- Importation des résultats dans SOF-ELK (Elastic Stack)
- Installer et démarrer SOF-ELK
- Mettez à jour SOF-ELK !
- Exécuter Hayabusa
- Optionnel : Supprimer les anciennes données importées
- Configurer le fichier de configuration logstash de Hayabusa dans SOF-ELK
- Importer les résultats de Hayabusa dans SOF-ELK
- Vérifier que l'importation a fonctionné dans Kibana
- Afficher les résultats dans Discover
- Analyser les résultats
- Plans futurs
Importation des résultats dans SOF-ELK (Elastic Stack)¶
Installer et démarrer SOF-ELK¶
Les résultats de Hayabusa peuvent facilement être importés dans Elastic Stack. Nous recommandons d'utiliser SOF-ELK, une distribution Linux gratuite basée sur elastic stack et dédiée aux investigations DFIR.
Téléchargez et décompressez d'abord l'image VMware compressée en 7-zip de SOF-ELK depuis https://github.com/philhagen/sof-elk/wiki/Virtual-Machine-README.
Il existe deux versions, x86 pour les processeurs Intel et une version ARM pour les ordinateurs Apple de la série M.
Lorsque vous démarrez la VM, vous obtenez un écran semblable à celui-ci :
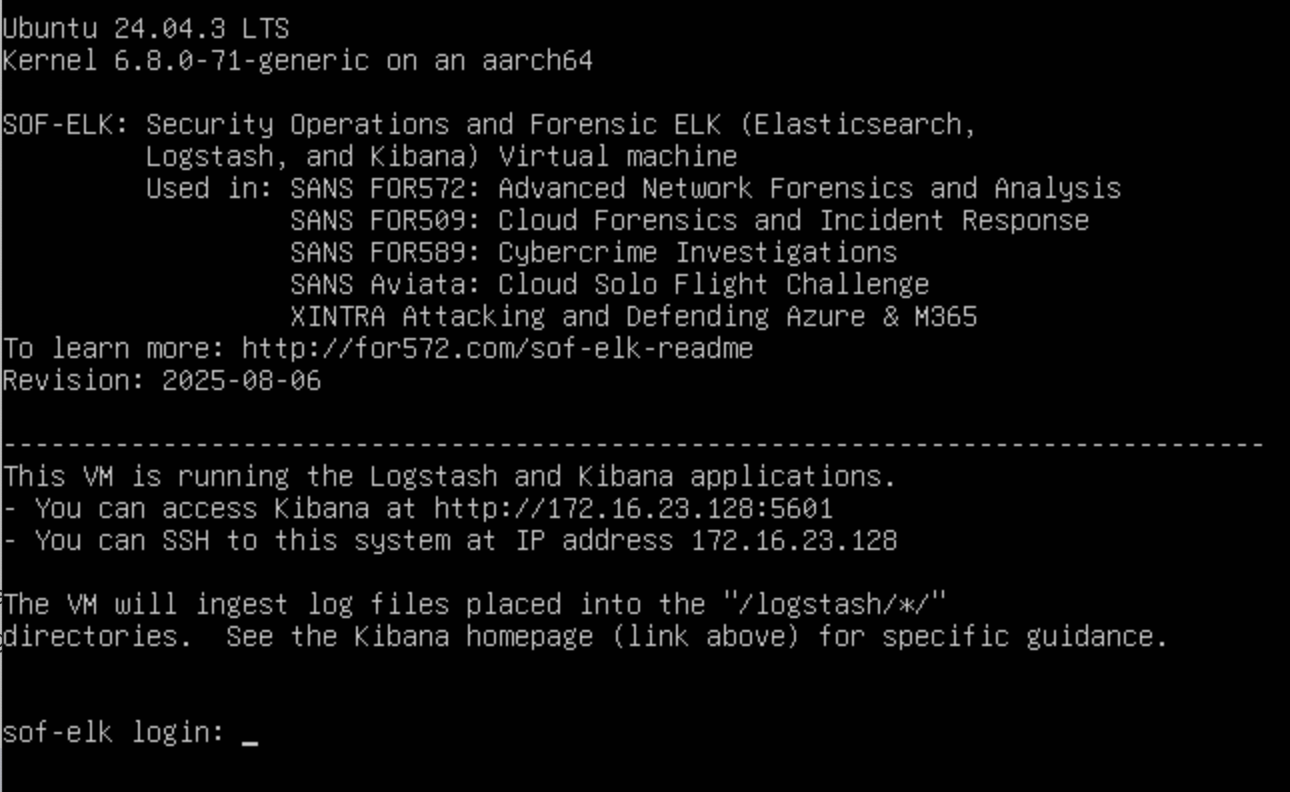
Notez l'URL de Kibana et l'adresse IP du serveur SSH.
Vous pouvez vous connecter avec les identifiants suivants :
- Nom d'utilisateur :
elk_user - Mot de passe :
forensics
Ouvrez Kibana dans un navigateur web selon l'URL affichée. Par exemple : http://172.16.23.128:5601/
Note : le chargement de Kibana peut prendre un certain temps.
