Rust-Performance-Leitfaden für Hayabusa-Entwickler¶
Autor¶
Fukusuke Takahashi
Englische Übersetzung¶
Zach Mathis (@yamatosecurity)
Über dieses Dokument¶
Hayabusa (Englisch: "peregrine falcon", deutsch: "Wanderfalke") ist ein schnelles Forensik-Analysewerkzeug, das von der Gruppe Yamato Security in Japan entwickelt wird. Es wird in Rust entwickelt, um (Bedrohungen) so schnell wie ein Wanderfalke aufzuspüren. Rust ist an sich eine schnelle Sprache, doch es gibt viele Fallstricke, die zu langsamer Geschwindigkeit und hohem Speicherverbrauch führen können. Wir haben dieses Dokument auf Grundlage tatsächlicher Performance-Verbesserungen in Hayabusa erstellt (siehe das Changelog hier), aber diese Techniken sollten auch auf andere Rust-Programme anwendbar sein. Wir hoffen, dass Sie von dem Wissen profitieren können, das wir durch unsere Versuche und Fehler gewonnen haben.
Geschwindigkeitsverbesserung¶
Den Speicher-Allocator ändern¶
Allein das Ändern des standardmäßigen Speicher-Allocators kann die Geschwindigkeit erheblich verbessern. Laut diesen Benchmarks sind beispielsweise die folgenden beiden Speicher-Allocatoren
deutlich schneller als der standardmäßige Speicher-Allocator. Wir konnten eine erhebliche Geschwindigkeitsverbesserung feststellen, indem wir unseren Speicher-Allocator von jemalloc auf mimalloc umgestellt haben, daher haben wir mimalloc seit Version 1.8.0 zum Standard gemacht. (Allerdings verbraucht mimalloc etwas mehr Speicher als jemalloc.)
Vorher ¶
Nachher ¶
Sie müssen nur die folgenden 2 Schritte ausführen, um den globalen Speicher-Allocator zu ändern:
- Fügen Sie das mimalloc-Crate zum [dependencies]-Abschnitt der Datei
Cargo.tomlhinzu: - Legen Sie unter #[global_allocator] irgendwo im Programm fest, dass Sie mimalloc verwenden möchten: Mehr müssen Sie nicht tun, um den Speicher-Allocator zu ändern.
Wirksamkeit(Reales Beispiel aus einem Pull Request) ¶
Wie stark sich die Geschwindigkeit verbessert, hängt vom Programm ab, aber im folgenden Beispiel
führte das Ändern des Speicher-Allocators auf mimalloc zu einer Performance-Steigerung von 20-30 % auf Intel-CPUs. (Aus irgendeinem Grund gab es auf ARM-basierten macOS-Geräten keine so deutliche Performance-Steigerung.)
IO-Verarbeitung in Schleifen reduzieren¶
Festplatten-IO-Verarbeitung ist viel langsamer als Verarbeitung im Speicher. Daher ist es wünschenswert, IO-Verarbeitung so weit wie möglich zu vermeiden, insbesondere in Schleifen.
Vorher ¶
Das Beispiel unten zeigt, wie ein Datei-Öffnen eine Million Mal in einer Schleife auftritt:
use std::fs;
fn main() {
for _ in 0..1000000 {
let f = fs::read_to_string("sample.txt").unwrap();
f.len();
}
}
Nachher ¶
Indem die Datei wie folgt außerhalb der Schleife geöffnet wird
use std::fs;
fn main() {
let f = fs::read_to_string("sample.txt").unwrap();
for _ in 0..1000000 {
f.len();
}
}
Wirksamkeit(Reales Beispiel aus einem Pull Request) ¶
Im folgenden Beispiel konnte die IO-Verarbeitung bei der Behandlung eines Erkennungsergebnisses nach dem anderen außerhalb der Schleife durchgeführt werden:
Dies führte zu einer Geschwindigkeitsverbesserung von etwa 20 %.
Kompilierung regulärer Ausdrücke in Schleifen vermeiden¶
Die Kompilierung regulärer Ausdrücke ist im Vergleich zum Abgleich regulärer Ausdrücke ein sehr kostspieliger Vorgang. Daher ist es ratsam, die Kompilierung regulärer Ausdrücke so weit wie möglich zu vermeiden, insbesondere in Schleifen.
