Guide de performance Rust pour les développeurs Hayabusa¶
Auteur¶
Fukusuke Takahashi
Traduction anglaise¶
Zach Mathis (@yamatosecurity)
À propos de ce document¶
Hayabusa (en français : « faucon pèlerin ») est un outil d'analyse forensique rapide développé par le groupe Yamato Security au Japon. Il est développé en Rust afin de (traquer les menaces) aussi vite qu'un faucon pèlerin. Rust est en soi un langage rapide, cependant il existe de nombreux pièges qui peuvent entraîner des vitesses lentes et une consommation mémoire élevée. Nous avons créé ce document à partir d'améliorations de performance réelles dans Hayabusa (voir le changelog ici), mais ces techniques devraient également s'appliquer à d'autres programmes Rust. Nous espérons que vous pourrez bénéficier des connaissances que nous avons acquises au fil de nos essais et erreurs.
Amélioration de la vitesse¶
Changer l'allocateur de mémoire¶
Le simple fait de changer l'allocateur de mémoire par défaut peut améliorer significativement la vitesse. Par exemple, selon ces benchmarks, les deux allocateurs de mémoire suivants
sont beaucoup plus rapides que l'allocateur de mémoire par défaut. Nous avons pu confirmer une amélioration significative de la vitesse en changeant notre allocateur de mémoire de jemalloc à mimalloc, c'est pourquoi nous avons fait de mimalloc l'allocateur par défaut depuis la version 1.8.0. (Bien que mimalloc utilise un peu plus de mémoire que jemalloc.)
Avant ¶
Après ¶
Vous n'avez besoin d'effectuer que les 2 étapes suivantes pour changer l'allocateur de mémoire global :
- Ajoutez le crate mimalloc à la section [dependencies] du fichier
Cargo.toml: - Définissez que vous voulez utiliser mimalloc sous #[global_allocator] quelque part dans le programme : C'est tout ce que vous devez faire pour changer l'allocateur de mémoire.
Efficacité(Exemple réel issu d'une Pull Request) ¶
L'ampleur de l'amélioration de la vitesse dépendra du programme, mais dans l'exemple suivant
le changement de l'allocateur de mémoire pour mimalloc a entraîné une augmentation de performance de 20 à 30 % sur les processeurs Intel. (Pour une raison quelconque, l'augmentation de performance n'était pas aussi significative sur les appareils macOS basés sur ARM.)
Réduire le traitement IO dans les boucles¶
Le traitement IO disque est beaucoup plus lent que le traitement en mémoire. Par conséquent, il est souhaitable d'éviter autant que possible le traitement IO, en particulier dans les boucles.
Avant ¶
L'exemple ci-dessous montre une ouverture de fichier se produisant un million de fois dans une boucle :
use std::fs;
fn main() {
for _ in 0..1000000 {
let f = fs::read_to_string("sample.txt").unwrap();
f.len();
}
}
Après ¶
En ouvrant le fichier en dehors de la boucle comme suit
use std::fs;
fn main() {
let f = fs::read_to_string("sample.txt").unwrap();
for _ in 0..1000000 {
f.len();
}
}
Efficacité(Exemple réel issu d'une Pull Request) ¶
Dans l'exemple suivant, le traitement IO lors de la gestion d'un résultat de détection à la fois a pu être effectué en dehors de la boucle :
Cela a entraîné une amélioration de la vitesse d'environ 20 %.
Éviter la compilation des expressions régulières dans les boucles¶
La compilation des expressions régulières est un processus très coûteux comparé à la correspondance d'expressions régulières. Par conséquent, il est conseillé d'éviter autant que possible la compilation d'expressions régulières, en particulier dans les boucles.
Avant ¶
Par exemple, le processus suivant crée 100 000 tentatives de correspondance d'une expression régulière dans une boucle :
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..100000 {
if Regex::new(match_str).unwrap().is_match(text){ // Regular expression compilation in a loop
println!("matched!");
}
}
}
Après ¶
En effectuant une compilation d'expression régulière en dehors de la boucle, comme montré ci-dessous
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap(); // Compile the regular expression outside the loop
for _ in 0..100000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Efficacité(Exemple réel issu d'une Pull Request) ¶
Dans l'exemple suivant, la compilation d'expression régulière est effectuée en dehors de la boucle et mise en cache.
