Timeline Explorer के साथ Hayabusa परिणामों का विश्लेषण¶
परिचय¶
Timeline Explorer एक मुफ्त लेकिन क्लोज्ड-सोर्स टूल है जो DFIR उद्देश्यों के लिए CSV फाइलों का विश्लेषण करते समय Excel का स्थान लेता है। यह एक केवल-Windows GUI टूल है जो C# में लिखा गया है। यह टूल एकल विश्लेषक द्वारा की जाने वाली छोटी जांचों के लिए और उन लोगों के लिए बढ़िया है जो अभी-अभी DFIR विश्लेषण सीखना शुरू कर रहे हैं, हालांकि, इंटरफेस को पहले-पहल समझना कठिन हो सकता है इसलिए कृपया विभिन्न सुविधाओं को समझने के लिए इस गाइड का उपयोग करें।
स्थापना और चलाना¶
एप्लिकेशन को स्थापित करने की कोई आवश्यकता नहीं है।
बस https://ericzimmerman.github.io/#!index.md से नवीनतम संस्करण डाउनलोड करें, उसे अनज़िप करें और TimelineExplorer.exe चलाएं।
यदि आपके पास उपयुक्त .NET रनटाइम नहीं है, तो एक संदेश पॉप अप होगा जो आपको बताएगा कि आपको इसे स्थापित करने की आवश्यकता है।
लेखन के समय (2025/2/14), नवीनतम संस्करण 2.1.0 है जो .NET संस्करण 9 पर चलता है।
CSV फाइल लोड करना¶
CSV फाइल लोड करने के लिए मेनू से बस File -> Open पर क्लिक करें।
आपको कुछ इस तरह दिखाई देगा:
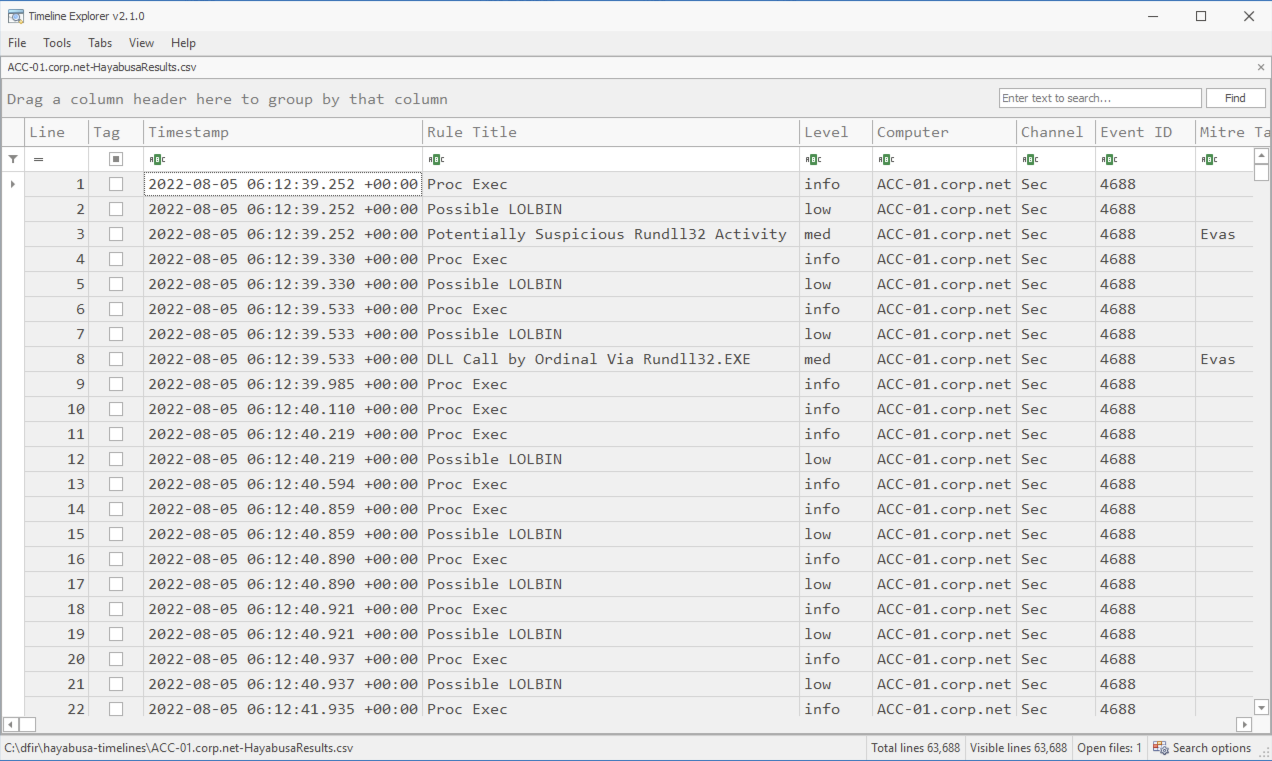
सबसे नीचे, आप फाइल का नाम, Total lines और Visible lines देख सकते हैं।
