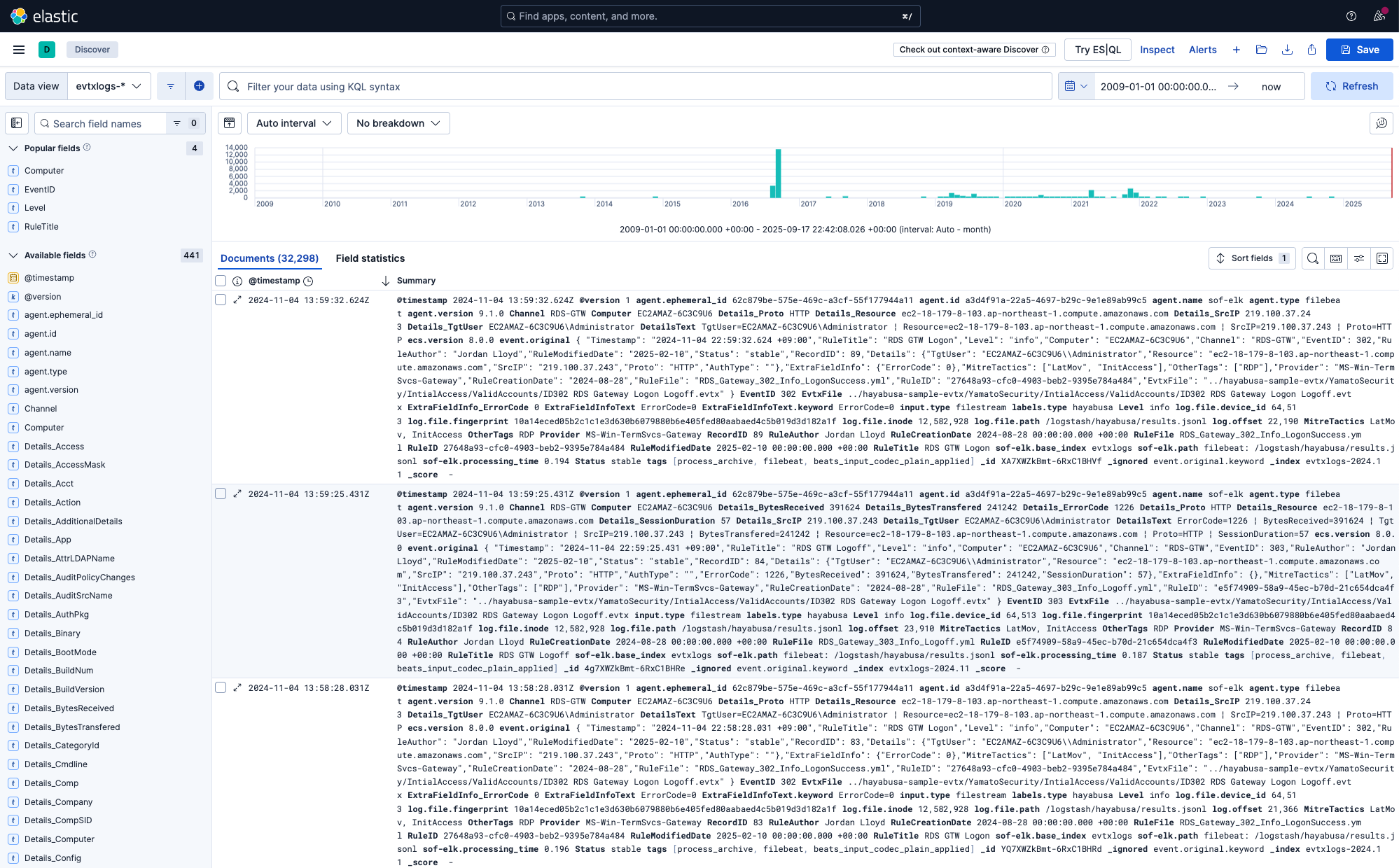
Sie können sich einen Überblick darüber verschaffen, wann die Ereignisse aufgetreten sind und wie häufig sie sind, indem Sie sich das Histogramm oben ansehen.