Cela a entraîné des améliorations significatives de la vitesse.
Utiliser des IO avec tampon¶
Sans IO avec tampon, les IO de fichier sont lentes. Avec des IO avec tampon, les opérations IO sont effectuées à travers des tampons en mémoire, réduisant le nombre d'appels système et améliorant la vitesse.
Avant ¶
Par exemple, dans le processus suivant, write se produit 1 000 000 de fois.
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
for _ in 0..1000000 {
f.write(b"hello world!");
}
}
Après ¶
En utilisant BufWriter comme suit
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
let mut writer = BufWriter::new(f);
for _ in 0..1000000 {
writer.write(b"some text");
}
writer.flush().unwrap();
}
Efficacité(Exemple réel issu d'une Pull Request) ¶
La méthode décrite ci-dessus a été implémentée ici
et a entraîné des améliorations significatives de la vitesse dans le traitement de sortie.
Utiliser les méthodes String standard au lieu des expressions régulières¶
Bien que les expressions régulières puissent couvrir des motifs de correspondance complexes, elles sont plus lentes que les méthodes String standard. Par conséquent, il est plus rapide d'utiliser les méthodes String standard pour des correspondances de chaînes simples telles que les suivantes.
- Correspondance commençant par(Regex :
foo.*)-> String::starts_with() - Correspondance se terminant par(Regex :
.*foo)-> String::ends_with() - Correspondance contenant(Regex :
.*foo.*)-> String::contains()
Avant ¶
Par exemple, le code suivant effectue une correspondance se terminant par dans une expression régulière un million de fois.
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = ".*abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Après ¶
En utilisant String::ends_with() comme suit
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..1000000 {
if text.ends_with(match_str) {
println!("matched!");
}
}
}
Efficacité(Exemple réel issu d'une Pull Request) ¶
Comme Hayabusa nécessite une comparaison de chaînes insensible à la casse, nous utilisons to_lowercase() puis appliquons la méthode ci-dessus. Même dans ce cas, dans les exemples suivants
- Imporving speed by changing wildcard search process from regular expression match to starts_with/ends_with match #890
- Improving speed by using eq_ignore_ascii_case() before regular expression match #884
la vitesse s'est améliorée d'environ 15 % par rapport à avant.
Filtrer par longueur de chaîne¶
Selon les caractéristiques des chaînes traitées, l'ajout d'un filtre simple peut réduire le nombre de tentatives de correspondance de chaînes et accélérer le processus. Si vous comparez souvent des chaînes de longueurs non fixes et non correspondantes, vous pouvez accélérer le processus en utilisant la longueur de chaîne comme filtre primaire.
Avant ¶
Par exemple, le code suivant tente un million de correspondances d'expressions régulières.
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Après ¶
En utilisant String::len() comme filtre primaire, comme montré ci-dessous
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if text.len() == match_str.len() { // Primary filter by string length
if r.is_match(text) {
println!("matched!");
}
}
}
}
Efficacité(Exemple réel issu d'une Pull Request) ¶
Dans l'exemple suivant, la méthode ci-dessus est utilisée.
Cela a amélioré la vitesse d'environ 15 %.
Ne pas compiler avec codegen-units=1¶
De nombreux articles sur l'optimisation de performance avec Rust conseillent d'ajouter codegen-units = 1 sous la section [profile.release].
Cela entraînera des temps de compilation plus lents car la valeur par défaut est de compiler en parallèle, mais en théorie cela devrait produire un code plus optimisé et plus rapide.
Cependant, lors de nos tests, Hayabusa s'exécute en réalité plus lentement avec cette option activée et la compilation prend plus de temps, c'est pourquoi nous la laissons désactivée.
La taille binaire de l'exécutable est environ 100 ko plus petite, donc cela peut être idéal pour les systèmes embarqués où l'espace disque dur est limité.