CSV फाइल में पाए गए कॉलम के अलावा, Timeline Explorer द्वारा बाईं ओर दो कॉलम जोड़े जाते हैं: Line और Tag।
Line लाइन नंबर दिखाता है लेकिन आमतौर पर जांच के लिए उपयोगी नहीं होता, इसलिए आप इस कॉलम को छिपाना चाह सकते हैं।
Tag आपको उन घटनाओं पर चेकमार्क लगाने देता है जिन पर आप बाद में आगे के विश्लेषण आदि के लिए ध्यान देना चाहते हैं...
दुर्भाग्यवश, घटनाओं में कस्टम टैग जोड़ने या घटनाओं के बारे में टिप्पणियाँ लिखने का कोई तरीका नहीं है क्योंकि डेटा को अधिलेखित होने से रोकने के लिए CSV फाइल केवल-पठन मोड में खुलती है।
डेटा फ़िल्टरिंग¶
यदि आप अपने माउस को किसी हेडर के ऊपर-दाएं भाग पर ले जाते हैं, तो आपको एक काला फ़िल्टर आइकन दिखाई देगा।
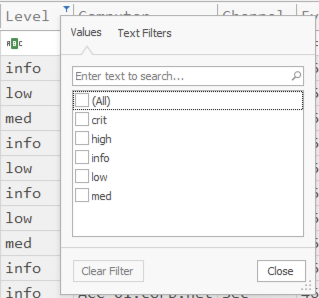
आप पहले high और crit (critical) अलर्ट को ट्राइएज करने के लिए गंभीरता स्तर पर चेकमार्क लगा सकते हैं।
यह फ़िल्टरिंग शोर वाले अलर्ट को फ़िल्टर करने के लिए भी बहुत उपयोगी है, इसके लिए Rule Title के अंतर्गत सब कुछ चेक करके फिर शोर वाले नियमों को अनचेक करें।
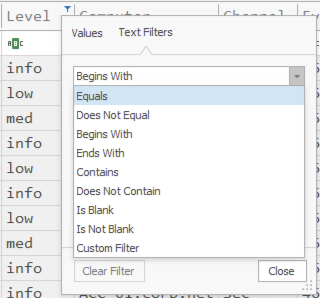
नीचे दिखाए अनुसार, यदि आप Text Filters पर क्लिक करते हैं, तो आप अधिक उन्नत फ़िल्टर बना सकते हैं:
हालांकि यहां फ़िल्टर बनाने के बजाय, आमतौर पर हेडर के नीचे ABC आइकन पर क्लिक करना और यहां फ़िल्टर लागू करना आसान होता है:
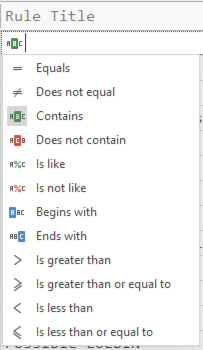
दुर्भाग्यवश, ये दोनों स्थान थोड़े भिन्न फ़िल्टरिंग विकल्प प्रदान करते हैं इसलिए आपको डेटा पर फ़िल्टर करने के लिए दोनों स्थानों के बारे में जागरूक रहना चाहिए।
उदाहरण के लिए, यदि आपके पास बहुत अधिक Proc Exec घटनाएं हैं जिन्हें आप फ़िल्टर करना चाहेंगे, तो आप Does not contain चुन सकते हैं और उन घटनाओं को अनदेखा करने के लिए Proc Exec टाइप कर सकते हैं:
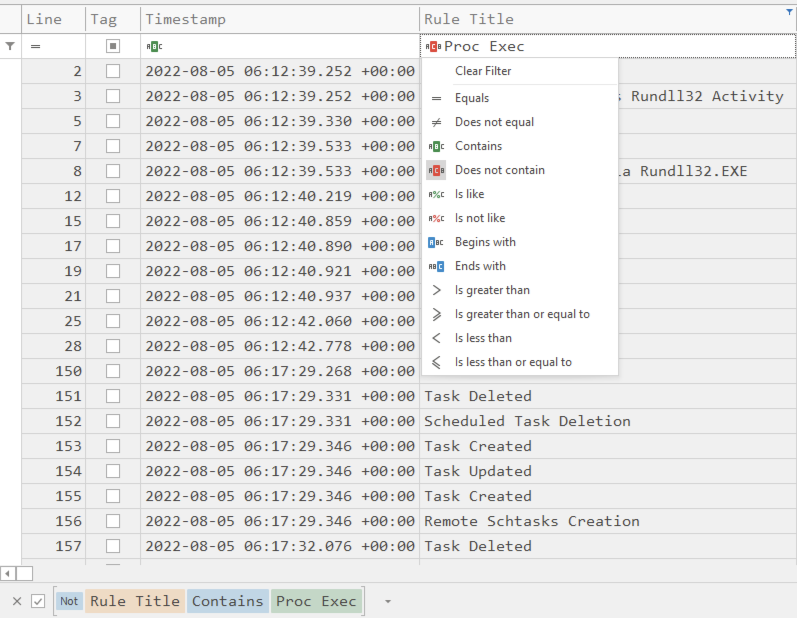
यदि आप नीचे की ओर देखते हैं, तो आप फ़िल्टर का नियम विभिन्न रंगों में देख सकते हैं।
यदि आप अस्थायी रूप से फ़िल्टर को अक्षम करना चाहते हैं, तो बस उसे अनचेक करें।
यदि आप सभी फ़िल्टर साफ करना चाहते हैं, तो X बटन पर क्लिक करें।
यदि आप किसी अन्य शोर वाले नियम को अनदेखा करना चाहते हैं, तो आपको नीचे-दाएं कोने में Edit Filter पर क्लिक करके Filter Editor खोलना चाहिए:
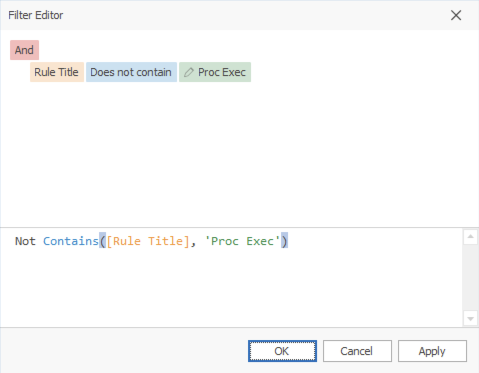
Not Contains([Rule Title], 'Proc Exec') टेक्स्ट को कॉपी करें, and जोड़ें, उसी फ़िल्टर को पेस्ट करें और Proc Exec को Possible LOLBIN में बदलें और अब आप इन दो नियमों को अनदेखा कर सकते हैं:
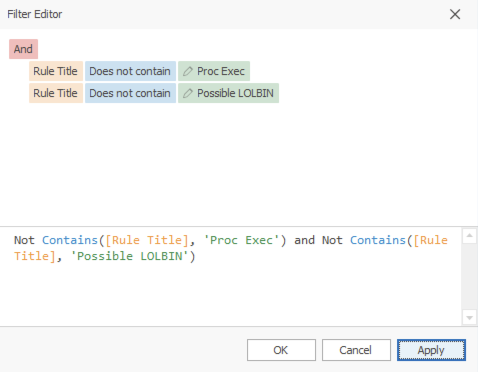
कई फ़िल्टर को संयोजित करने का सबसे आसान तरीका पहले ABC आइकन से फ़िल्टर सिंटैक्स बनाना है, फिर उस टेक्स्ट को कॉपी, पेस्ट और संपादित करना और फ़िल्टरों को and, or और not के साथ संयोजित करना है।