Spalten hinzufügen¶
In der linken Seitenleiste können Sie Felder hinzufügen, die Sie in den Spalten anzeigen möchten, indem Sie auf das Pluszeichen klicken, nachdem Sie mit dem Mauszeiger über ein Feld gefahren sind. Da es viele Felder gibt, möchten Sie vielleicht den Namen des gesuchten Feldnamens in das Suchfeld eingeben.
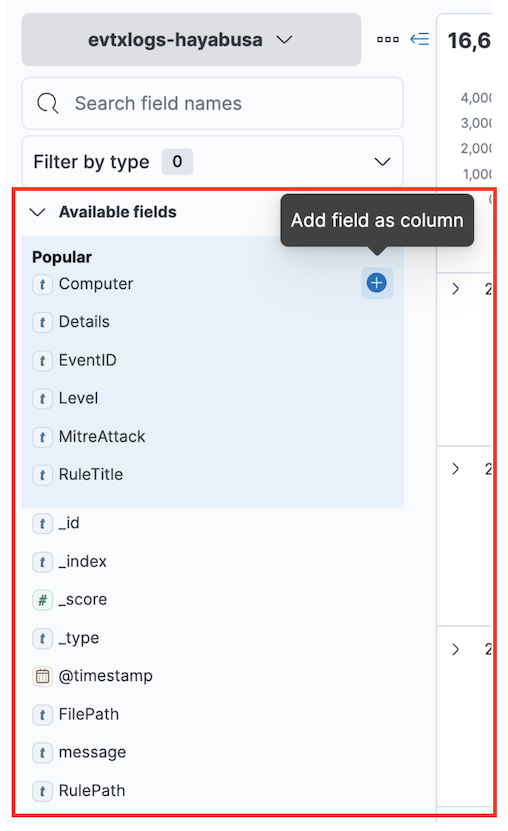
Für den Anfang empfehlen wir die folgenden Spalten:
ComputerEventIDLevelRuleTitleDetailsText
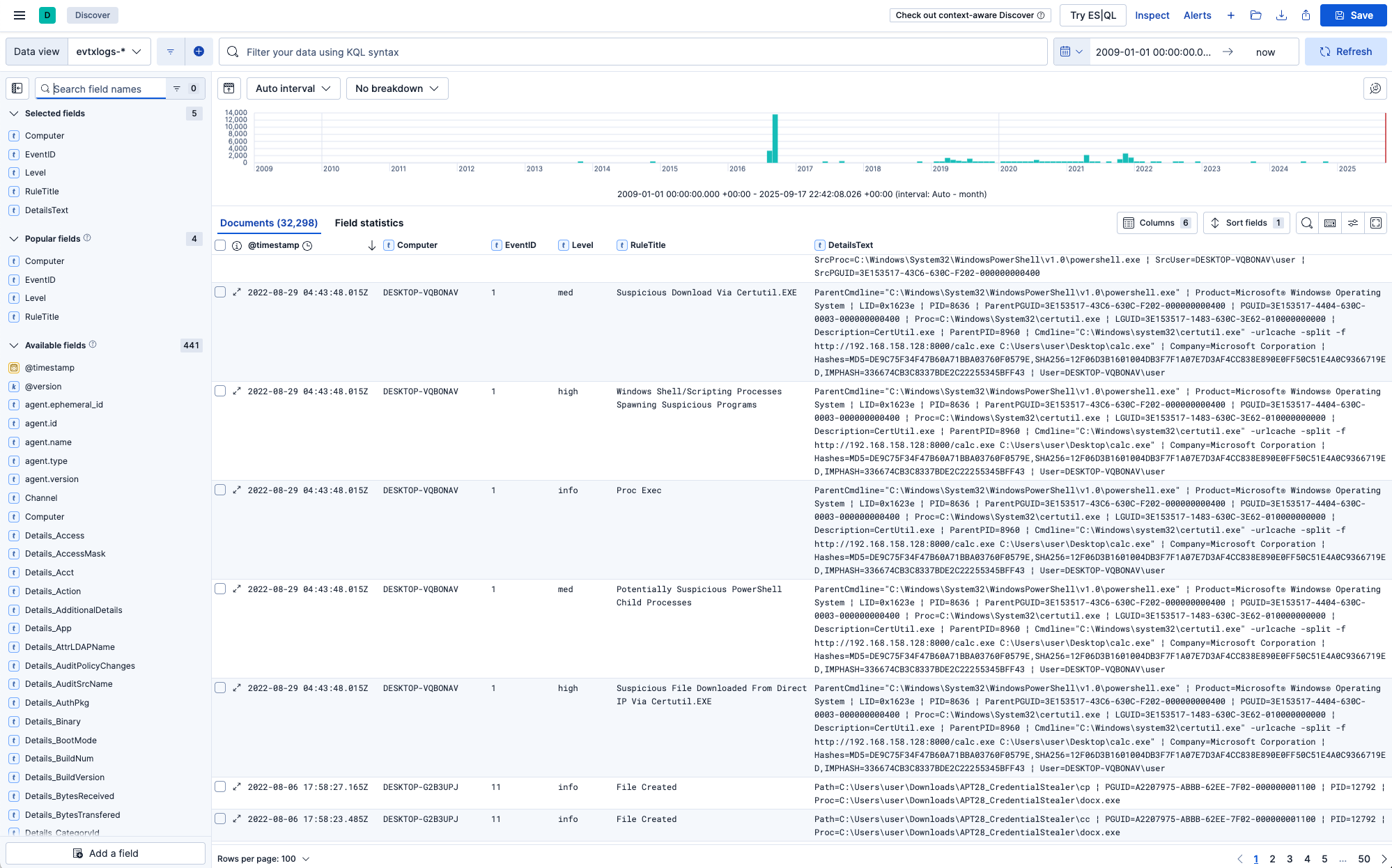