Réduire la consommation mémoire¶
Éviter l'utilisation inutile de clone(), to_string() et to_owned()¶
Utiliser clone() ou to_string() sont des moyens faciles de résoudre les erreurs de compilation liées à la propriété (ownership). Cependant, elles entraînent généralement une consommation mémoire élevée et devraient être évitées. Il est toujours préférable de voir d'abord si vous pouvez les remplacer par des références à faible coût.
Avant ¶
Par exemple, si vous voulez itérer plusieurs fois sur le même Vec, vous pouvez utiliser clone() pour éliminer les erreurs de compilation.
fn main() {
let lst = vec![1, 2, 3];
for x in lst.clone() { // In order to eliminate compile errors
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
Après ¶
Cependant, en utilisant des références comme montré ci-dessous, vous pouvez supprimer le besoin d'utiliser clone().
fn main() {
let lst = vec![1, 2, 3];
for x in &lst { // Eliminate compile errors with a reference
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
Efficacité(Exemple réel issu d'une Pull Request) ¶
Dans l'exemple suivant, en remplaçant l'utilisation inutile de clone(), to_string() et to_owned(),
nous avons pu réduire significativement la consommation mémoire.
Utiliser Iterator au lieu de Vec¶
Vec garde tous les éléments en mémoire, il utilise donc beaucoup de mémoire proportionnellement au nombre d'éléments. Si le traitement d'un élément à la fois est suffisant, alors utiliser un Iterator à la place utilisera beaucoup moins de mémoire.
Avant ¶
Par exemple, la fonction return_lines() suivante lit un fichier d'environ 1 Go et retourne un Vec :
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> Vec<String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
.collect()
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
Après ¶
À la place, vous devriez retourner un Iterator Trait comme suit :
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> impl Iterator<Item=String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
// ここでcollect()せずに、Iteratorを戻り値として返す
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
Box<dyn Iterator<Item = T>> comme suit :
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines(need_filter:bool) -> Box<dyn Iterator<Item = String>> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
if need_filter {
let result= buf.lines()
.filter_map(|l| l.ok())
.map(|l| l.replace("A", "B"));
return Box::new(result)
}
let result= buf.lines()
.map(|l| l.expect("Could not parse line"));
Box::new(result)
}
fn main() {
let lines = return_lines(true);
for line in lines {
println!("{}", line)
}
}
Efficacité(Exemple réel issu d'une Pull Request) ¶
L'exemple suivant utilise la méthode décrite ci-dessus :
Lors d'un test sur un fichier JSON de 1,7 Go, la mémoire a diminué de 75 %.
Utiliser le crate compact_str pour gérer les chaînes courtes¶
Lorsque vous traitez un grand nombre de chaînes courtes de moins de 24 octets, le crate compact_str peut être utilisé pour réduire la consommation mémoire.
Avant ¶
Dans l'exemple ci-dessous, le Vec contient 10 millions de chaînes.
fn main() {
let v: Vec<String> = vec![String::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
Après ¶
Il est préférable de les remplacer par un CompactString :
use compact_str::CompactString;
fn main() {
let v: Vec<CompactString> = vec![CompactString::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
Efficacité(Exemple réel issu d'une Pull Request) ¶
Dans l'exemple suivant, les chaînes courtes sont gérées avec CompactString :
Cela a donné une réduction de la consommation mémoire d'environ 20 %.
Supprimer les champs inutiles dans les structures à longue durée de vie¶
Les structures qui continuent d'être conservées en mémoire pendant le démarrage du processus peuvent affecter la consommation mémoire globale. Dans Hayabusa, les structures suivantes (à partir de la version 2.2.2), en particulier, sont conservées en grand nombre.
La suppression des champs associés aux structures ci-dessus a eu un certain effet sur la réduction de la consommation mémoire globale.