आप अपने फ़िल्टरों को संपादित करने के लिए संभावित विकल्पों का ड्रॉपडाउन बॉक्स पाने के लिए किसी भी रंगीन टेक्स्ट पर भी क्लिक कर सकते हैं:
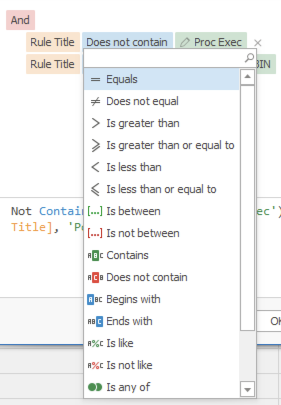
हेडर विकल्प¶
यदि आप किसी भी हेडर पर राइट-क्लिक करते हैं, तो आपको निम्नलिखित विकल्प मिलेंगे:
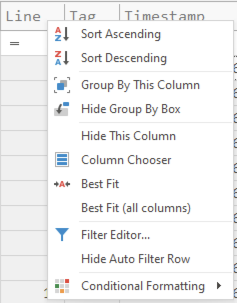
इनमें से अधिकांश विकल्प स्व-व्याख्यात्मक हैं।
- किसी कॉलम को छिपाने के बाद, आप
Column Chooserखोलकर, कॉलम के नाम पर राइट-क्लिक करके औरShow Columnपर क्लिक करके उसे फिर से दिखा सकते हैं। Group By This Columnका वही प्रभाव होता है जो किसी कॉलम हेडर को ऊपर खींचकर समूहित करने का होता है। (बाद में अधिक विस्तार से समझाया गया है।)Hide Group By BoxकेवलDrag a column header here to group by that columnटेक्स्ट को छिपा देगा और सर्च बार को ऊपर ले जाएगा।
सशर्त फ़ॉर्मेटिंग¶
आप Conditional Formatting -> Highlight Cell Rules -> Equal To... पर क्लिक करके टेक्स्ट को रंग, बोल्ड फ़ॉन्ट आदि के साथ फ़ॉर्मेट कर सकते हैं...
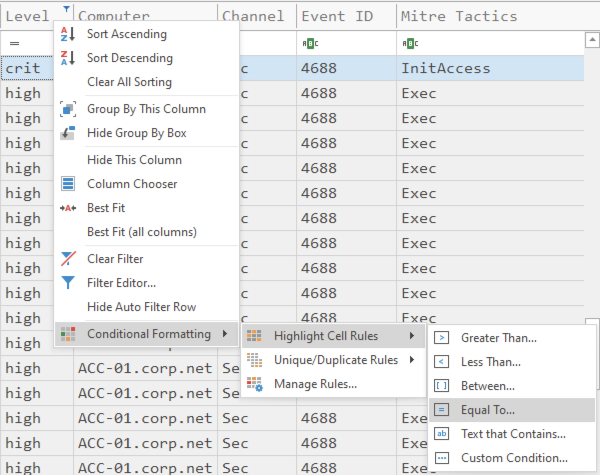
उदाहरण के लिए, यदि आप critical अलर्ट को Red Fill के साथ दिखाना चाहते हैं, तो बस crit टाइप करें और विकल्पों में से Red Fill चुनें, Apply formatting to an entire row चेक करें और OK दबाएं।