Vous devriez voir une page web comme suit :
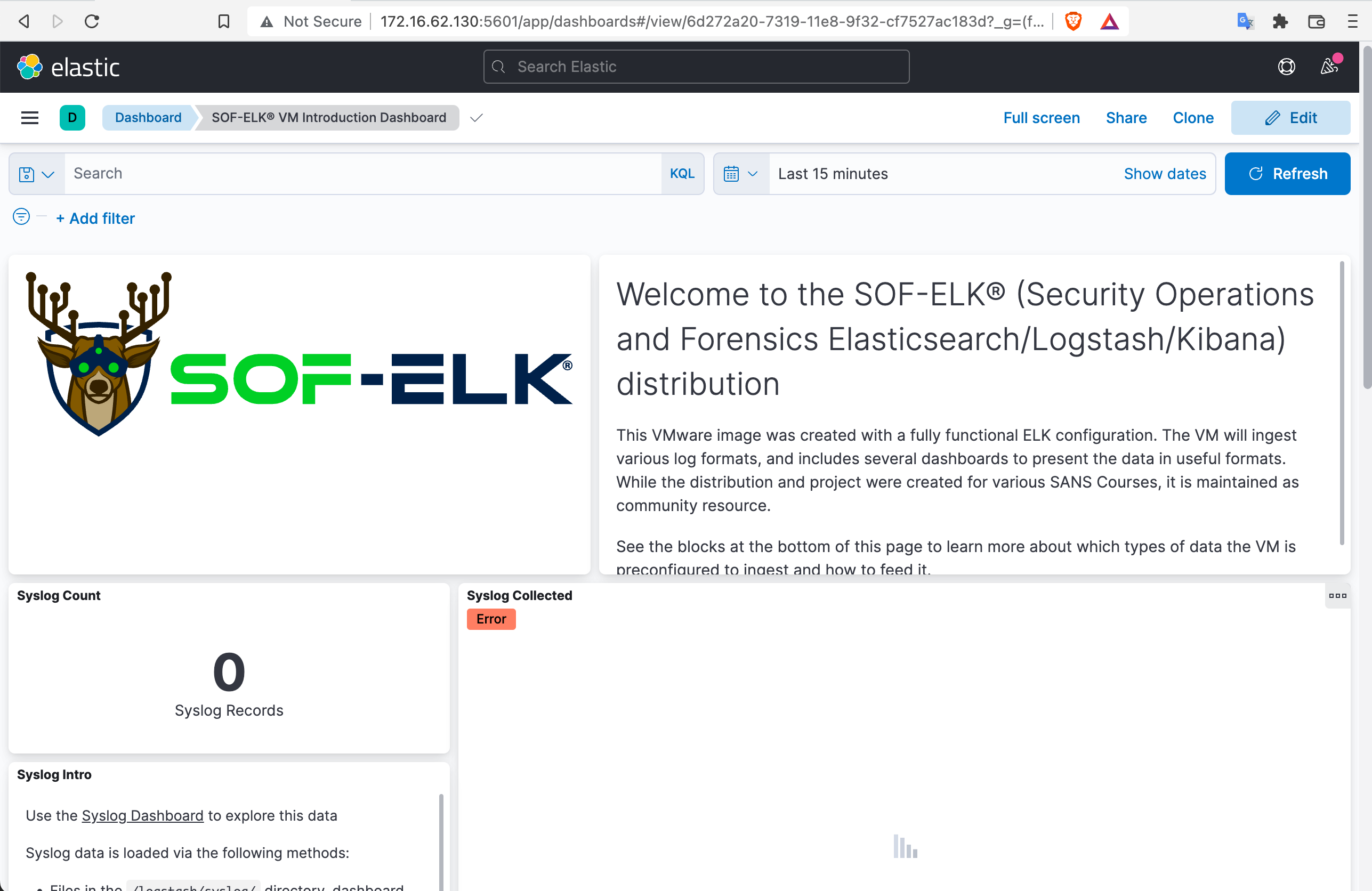
Nous recommandons de vous connecter en SSH à la VM plutôt que de taper des commandes à l'intérieur de la VM avec ssh elk_user@172.16.23.128.
Note : la disposition du clavier par défaut est le clavier US.
Problèmes de connectivité réseau sur Mac¶
Si vous êtes sous macOS et que vous obtenez une erreur no route to host dans le terminal ou que vous ne pouvez pas accéder à Kibana dans votre navigateur, cela est probablement dû aux contrôles de confidentialité du réseau local de macOS.
Dans les Réglages Système, ouvrez Confidentialité et sécurité -> Réseau local et assurez-vous que votre navigateur et votre programme de terminal sont activés pour pouvoir communiquer avec les appareils de votre réseau local.
Mettez à jour SOF-ELK !¶
Avant d'importer des données, veillez à mettre à jour SOF-ELK avec la commande sudo sof-elk_update.sh.
Exécuter Hayabusa¶
Exécutez Hayabusa et enregistrez les résultats au format JSONL.
Ex : ./hayabusa json-timeline -L -d ../hayabusa-sample-evtx -w -p super-verbose -G /opt/homebrew/var/GeoIP -o results.jsonl
Optionnel : Supprimer les anciennes données importées¶
Si ce n'est pas la première fois que vous importez des résultats de Hayabusa et que vous souhaitez tout effacer, vous pouvez le faire de la manière suivante :
- Vérifiez quels enregistrements sont actuellement dans SOF-ELK :
sof-elk_clear.py -i list - Supprimez les données actuelles :
sof-elk_clear.py -a - Supprimez les fichiers du répertoire logstash :
rm /logstash/hayabusa/*
Configurer le fichier de configuration logstash de Hayabusa dans SOF-ELK¶
Un fichier de configuration logstash Hayabusa est déjà inclus dans SOF-ELK et convertit les noms de champs au format Elastic Common Schema. Si vous êtes plus à l'aise avec les noms de champs de Hayabusa, nous recommandons d'utiliser celui que nous fournissons.