Avant ¶
Par exemple, le champ DetectInfo était, jusqu'à la version 1.8.1, le suivant :
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
pub record_information: CompactString,
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
Après ¶
En supprimant le champ record_information comme suit
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
// remove record_information field
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
Efficacité(Exemple réel issu d'une Pull Request) ¶
Dans l'exemple suivant, lors d'un test sur des données où le nombre d'enregistrements de résultats de détection était d'environ 1,5 million,
- Reduced memory usage of DetectInfo/EvtxRecordInfo #837
- Reduce memory usage by removing unnecessary regex #894
nous avons pu obtenir une réduction de la consommation mémoire d'environ 300 Mo.
Benchmarking¶
Utiliser la fonction de statistiques de l'allocateur de mémoire.¶
Certains allocateurs de mémoire maintiennent leurs propres statistiques de consommation mémoire. Par exemple, dans mimalloc, la fonction mi_stats_print_out() peut être appelée pour obtenir la consommation mémoire.
Comment obtenir les statistiques ¶
Prérequis : Vous devez utiliser mimalloc comme expliqué dans la section Changer l'allocateur de mémoire.
- Dans la section dependencies de
Cargo.toml, ajoutez le crate libmimalloc-sys : - Chaque fois que vous voulez afficher les statistiques de consommation mémoire, écrivez le code suivant et, à l'intérieur d'un bloc
unsafe, appelez mi_stats_print_out(). Les statistiques de consommation mémoire seront affichées sur la sortie standard. -
La valeur
peak/reserveden haut à gauche correspond à la consommation mémoire maximale.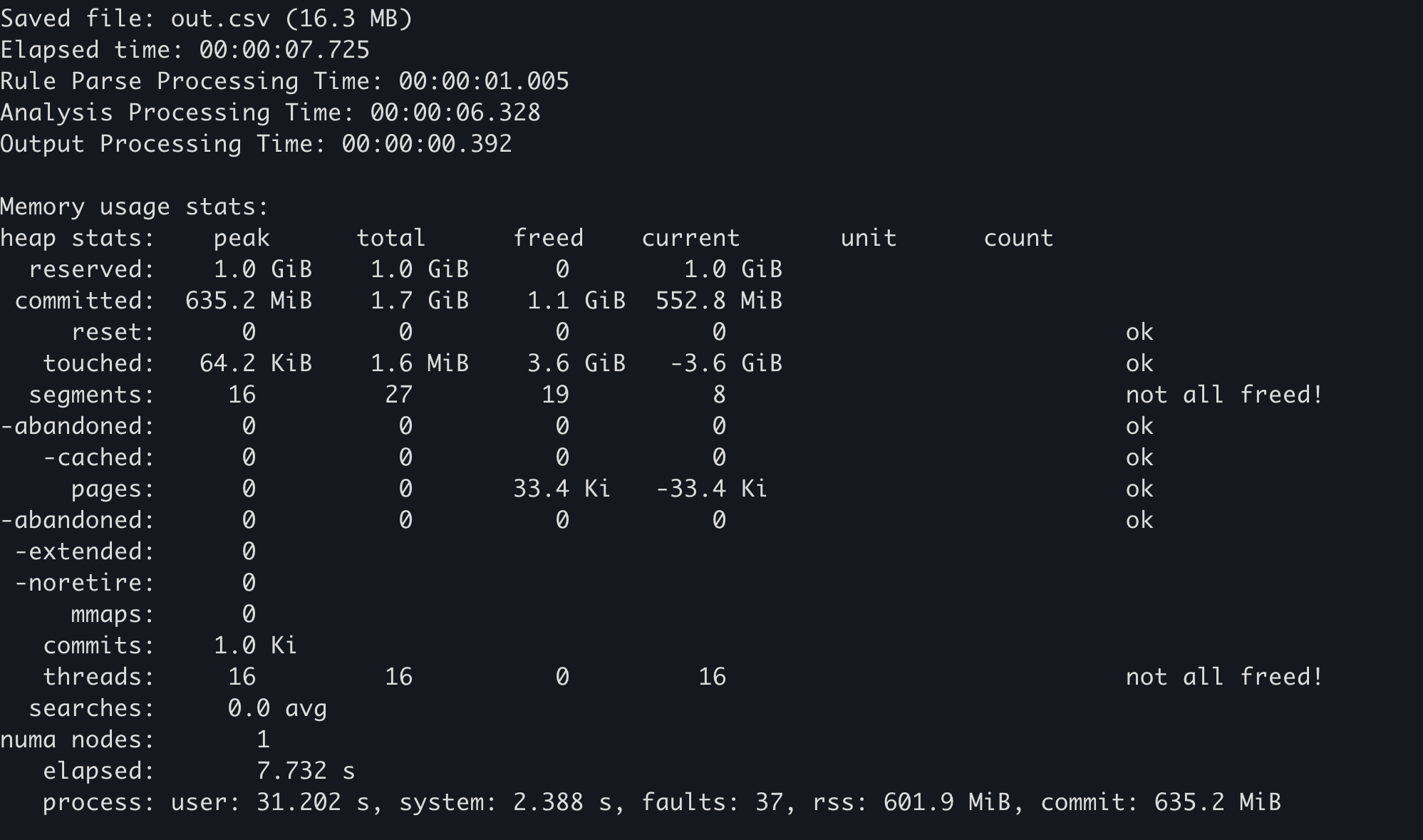
Exemple ¶
L'implémentation ci-dessus a été appliquée dans ce qui suit :
Dans Hayabusa, si vous ajoutez l'option --debug, les statistiques de consommation mémoire seront affichées à la fin.
Utiliser le compteur de performance de Windows¶
Diverses utilisations de ressources peuvent être vérifiées à partir des statistiques que l'on peut obtenir du côté du système d'exploitation. Dans ce cas, les deux points suivants doivent être notés.
- Influence du logiciel antivirus (Windows Defender)
- Seule la première exécution est affectée par l'analyse et est plus lente, donc les résultats de la deuxième exécution et des suivantes après la compilation conviennent pour la comparaison. (Ou vous pouvez désactiver votre antivirus pour des résultats plus précis.)