Wenn Ihr Monitor breit genug ist, möchten Sie vielleicht auch ExtraFieldInfoText hinzufügen, damit Sie alle Feldinformationen sehen.
Ihre Discover-Ansicht sollte nun wie folgt aussehen:
Filtern¶
Sie können mit KQL (Kibana Query Language) filtern, um nach bestimmten Ereignissen und Warnungen zu suchen. Zum Beispiel:
* Level: "crit": Nur kritische Warnungen anzeigen.
* Level: "crit" OR Level: "high": Hohe und kritische Warnungen anzeigen.
* NOT Level: info: Keine informativen Ereignisse anzeigen, nur Warnungen.
* MitreTactics: *LatMov*: Ereignisse und Warnungen im Zusammenhang mit Lateral Movement anzeigen.
* "PW Spray": Nur bestimmte Angriffe wie "Password Spray" anzeigen.
* "LID: 0x8724ead": Alle Aktivitäten anzeigen, die mit der Logon-ID 0x8724ead verbunden sind.
* Details_TgtUser: admmig: Nach allen Ereignissen suchen, bei denen der Zielbenutzer admmig ist.
Details umschalten¶
Um alle Felder in einem Datensatz zu überprüfen, klicken Sie einfach auf das Symbol (Toggle dialog with details) neben dem Zeitstempel:
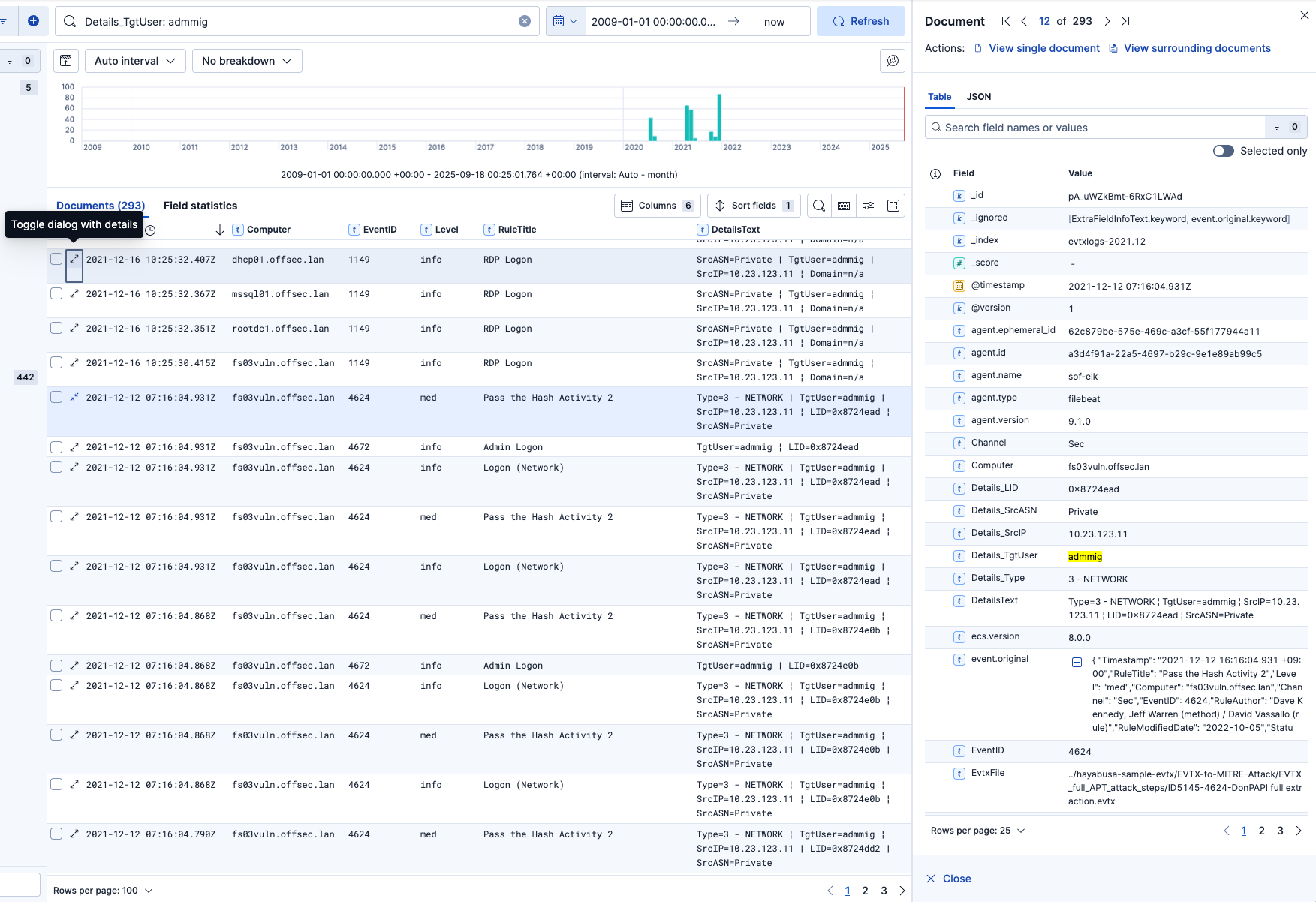
Umgebende Dokumente anzeigen¶
Wenn Sie die Ereignisse direkt vor und nach einer bestimmten Warnung anzeigen möchten, öffnen Sie zunächst die Details dieser Warnung und klicken Sie dann oben rechts auf View surrounding documents:
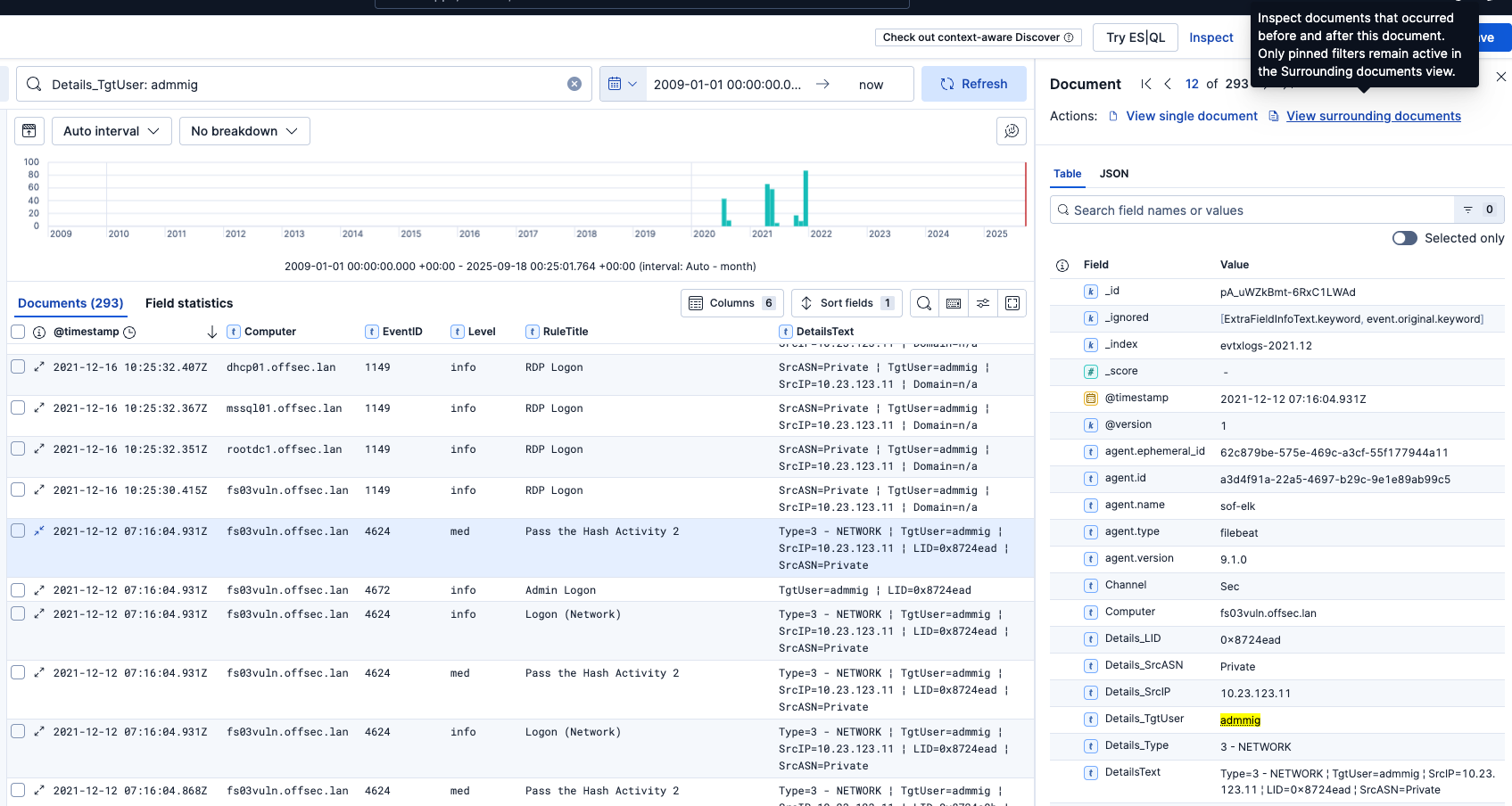
In diesem Beispiel sehen wir die Ereignisse vor und nach der Warnung zum Pass-the-Hash-Angriff:
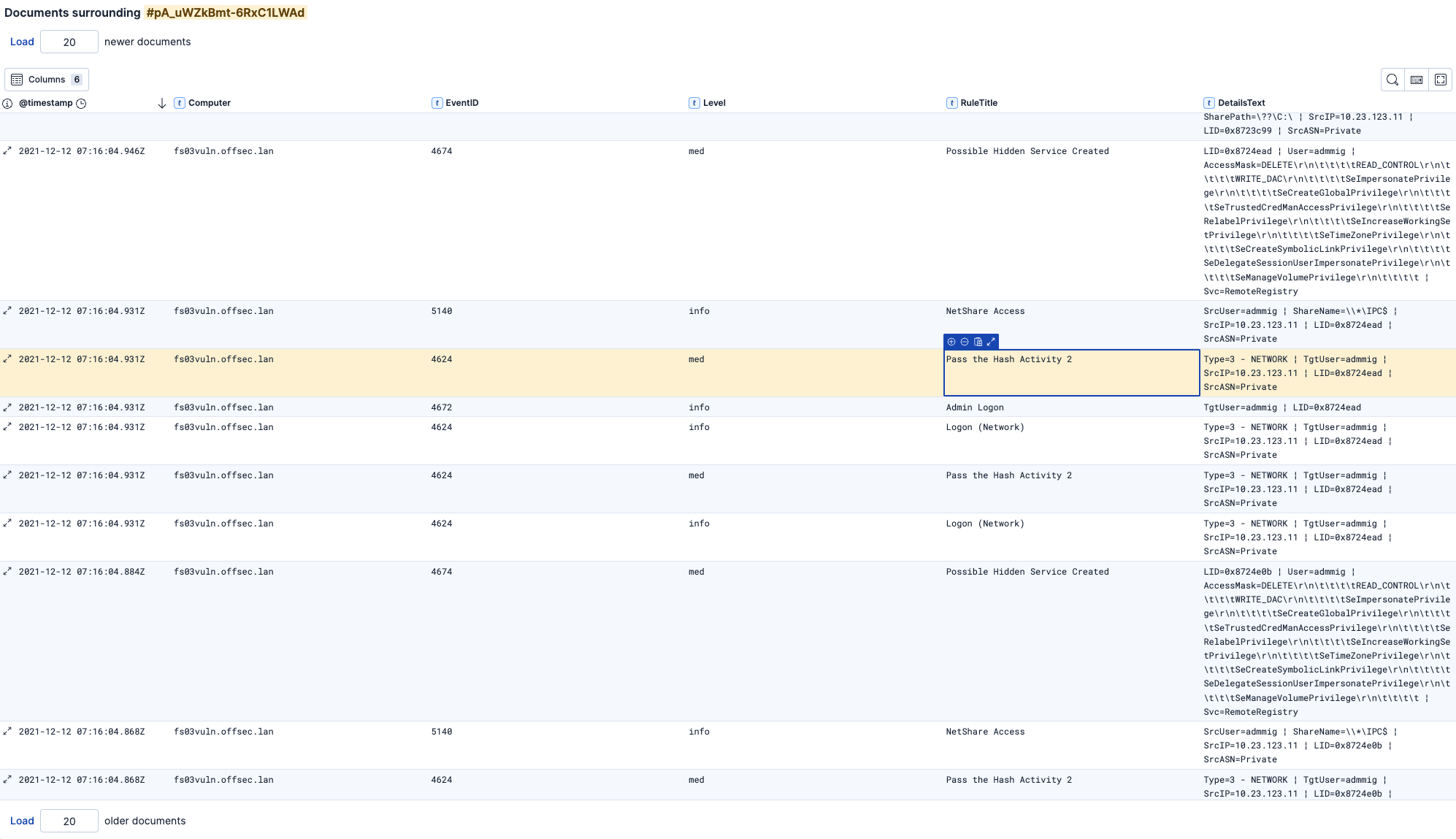