- Connectez-vous d'abord en SSH à SOF-ELK :
ssh elk_user@172.16.23.128 - Supprimez ou déplacez le fichier de configuration logstash actuel :
sudo rm /etc/logstash/conf.d/6650-hayabusa.conf - Téléversez le nouveau fichier 6650-hayabusa-jsonl.conf dans
/etc/logstash/conf.d/:sudo wget https://raw.githubusercontent.com/Yamato-Security/hayabusa/main/doc/ElasticStackImport/6650-hayabusa-jsonl.conf -O /etc/logstash/conf.d/6650-hayabusa.conf. - Redémarrez logstash :
sudo systemctl restart logstash
Ce fichier de configuration créera des champs consolidés DetailsText et ExtraFieldInfoText qui vous permettent de voir rapidement les champs les plus importants d'un coup d'œil au lieu d'avoir à prendre le temps d'ouvrir chaque enregistrement un par un pour parcourir tous les champs.
Importer les résultats de Hayabusa dans SOF-ELK¶
Les journaux sont ingérés dans SOF-ELK en copiant les journaux dans le répertoire approprié à l'intérieur du répertoire /logstash.
Quittez d'abord la session SSH avec exit, puis copiez le fichier de résultats Hayabusa que vous avez créé :
scp ./results.jsonl elk_user@172.16.23.128:/logstash/hayabusa
Vérifier que l'importation a fonctionné dans Kibana¶