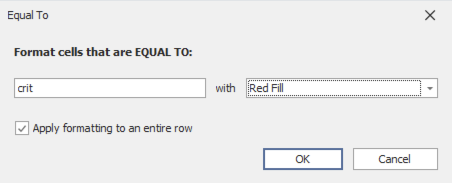
अब critical अलर्ट नीचे दिखाए अनुसार लाल रंग में दिखाई देंगे:

आप low, medium और high अलर्ट के लिए भी रंग जोड़कर ऐसा करना जारी रख सकते हैं।
खोज¶
डिफ़ॉल्ट रूप से, जब आप सर्च बार में कुछ टेक्स्ट टाइप करते हैं, तो यह फ़िल्टरिंग करेगा और केवल वही परिणाम दिखाएगा जिनमें पंक्ति में कहीं वह टेक्स्ट होता है।
आप नीचे Visible lines फ़ील्ड को देखकर पता लगा सकते हैं कि आपके पास कितने हिट हैं।
आप सबसे नीचे दाईं ओर Search options पर क्लिक करके इस व्यवहार को बदल सकते हैं।
इससे निम्नलिखित दिखाई देगा:

यदि आप Behavior को Filter से Search में बदलते हैं तो आप सामान्य रूप से टेक्स्ट खोज सकते हैं।
नोट: व्यवहार को बदलने में आमतौर पर समय लगता है और Timeline Explorer थोड़ी देर के लिए हैंग हो जाएगा, इसलिए क्लिक करने के बाद धैर्य रखें।
डिफ़ॉल्ट Match criteria Mixed है लेकिन इसे Or, And, या Exact में बदला जा सकता है।
यदि आप इसे Mixed के अलावा किसी भी चीज़ में बदलते हैं, तो आप फिर Condition को Contains से Starts with, Like या Equals में सेट कर सकते हैं।
Mixed का Match criteria जटिल है क्योंकि यह कभी-कभी AND लॉजिक का उपयोग करता है और कभी-कभी OR का लेकिन एक बार सीख लेने पर यह बहुत लचीला हो सकता है।