Vorher ¶
Der folgende Vorgang erzeugt zum Beispiel 100.000 Versuche, einen regulären Ausdruck in einer Schleife abzugleichen:
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..100000 {
if Regex::new(match_str).unwrap().is_match(text){ // Regular expression compilation in a loop
println!("matched!");
}
}
}
Nachher ¶
Indem die Kompilierung des regulären Ausdrucks außerhalb der Schleife durchgeführt wird, wie unten gezeigt
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap(); // Compile the regular expression outside the loop
for _ in 0..100000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Wirksamkeit(Reales Beispiel aus einem Pull Request) ¶
Im folgenden Beispiel wird die Kompilierung des regulären Ausdrucks außerhalb der Schleife durchgeführt und zwischengespeichert.
Dies führte zu erheblichen Geschwindigkeitsverbesserungen.
Buffer-IO verwenden¶
Ohne Buffer-IO ist Datei-IO langsam. Mit Buffer-IO werden IO-Operationen über Puffer im Speicher durchgeführt, wodurch die Anzahl der Systemaufrufe reduziert und die Geschwindigkeit verbessert wird.
Vorher ¶
Im folgenden Vorgang tritt zum Beispiel write 1.000.000 Mal auf.
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
for _ in 0..1000000 {
f.write(b"hello world!");
}
}
Nachher ¶
Durch die Verwendung von BufWriter wie folgt
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
let mut writer = BufWriter::new(f);
for _ in 0..1000000 {
writer.write(b"some text");
}
writer.flush().unwrap();
}
Wirksamkeit(Reales Beispiel aus einem Pull Request) ¶
Die oben beschriebene Methode wurde hier implementiert
und hat zu erheblichen Geschwindigkeitsverbesserungen bei der Ausgabeverarbeitung geführt.
Standard-String-Methoden anstelle von regulären Ausdrücken verwenden¶
Während reguläre Ausdrücke komplexe Abgleichsmuster abdecken können, sind sie langsamer als Standard-String-Methoden. Daher ist es schneller, für einfache String-Abgleiche wie die folgenden Standard-String-Methoden zu verwenden.
- Starts-with-Abgleich(Regex:
foo.*)-> String::starts_with() - Ends-with-Abgleich(Regex:
.*foo)-> String::ends_with() - Contains-Abgleich(Regex:
.*foo.*)-> String::contains()
Vorher ¶
Der folgende Code führt zum Beispiel eine Million Mal einen Ends-with-Abgleich mit einem regulären Ausdruck durch.
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = ".*abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Nachher ¶
Durch die Verwendung von String::ends_with() wie folgt
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..1000000 {
if text.ends_with(match_str) {
println!("matched!");
}
}
}
Wirksamkeit(Reales Beispiel aus einem Pull Request) ¶
Da Hayabusa einen Groß-/Kleinschreibung-unabhängigen String-Vergleich benötigt, verwenden wir to_lowercase() und wenden dann die obige Methode an. Selbst dann hat sich in den folgenden Beispielen
- Imporving speed by changing wildcard search process from regular expression match to starts_with/ends_with match #890
- Improving speed by using eq_ignore_ascii_case() before regular expression match #884
die Geschwindigkeit im Vergleich zu vorher um etwa 15 % verbessert.
Nach String-Länge filtern¶
Je nach den Eigenschaften der verarbeiteten Strings kann das Hinzufügen eines einfachen Filters die Anzahl der String-Abgleichsversuche reduzieren und den Vorgang beschleunigen. Wenn Sie häufig Strings mit nicht festgelegter und nicht übereinstimmender String-Länge vergleichen, können Sie den Vorgang beschleunigen, indem Sie die String-Länge als primären Filter verwenden.
Vorher ¶
Der folgende Code versucht zum Beispiel eine Million Abgleiche regulärer Ausdrücke.
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Nachher ¶
Durch die Verwendung von String::len() als primären Filter, wie unten gezeigt
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if text.len() == match_str.len() { // Primary filter by string length
if r.is_match(text) {
println!("matched!");
}
}
}
}
Wirksamkeit(Reales Beispiel aus einem Pull Request) ¶
Im folgenden Beispiel wird die obige Methode verwendet.
Dies verbesserte die Geschwindigkeit um etwa 15 %.
Nicht mit codegen-units=1 kompilieren¶
Viele Artikel über Performance-Optimierung mit Rust raten dazu, codegen-units = 1 unter dem Abschnitt [profile.release] hinzuzufügen.