Notez d'abord les Total detections, First Timestamp et Last Timestamp dans le Results Summary de votre analyse Hayabusa.
Si vous ne parvenez pas à obtenir ces informations, vous pouvez exécuter wc -l results.jsonl sous *nix pour obtenir le nombre total de lignes pour Total detections.
Par défaut, Hayabusa ne trie pas les résultats afin d'améliorer les performances, vous ne pouvez donc pas regarder la première et la dernière ligne pour obtenir le premier et le dernier horodatage.
Si vous ne connaissez pas exactement le premier et le dernier horodatage, définissez simplement la première date dans Kibana sur l'année 2007 et le dernier jour sur now afin d'avoir tous les résultats.
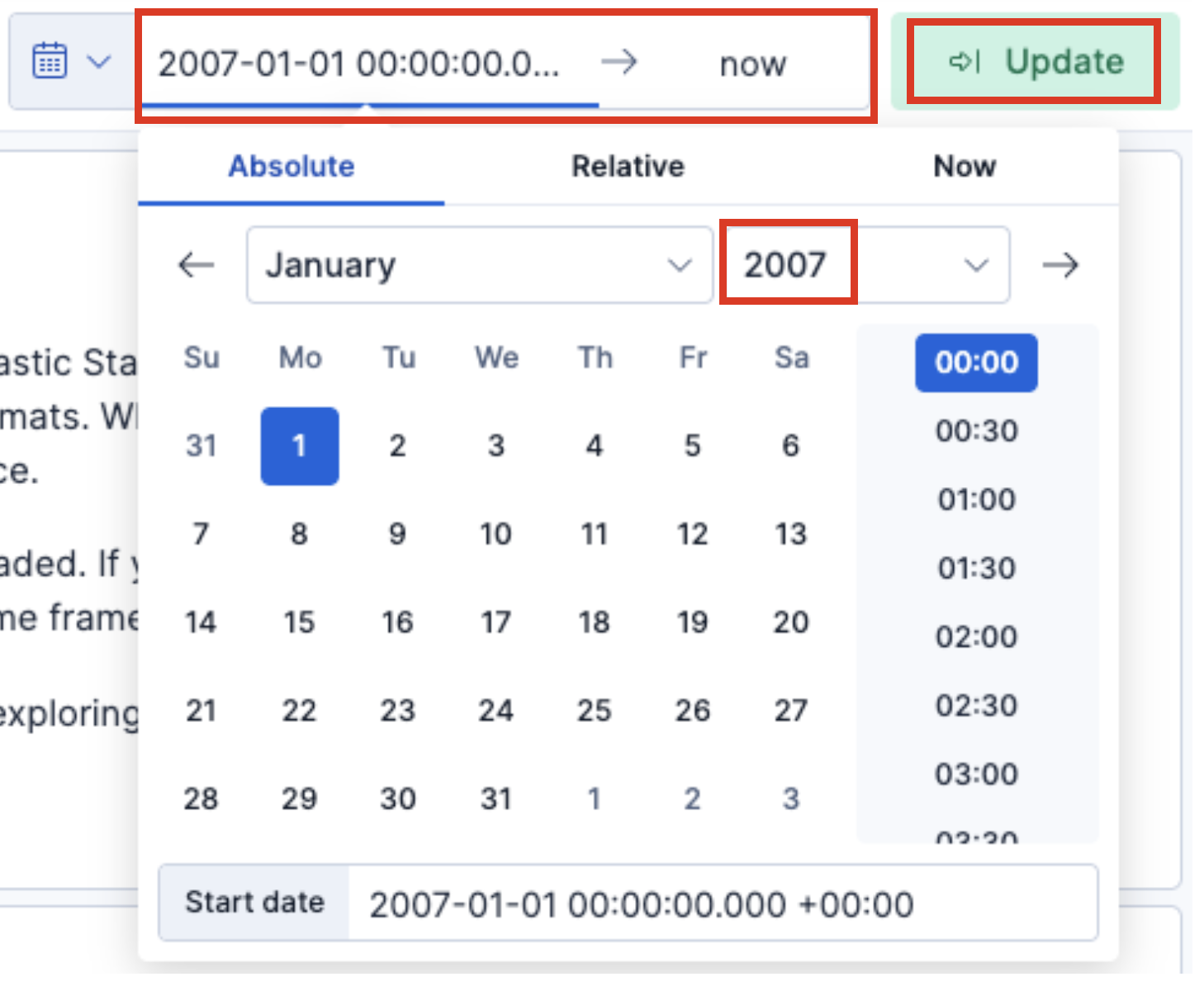
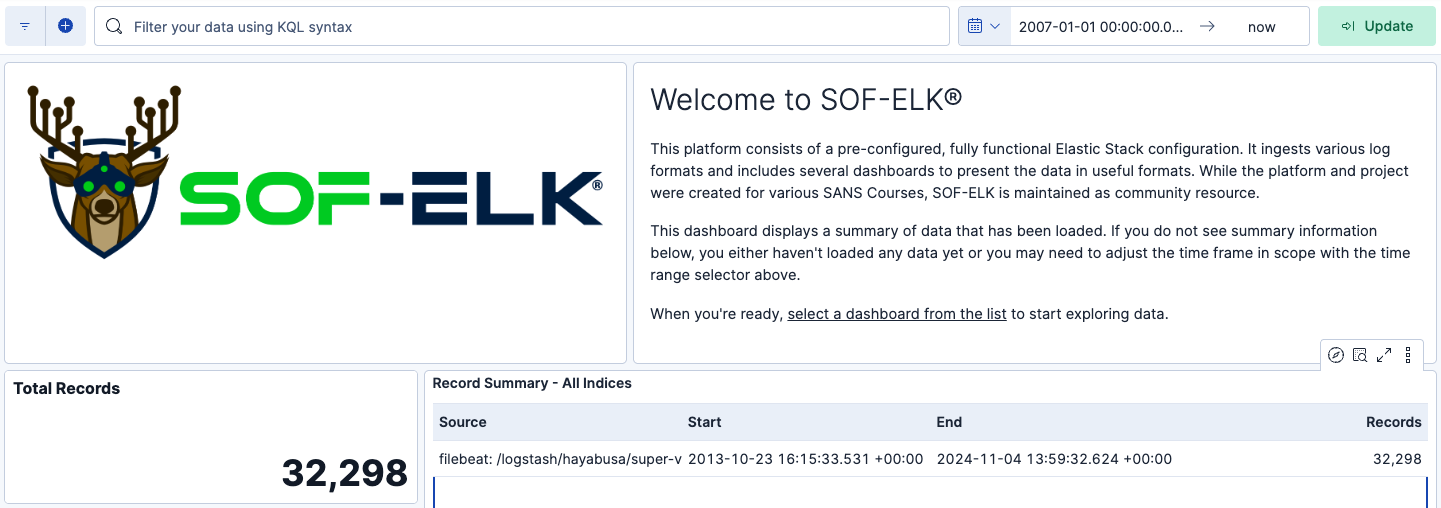
Vous devriez maintenant voir le Total Records ainsi que le premier et le dernier horodatage des événements qui ont été importés.
L'importation de tous les événements prend parfois un certain temps, alors continuez simplement à actualiser la page jusqu'à ce que le Total Records corresponde au nombre attendu.
Vous pouvez également vérifier depuis le terminal en exécutant sof-elk_clear.py -i list pour voir si l'importation a réussi.