यह इस प्रकार काम करता है:
- यदि आप शब्दों को स्पेस से अलग करते हैं, तो इसे
ORलॉजिक के रूप में माना जाएगा। - यदि आप अपनी खोज में स्पेस शामिल करना चाहते हैं, तो आपको कोट्स जोड़ने की आवश्यकता है।
ANDलॉजिक के लिए किसी कंडीशन के आगे+लगाएं।- परिणामों को बाहर करने के लिए किसी कंडीशन के आगे
-लगाएं। ColumnName:FilterStringफ़ॉर्मेट के साथ किसी विशिष्ट कॉलम पर फ़िल्टर करें।- यदि आप किसी विशिष्ट कॉलम पर फ़िल्टर करते हैं और साथ ही एक अलग कीवर्ड भी शामिल करते हैं, तो यह
ANDलॉजिक होगा।
उदाहरण:
| खोज मानदंड | विवरण |
|---|---|
| mimikatz | उन रिकॉर्ड का चयन करता है जिनमें किसी भी खोज कॉलम में mimikatz स्ट्रिंग होती है। |
| one two three | उन रिकॉर्ड का चयन करता है जिनमें किसी भी खोज कॉलम में one OR two OR three होता है। |
| "hoge hoge" | उन रिकॉर्ड का चयन करता है जिनमें किसी भी खोज कॉलम में hoge hoge होता है। |
| mimikatz +"Bad Guy" | उन रिकॉर्ड का चयन करता है जिनमें किसी भी खोज कॉलम में mimikatz AND Bad Guy दोनों होते हैं। |
| EventID:4624 kali | उन रिकॉर्ड का चयन करता है जिनमें EventID से शुरू होने वाले कॉलम में 4624 होता है AND किसी भी खोज कॉलम में kali होता है। |
| data +entry -mark | उन रिकॉर्ड का चयन करता है जिनमें किसी भी खोज कॉलम में data AND entry दोनों होते हैं, उन रिकॉर्ड को छोड़कर जिनमें mark होता है। |