Dies führt zu langsameren Kompilierungszeiten, da standardmäßig parallel kompiliert wird, sollte aber theoretisch zu optimierterem und schnellerem Code führen.
In unseren Tests läuft Hayabusa mit dieser aktivierten Option jedoch tatsächlich langsamer und die Kompilierung dauert länger, daher lassen wir dies deaktiviert.
Die Binärgröße der ausführbaren Datei ist etwa 100 kb kleiner, daher kann dies für eingebettete Systeme ideal sein, bei denen der Festplattenspeicher begrenzt ist.
Speicherverbrauch reduzieren¶
Unnötige Verwendung von clone(), to_string() und to_owned() vermeiden¶
Die Verwendung von clone() oder to_string() ist eine einfache Möglichkeit, Kompilierungsfehler im Zusammenhang mit Ownership zu beheben. Sie führen jedoch in der Regel zu hohem Speicherverbrauch und sollten vermieden werden. Es ist immer am besten, zuerst zu prüfen, ob Sie sie durch kostengünstige Referenzen ersetzen können.
Vorher ¶
Wenn Sie zum Beispiel über denselben Vec mehrmals iterieren möchten, können Sie clone() verwenden, um Kompilierungsfehler zu beseitigen.
fn main() {
let lst = vec![1, 2, 3];
for x in lst.clone() { // In order to eliminate compile errors
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
Nachher ¶
Durch die Verwendung von Referenzen, wie unten gezeigt, können Sie jedoch die Notwendigkeit beseitigen, clone() zu verwenden.
fn main() {
let lst = vec![1, 2, 3];
for x in &lst { // Eliminate compile errors with a reference
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
Wirksamkeit(Reales Beispiel aus einem Pull Request) ¶
Im folgenden Beispiel konnten wir durch das Ersetzen der unnötigen Verwendung von clone(), to_string() und to_owned(),
den Speicherverbrauch erheblich reduzieren.
Iterator anstelle von Vec verwenden¶
Vec hält alle Elemente im Speicher, daher verbraucht es viel Speicher proportional zur Anzahl der Elemente. Wenn die Verarbeitung eines Elements nach dem anderen ausreicht, verbraucht die Verwendung eines Iterators stattdessen viel weniger Speicher.
Vorher ¶
Die folgende Funktion return_lines() liest zum Beispiel eine Datei von etwa 1 GB und gibt einen Vec zurück:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> Vec<String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
.collect()
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
Nachher ¶
Stattdessen sollten Sie wie folgt einen Iterator-Trait zurückgeben:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> impl Iterator<Item=String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
// ここでcollect()せずに、Iteratorを戻り値として返す
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
Box<dyn Iterator<Item = T>> zurückgeben:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines(need_filter:bool) -> Box<dyn Iterator<Item = String>> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
if need_filter {
let result= buf.lines()
.filter_map(|l| l.ok())
.map(|l| l.replace("A", "B"));
return Box::new(result)
}
let result= buf.lines()
.map(|l| l.expect("Could not parse line"));
Box::new(result)
}
fn main() {
let lines = return_lines(true);
for line in lines {
println!("{}", line)
}
}
Wirksamkeit(Reales Beispiel aus einem Pull Request) ¶
Das folgende Beispiel verwendet die oben beschriebene Methode:
Beim Test mit einer 1,7 GB großen JSON-Datei verringerte sich der Speicher um 75 %.
Das compact_str-Crate beim Umgang mit kurzen Strings verwenden¶
Beim Umgang mit einer großen Anzahl kurzer Strings von weniger als 24 Byte kann das compact_str-Crate verwendet werden, um den Speicherverbrauch zu reduzieren.
Vorher ¶
Im Beispiel unten enthält der Vec 10 Millionen Strings.
fn main() {
let v: Vec<String> = vec![String::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
Nachher ¶
Es ist besser, sie durch einen CompactString zu ersetzen:
use compact_str::CompactString;
fn main() {
let v: Vec<CompactString> = vec![CompactString::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
Wirksamkeit(Reales Beispiel aus einem Pull Request) ¶
Im folgenden Beispiel werden kurze Strings mit CompactString behandelt:
Dies ergab eine Reduzierung des Speicherverbrauchs um etwa 20 %.