Vous devriez voir que votre index evtxlogs contient désormais plus d'enregistrements :
Veuillez créer une issue sur GitHub si vous rencontrez des erreurs d'analyse lors de l'importation.
Vous pouvez le vérifier en consultant la fin du fichier journal /var/log/logstash/logstash-plain.log.
Afficher les résultats dans Discover¶
Cliquez sur l'icône de la barre latérale en haut à gauche et cliquez sur Discover :
Vous verrez probablement No results match your search criteria.
Dans le coin supérieur gauche où il est indiqué l'index logstash-*, cliquez dessus et remplacez-le par evtxlogs-*.
Vous devriez maintenant voir la chronologie Discover.
Analyser les résultats¶
La vue Discover par défaut devrait ressembler à ceci :
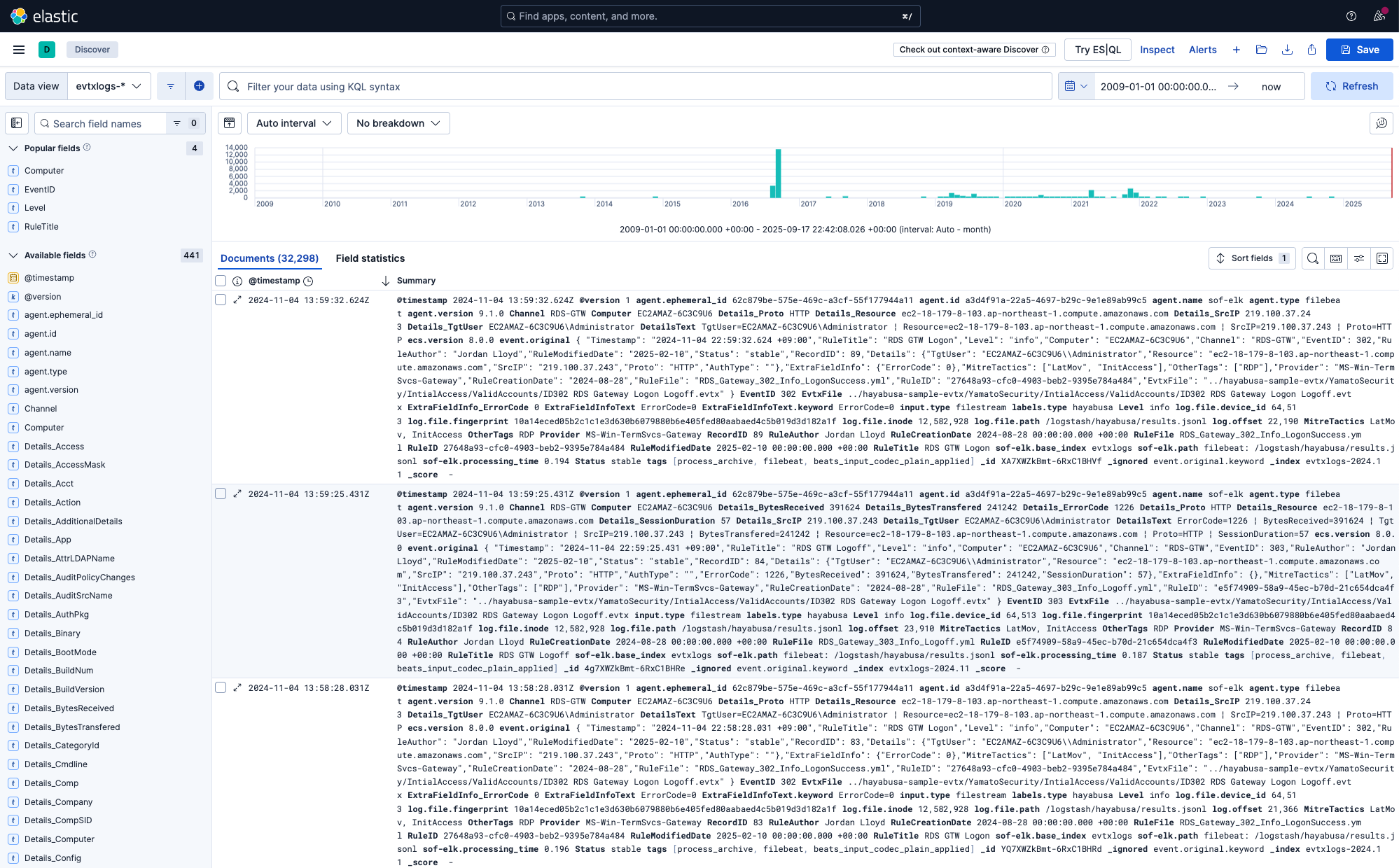
Vous pouvez obtenir un aperçu du moment où les événements se sont produits et de leur fréquence en regardant l'histogramme en haut.
Ajouter des colonnes¶
Dans la barre latérale de gauche, vous pouvez ajouter les champs que vous souhaitez afficher dans les colonnes en cliquant sur le signe plus après avoir survolé un champ. Comme il y a de nombreux champs, vous pouvez taper le nom du champ que vous recherchez dans la zone de recherche.