| manu mask -file | उन रिकॉर्ड का चयन करता है जिनमें menu OR mask होता है, उन रिकॉर्ड को छोड़कर जिनमें file होता है। |
| From:Roller Subj:"currency mask" | उन रिकॉर्ड का चयन करता है जिनमें From से शुरू होने वाले कॉलम में Roller होता है AND Subj से शुरू होने वाले कॉलम में currency mask होता है। |
| import -From:Steve | उन रिकॉर्ड का चयन करता है जिनमें किसी भी खोज कॉलम में import होता है, उन रिकॉर्ड को छोड़कर जिनमें From से शुरू होने वाले कॉलम में Steve होता है। |
कॉलम फ्रीज़ करना¶
हालांकि यह कोई खोज विकल्प नहीं है, आप Search options मेनू के अंतर्गत First scrollable column को कॉन्फ़िगर कर सकते हैं।
अधिकांश विश्लेषक इसे Timestamp पर सेट करेंगे ताकि वे हमेशा देख सकें कि कुछ निश्चित घटनाएं किस समय हुईं।
समूहित करने के लिए कॉलम हेडर खींचना¶
यदि आप किसी कॉलम हेडर को Drag a column header here to group by that column पर खींचते हैं, तो Timeline Explorer उस कॉलम के अनुसार समूहित करेगा।
Level के अनुसार समूहित करना आम है ताकि आप गंभीरता के अनुसार अलर्ट को प्राथमिकता दे सकें:
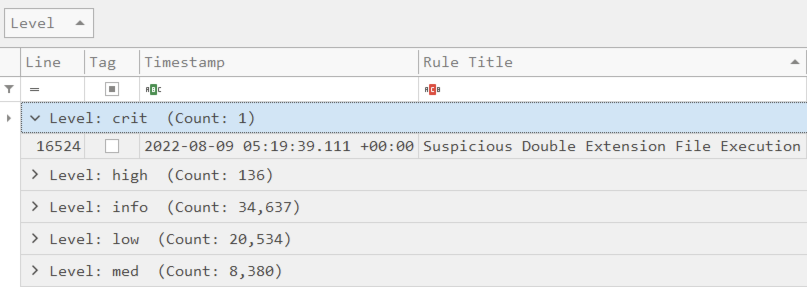
यदि आपके परिणामों में कई कंप्यूटर हैं, तो आप प्रत्येक कंप्यूटर के लिए विभिन्न गंभीरता स्तरों के आधार पर ट्राइएज करने के लिए Computer के अनुसार आगे समूहित कर सकते हैं।