- Influence de la mise en cache des fichiers
- Les résultats de la deuxième fois et des suivantes après le démarrage du système d'exploitation sont plus rapides que la première fois, car les evtx et autres IO de fichiers sont lus depuis le cache de fichiers en mémoire, donc les résultats de la première fois après le démarrage du système d'exploitation sont plus idéaux pour effectuer des benchmarks.
Comment obtenir ¶
Prérequis:La procédure suivante n'est valide que pour les environnements où PowerShell 7 est déjà installé sur Windows.
- Redémarrez le système d'exploitation
- Exécutez la commande Get-Counter de
PowerShell 7qui enregistrera en continu le compteur de performance chaque seconde dans un fichier CSV. (Si vous souhaitez mesurer des ressources autres que celles listées ci-dessous, cet article est une bonne référence.) - Exécutez le processus que vous voulez mesurer.
Exemple ¶
Ce qui suit contient un exemple de procédure pour mesurer la performance avec Hayabusa.
Utiliser heaptrack¶
heaptrack est un profileur de mémoire sophistiqué disponible pour Linux et macOS. En utilisant heaptrack, vous pouvez étudier en profondeur les goulots d'étranglement.
Comment obtenir ¶
Prérequis : Ci-dessous se trouve la procédure pour Ubuntu 22.04. Vous ne pouvez pas utiliser heaptrack sur Windows.
- Installez heaptrack avec les deux commandes suivantes.
- Supprimez le code mimalloc suivant de Hayabusa. (Vous ne pouvez pas utiliser le profileur de mémoire de heaptrack avec mimalloc.
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L32-L33
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L59-L60
-
https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L632-L634
-
Supprimez la section [profile.release] dans le fichier
Cargo.tomlde Hayabusa et changez-la comme suit : -
Construisez une version release :
cargo build --release - Exécutez
heaptrack hayabusa csv-timeline -d sample -o out.csv
Maintenant, lorsque Hayabusa termine son exécution, les résultats de heaptrack s'ouvriront automatiquement dans une application GUI.
Exemples ¶
Un exemple des résultats de heaptrack est montré ci-dessous. Les onglets Flame Graph et Top-Down vous permettent de vérifier visuellement les fonctions à forte consommation mémoire.