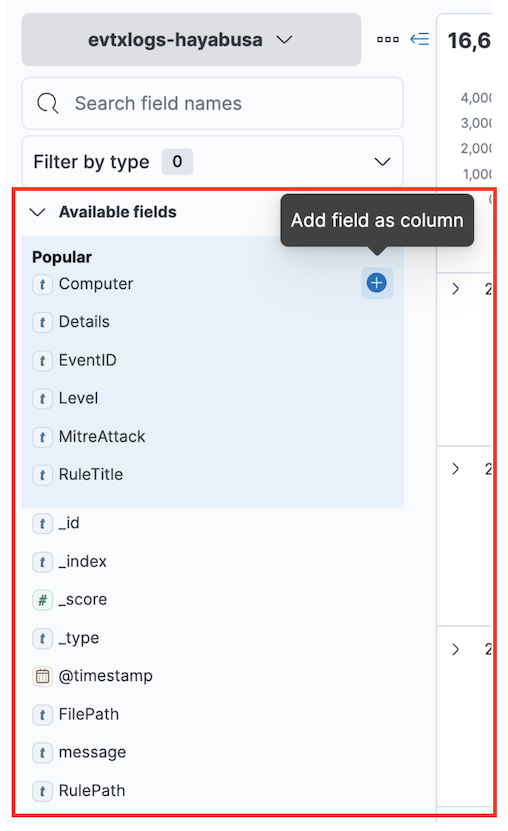
Pour commencer, nous recommandons les colonnes suivantes :
ComputerEventIDLevelRuleTitleDetailsText
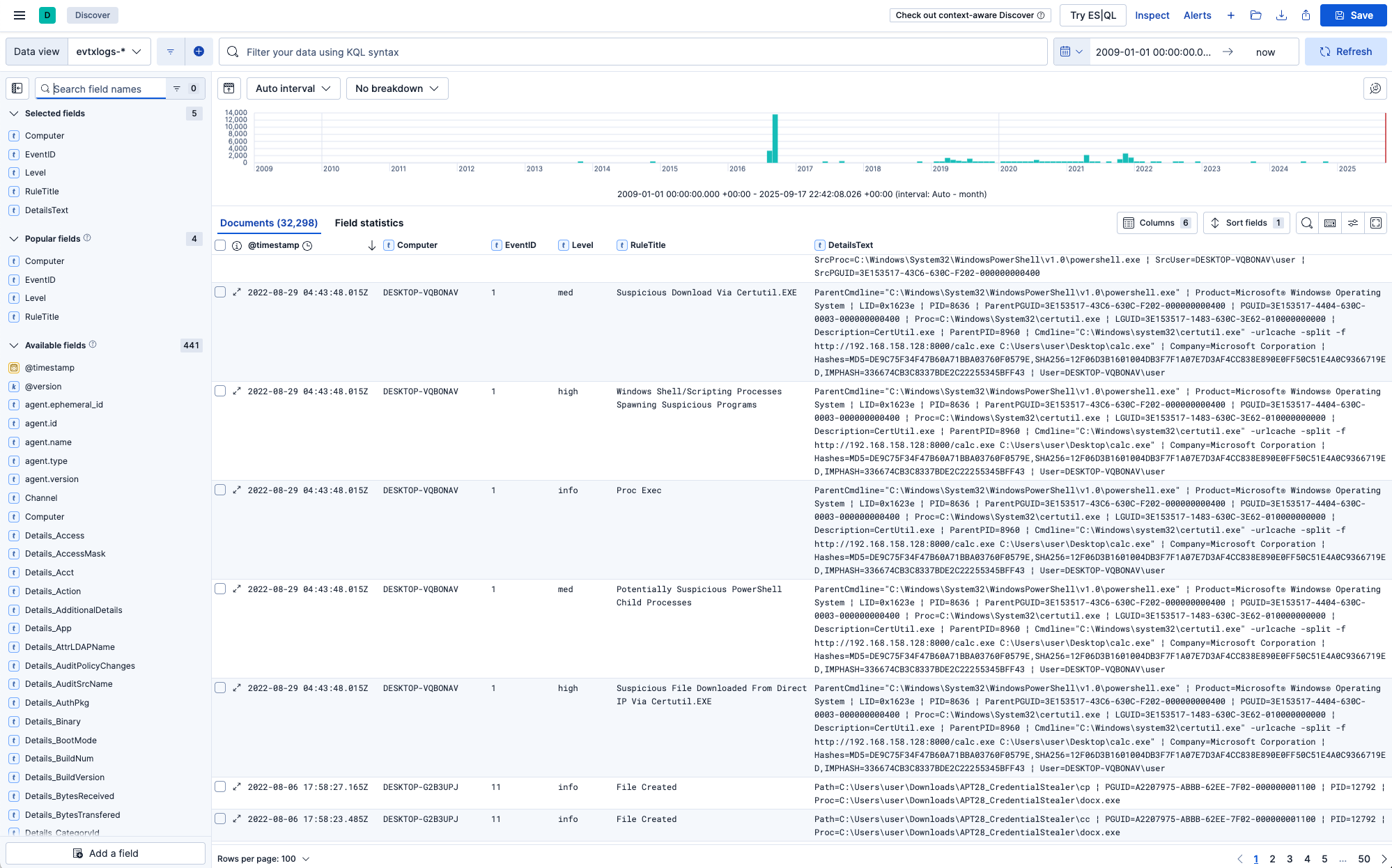
Si votre écran est suffisamment large, vous pouvez également ajouter ExtraFieldInfoText afin de voir toutes les informations des champs.
Votre vue Discover devrait maintenant ressembler à ceci :
Filtrage¶
Vous pouvez filtrer avec KQL (Kibana Query Language) pour rechercher certains événements et alertes. Par exemple :
* Level: "crit" : Afficher uniquement les alertes critiques.
* Level: "crit" OR Level: "high" : Afficher les alertes élevées et critiques.
* NOT Level: info : Ne pas afficher les événements informatifs, uniquement les alertes.
* MitreTactics: *LatMov* : Afficher les événements et alertes liés au déplacement latéral.
* "PW Spray" : Afficher uniquement des attaques spécifiques comme « Password Spray ».
* "LID: 0x8724ead" : Afficher toute l'activité associée au Logon ID 0x8724ead.
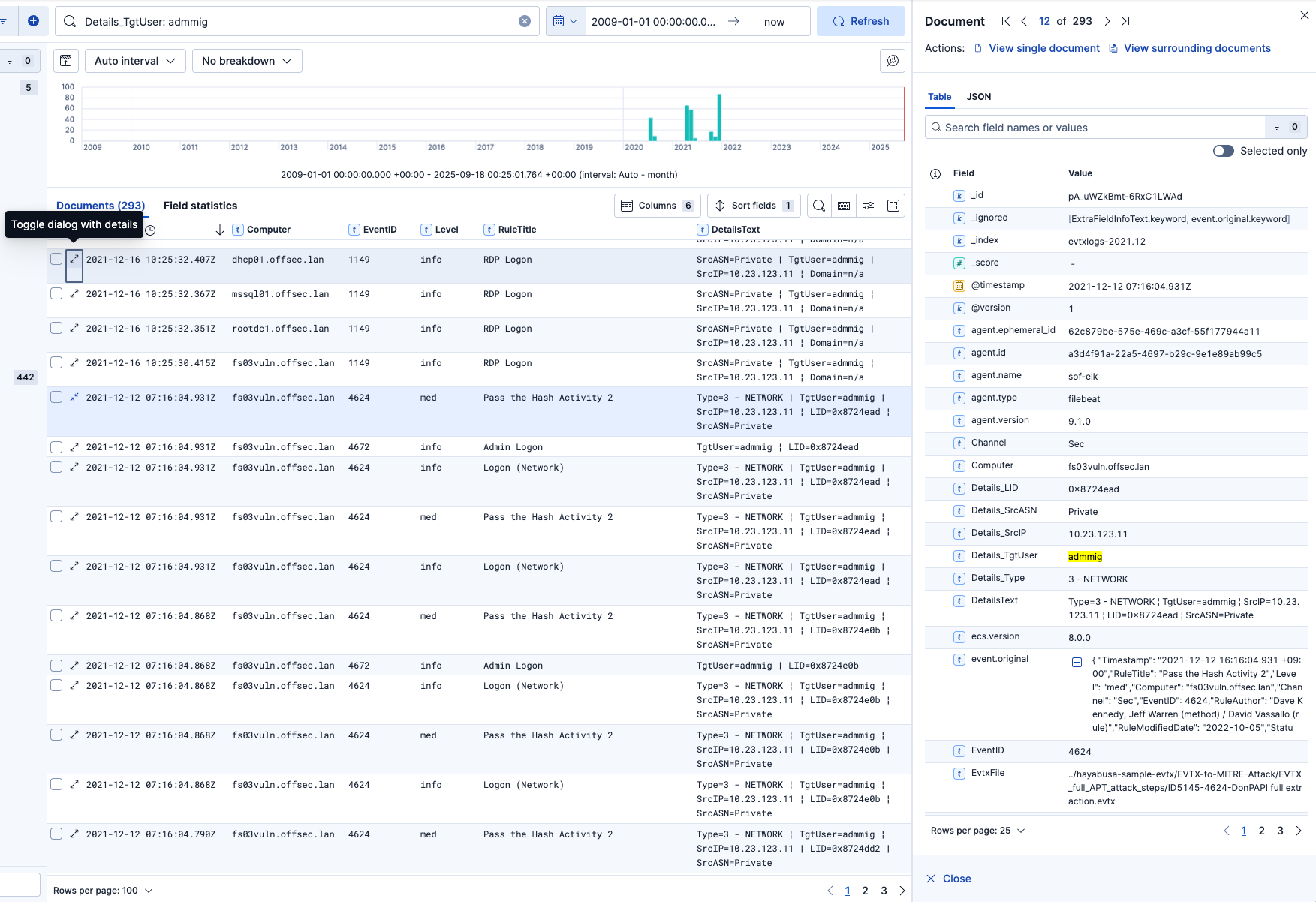
* Details_TgtUser: admmig : Rechercher tous les événements où l'utilisateur cible est admmig.