Hinweis: Ändern Sie die Zahlen oben
Load x newer documentsoder untenLoad x older documents, um mehr Ereignisse abzurufen.
Schnelle Metriken zu Feldern abrufen¶
Wenn Sie in der linken Spalte auf einen Feldnamen klicken, erhalten Sie schnelle Metriken zu seiner Verwendung:
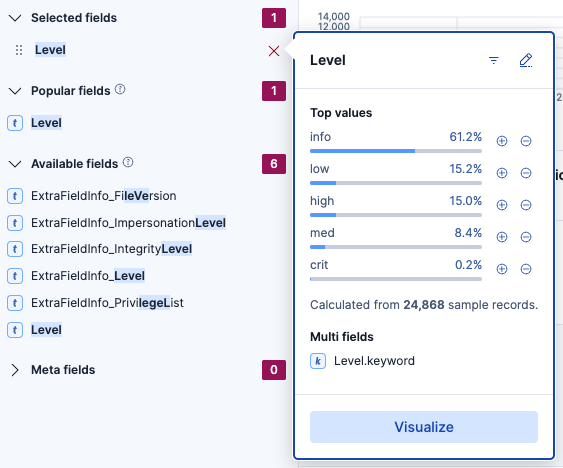
Beachten Sie, dass die Daten zur Geschwindigkeit gesampelt werden und daher nicht zu 100 % genau sind.
Zukünftige Pläne¶
- Logstash-Parser für CSV
- Vorgefertigtes Dashboard