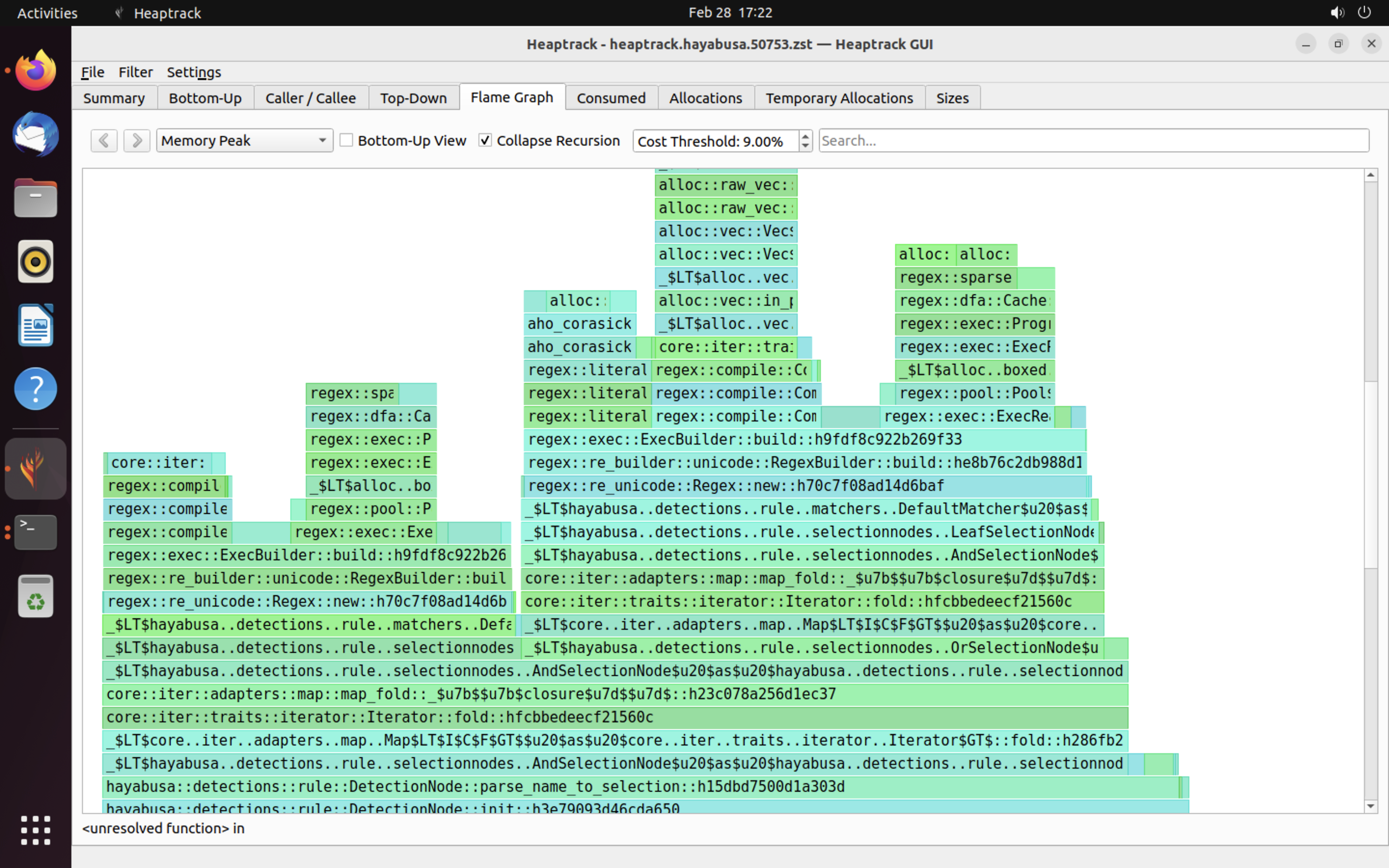
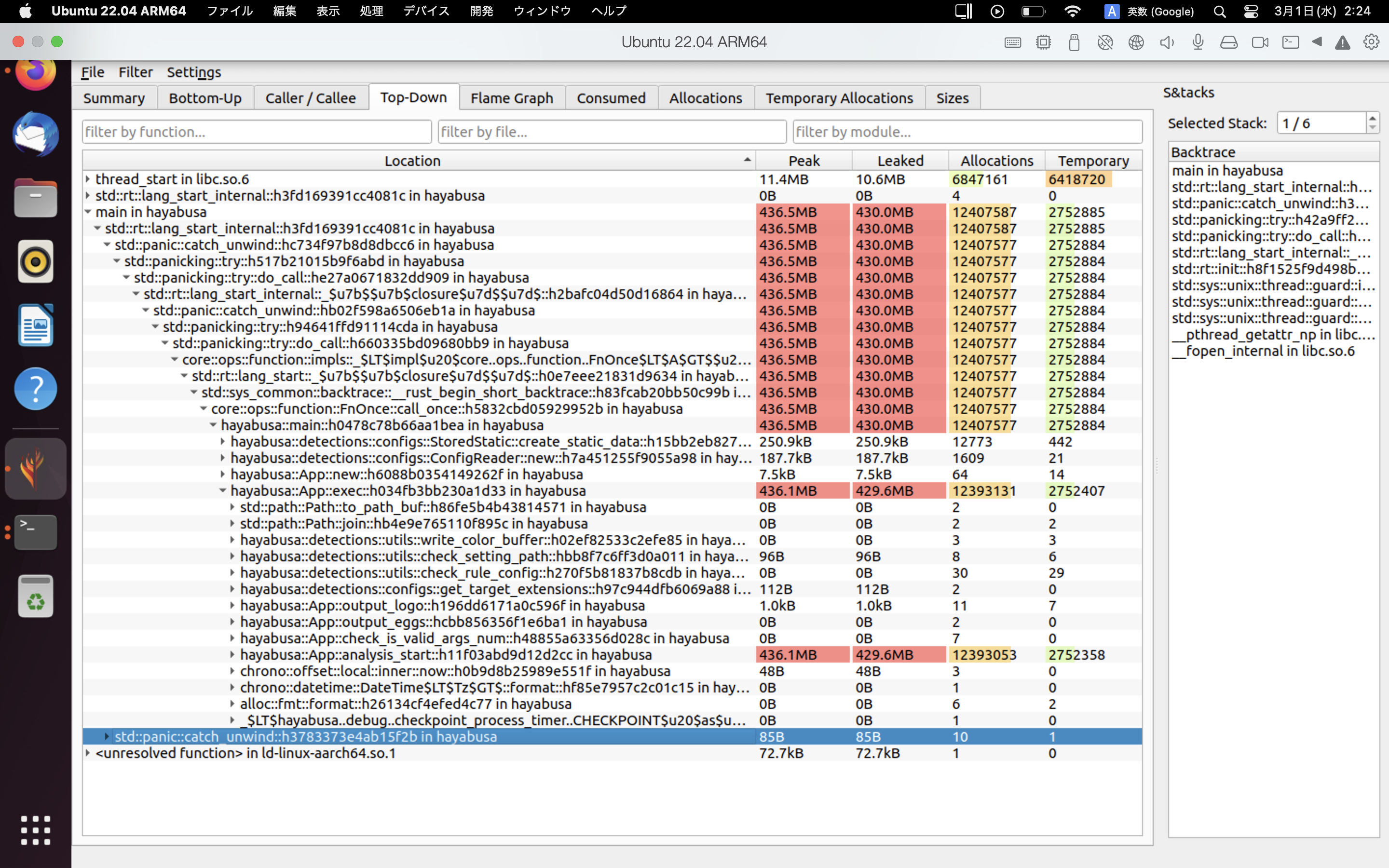
Références¶
Contributions¶
Ce document est basé sur les conclusions tirées de cas d'amélioration réels dans Hayabusa. Si vous trouvez des erreurs ou des techniques qui peuvent améliorer la performance, veuillez nous envoyer une issue ou une pull request.