Basculer l'affichage des détails¶
Pour vérifier tous les champs d'un enregistrement, il suffit de cliquer sur l'icône (Toggle dialog with details) à côté de l'horodatage :
Afficher les documents environnants¶
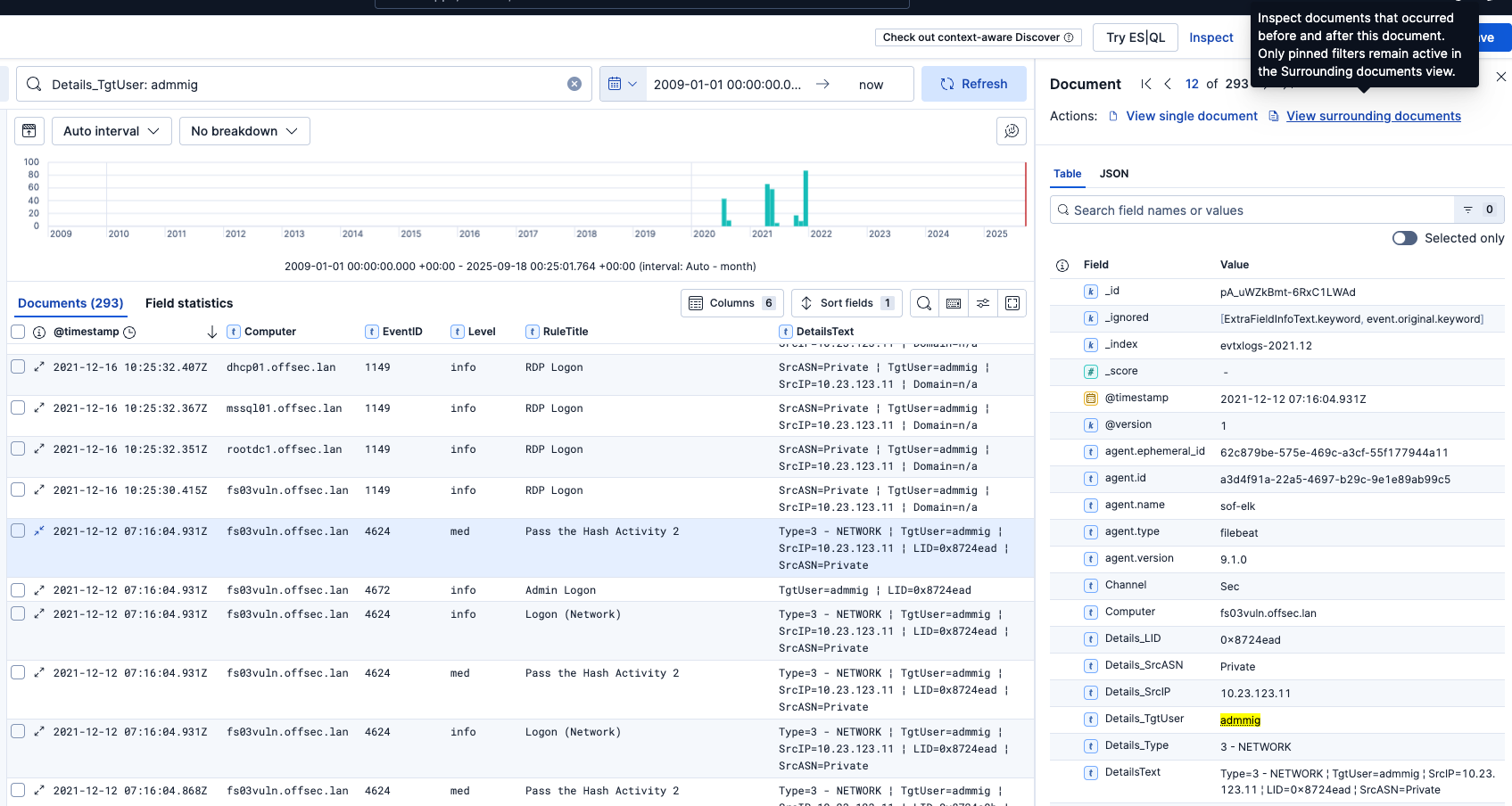
Si vous souhaitez afficher les événements directement avant et après une certaine alerte, ouvrez d'abord les détails de cette alerte puis cliquez sur View surrounding documents en haut à droite :
Dans cet exemple, nous voyons les événements avant et après l'alerte d'attaque Pass the Hash :