Unnötige Felder in langlebigen Strukturen löschen¶
Strukturen, die während des Prozessstarts weiterhin im Speicher gehalten werden, können den gesamten Speicherverbrauch beeinflussen. In Hayabusa werden insbesondere die folgenden Strukturen (Stand Version 2.2.2) in großer Zahl gehalten.
Das Entfernen von Feldern, die mit den obigen Strukturen verbunden sind, hatte einen gewissen Effekt auf die Reduzierung des gesamten Speicherverbrauchs.
Vorher ¶
Das Feld DetectInfo war zum Beispiel bis Version 1.8.1 wie folgt:
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
pub record_information: CompactString,
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
Nachher ¶
Durch das Löschen des Feldes record_information wie folgt
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
// remove record_information field
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
Wirksamkeit(Reales Beispiel aus einem Pull Request) ¶
Im folgenden Beispiel konnten wir beim Test gegen Daten, bei denen die Anzahl der Erkennungsergebnis-Datensätze etwa 1,5 Millionen betrug,
- Reduced memory usage of DetectInfo/EvtxRecordInfo #837
- Reduce memory usage by removing unnecessary regex #894
eine Reduzierung des Speicherverbrauchs um etwa 300 MB erreichen.
Benchmarking¶
Die Statistikfunktion des Speicher-Allocators verwenden.¶
Einige Speicher-Allocatoren führen ihre eigenen Speicherverbrauchsstatistiken. In mimalloc kann zum Beispiel die Funktion mi_stats_print_out() aufgerufen werden, um den Speicherverbrauch zu erhalten.
So erhalten Sie Statistiken ¶
Voraussetzungen: Sie müssen mimalloc verwenden, wie im Abschnitt Den Speicher-Allocator ändern erklärt.
- Fügen Sie im dependencies-Abschnitt von
Cargo.tomldas libmimalloc-sys-Crate hinzu: - Wann immer Sie die Speicherverbrauchsstatistiken ausgeben möchten, schreiben Sie den folgenden Code und rufen Sie innerhalb eines
unsafe-Blocks mi_stats_print_out() auf. Die Speicherverbrauchsstatistiken werden auf die Standardausgabe ausgegeben. -
Der Wert
peak/reservedoben links ist der maximale Speicherverbrauch.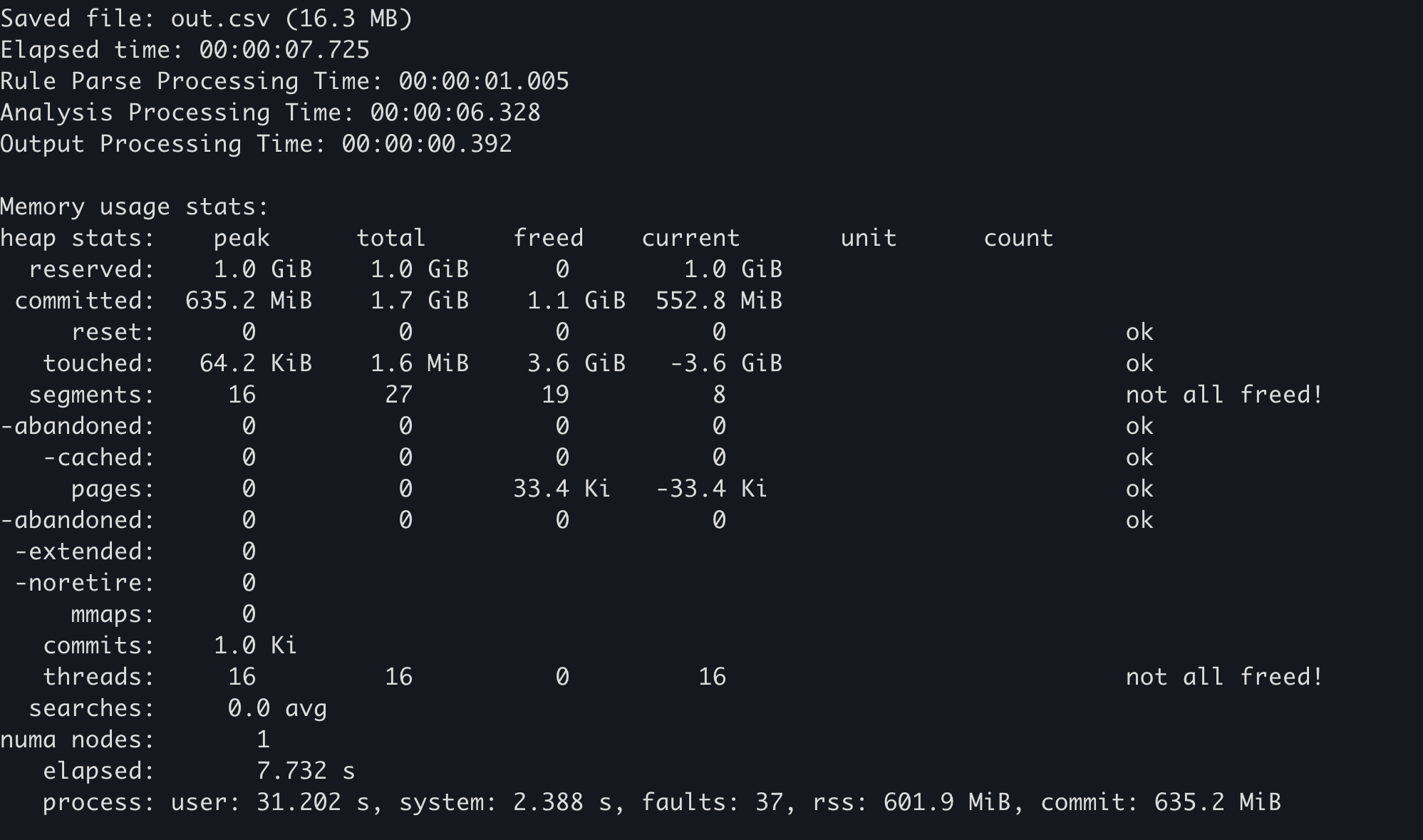
Beispiel ¶
Die obige Implementierung wurde im Folgenden angewendet:
Wenn Sie in Hayabusa die Option --debug hinzufügen, werden am Ende Speicherverbrauchsstatistiken ausgegeben.
Den Performance-Counter von Windows verwenden¶
Verschiedene Ressourcennutzungen können aus Statistiken überprüft werden, die auf der Betriebssystemseite erhalten werden können. In diesem Fall sind die folgenden zwei Punkte zu beachten.
- Einfluss durch Antivirensoftware (Windows Defender)
- Nur der erste Durchlauf wird vom Scan beeinflusst und ist langsamer, daher eignen sich Ergebnisse vom zweiten und folgenden Durchläufen nach dem Build für den Vergleich. (Oder Sie können Ihr Antivirenprogramm deaktivieren, um genauere Ergebnisse zu erhalten.)
- Einfluss durch Datei-Caching
- Die Ergebnisse vom zweiten und folgenden Mal nach dem Betriebssystemstart sind schneller als beim ersten Mal, weil evtx und andere Datei-IOs aus dem Datei-Cache im Speicher gelesen werden, daher sind die Ergebnisse vom ersten Mal nach dem Booten des Betriebssystems idealer für die Durchführung von Benchmarks.
So erhalten Sie ihn ¶
Voraussetzungen:Das folgende Verfahren ist nur für Umgebungen gültig, in denen PowerShell 7 bereits auf Windows installiert ist.
- Starten Sie das Betriebssystem neu
- Führen Sie den Get-Counter-Befehl von
PowerShell 7aus, der den Performance-Counter kontinuierlich jede Sekunde in eine CSV-Datei aufzeichnet. (Wenn Sie andere Ressourcen als die unten aufgeführten messen möchten, ist dieser Artikel eine gute Referenz.) - Führen Sie den Prozess aus, den Sie messen möchten.
Beispiel ¶
Das Folgende enthält ein Beispielverfahren zum Messen der Performance mit Hayabusa.
heaptrack verwenden¶
heaptrack ist ein ausgefeilter Speicher-Profiler, der für Linux und macOS verfügbar ist. Durch die Verwendung von heaptrack können Sie Engpässe gründlich untersuchen.
So erhalten Sie ihn ¶
Voraussetzungen: Unten ist das Verfahren für Ubuntu 22.04. Sie können heaptrack nicht auf Windows verwenden.
- Installieren Sie heaptrack mit den folgenden zwei Befehlen.
- Entfernen Sie den folgenden mimalloc-Code aus Hayabusa. (Sie können den Speicher-Profiler von heaptrack nicht mit mimalloc verwenden.
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L32-L33
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L59-L60
-
https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L632-L634
-
Löschen Sie den [profile.release]-Abschnitt in der Datei
Cargo.tomlvon Hayabusa und ändern Sie ihn wie folgt: -
Erstellen Sie einen Release-Build:
cargo build --release - Führen Sie
heaptrack hayabusa csv-timeline -d sample -o out.csvaus
Wenn Hayabusa nun mit der Ausführung fertig ist, werden die Ergebnisse von heaptrack automatisch in einer GUI-Anwendung geöffnet.
Beispiele ¶
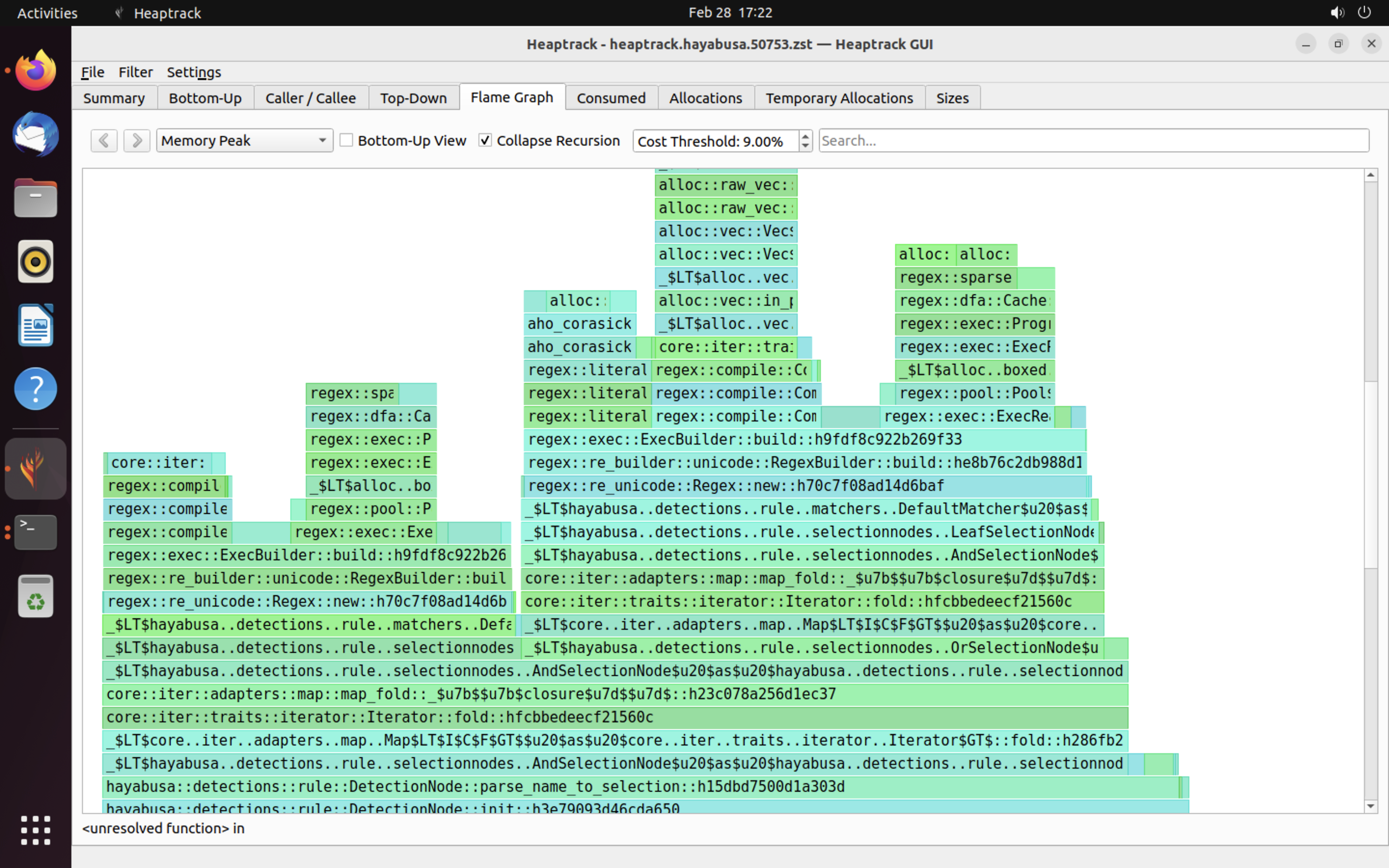
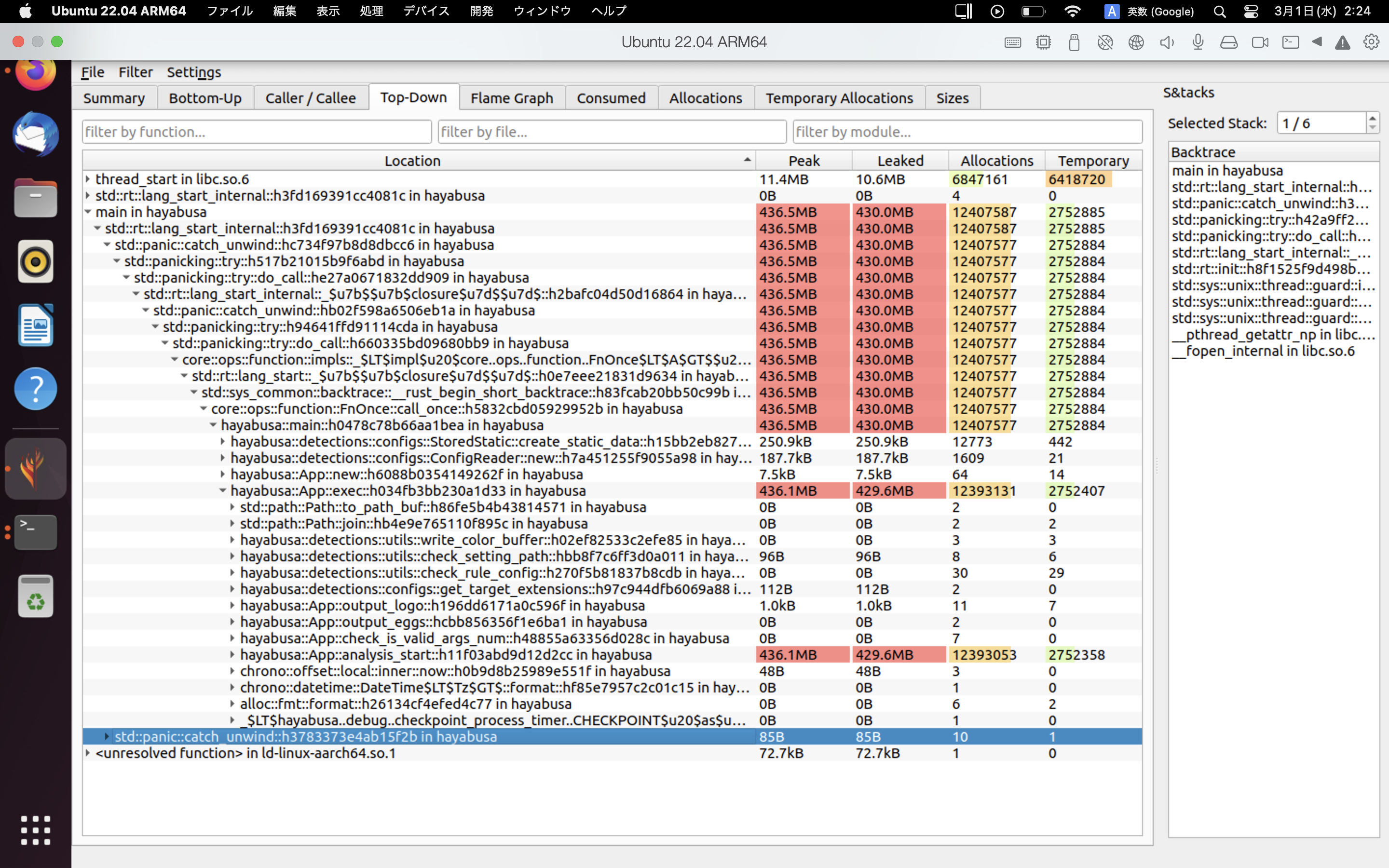
Ein Beispiel für die Ergebnisse von heaptrack wird unten gezeigt. Die Tabs Flame Graph und Top-Down ermöglichen es Ihnen, Funktionen mit hohem Speicherverbrauch visuell zu überprüfen.
Referenzen¶
Beiträge¶
Dieses Dokument basiert auf Erkenntnissen aus tatsächlichen Verbesserungsfällen in Hayabusa. Wenn Sie Fehler oder Techniken finden, die die Performance verbessern können, senden Sie uns bitte ein Issue oder einen Pull Request.