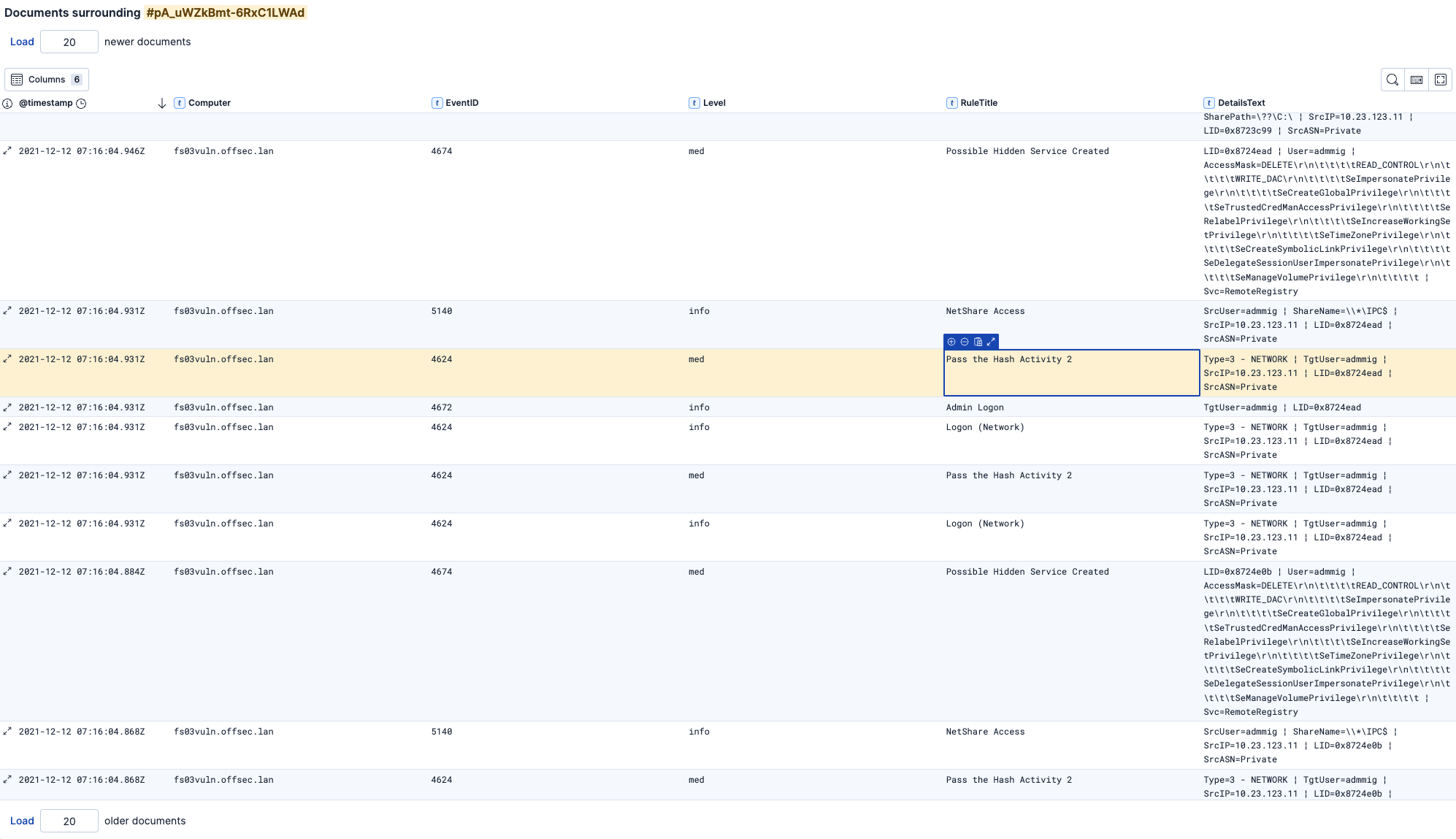
Note : Modifiez les nombres en haut
Load x newer documentsou en basLoad x older documentspour récupérer davantage d'événements.
Obtenir des métriques rapides sur les champs¶
Dans la colonne de gauche, si vous cliquez sur un nom de champ, cela vous donnera des métriques rapides sur son utilisation :
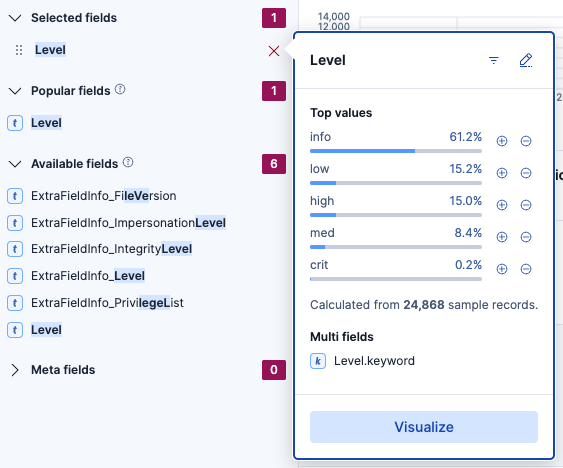
Notez que les données sont échantillonnées pour des raisons de rapidité, elles ne sont donc pas exactes à 100 %.
Plans futurs¶
- Analyseurs Logstash pour CSV
- Tableau de bord prédéfini