फ़ील्ड जांचना¶
डिफ़ॉल्ट रूप से, Hayabusa फ़ील्ड डेटा को ब्रोकन पाइप प्रतीक: ¦ से अलग करेगा।
जब फ़ील्ड डेटा एक क्षैतिज रेखा पर होता है, तो यह कई फ़ील्ड को अलग करना बहुत आसान बना देता है क्योंकि यह वर्ण लॉग में अक्सर नहीं पाया जाता:

हालांकि, कभी-कभी लॉग में बहुत अधिक फ़ील्ड जानकारी होगी और सब कुछ एक स्क्रीन पर फिट नहीं हो सकता। इस स्थिति में, आप सभी फ़ील्ड जानकारी दिखाने वाला एक पॉप-अप पाने के लिए सेल पर डबल-क्लिक कर सकते हैं:
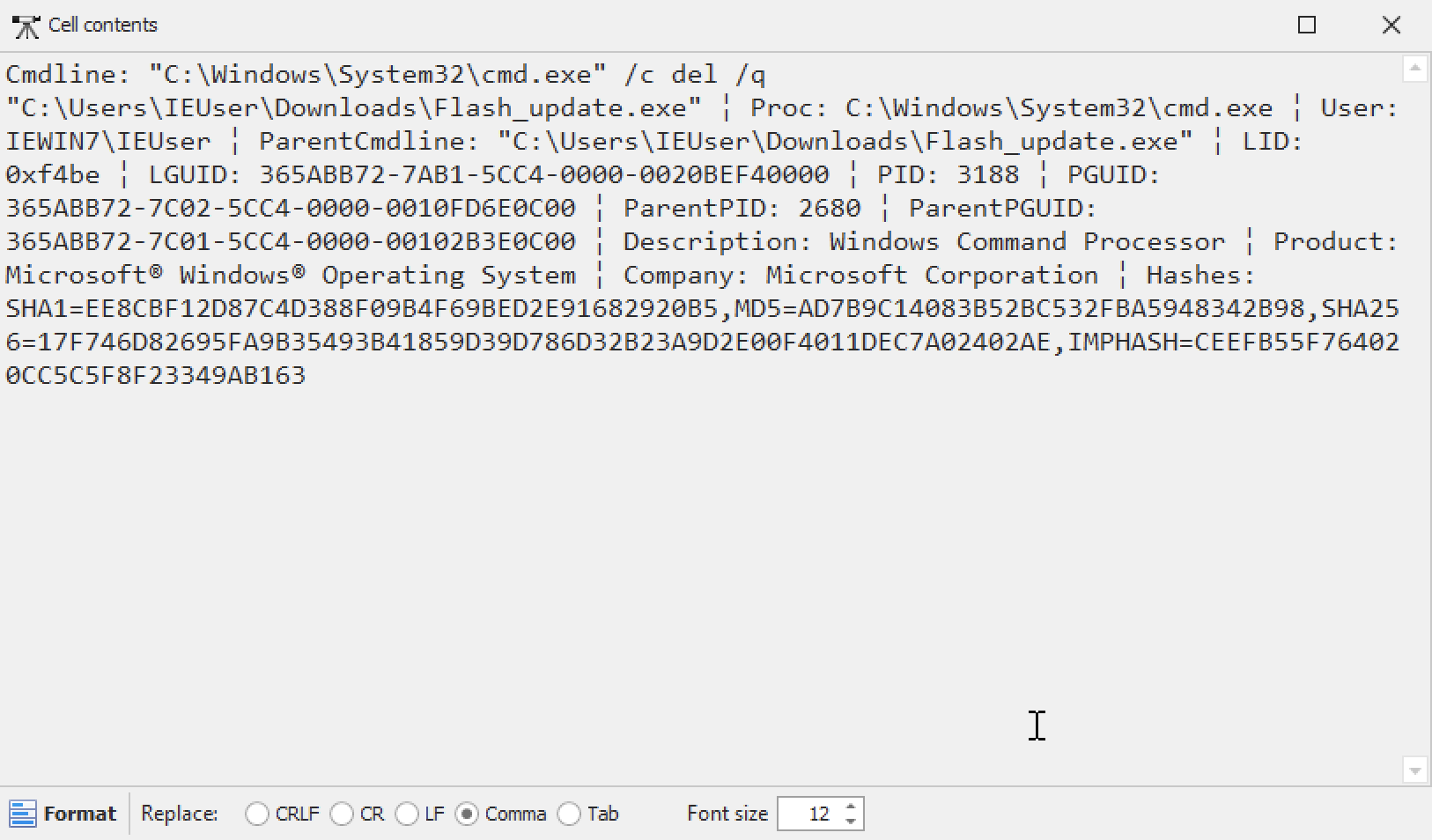
समस्या यह है कि Timeline Explorer आपको फ़ील्ड डेटा को केवल न्यूलाइन वर्णों (CRLF, CR, LF), कॉमा और टैब द्वारा फ़ॉर्मेट करने देता है।
यदि आप -M, --multiline विकल्प का उपयोग करते हैं, तो आप फ़ील्ड को एक न्यूलाइन वर्ण द्वारा अलग कर सकते हैं और जब आप किसी सेल की सामग्री खोलने के लिए डबल-क्लिक करते हैं, तो यह ठीक से फ़ॉर्मेट होगी:
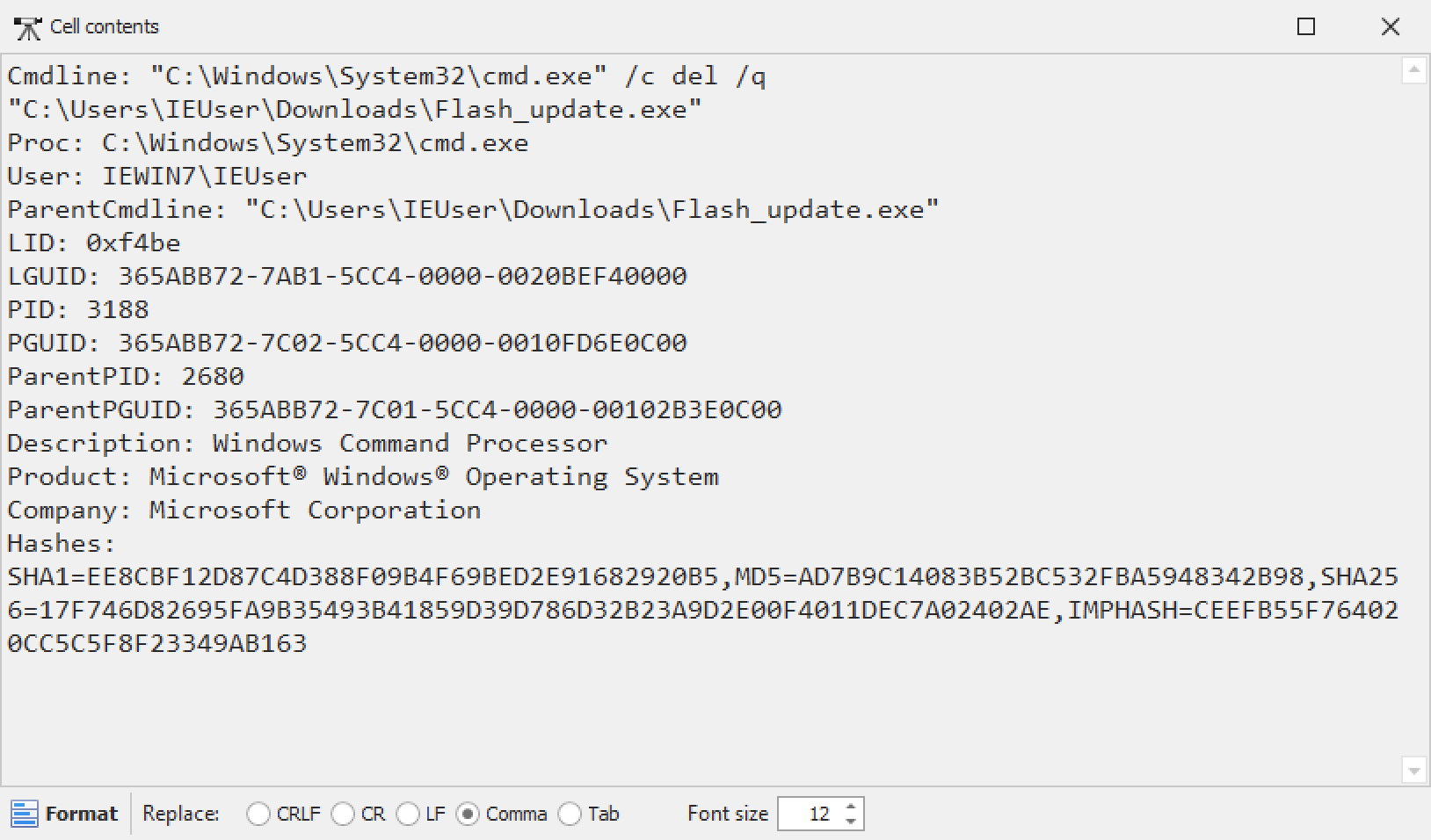
समस्या यह है कि अब टाइमलाइन में केवल पहला फ़ील्ड दिखाई देगा इसलिए जब भी आप अन्य फ़ील्ड डेटा की जांच करना चाहेंगे तो आपको डबल-क्लिक करके एक नई विंडो खोलनी होगी:

दुर्भाग्यवश, Timeline Explorer टाइमलाइन व्यू में कई लाइनों का समर्थन नहीं करता।
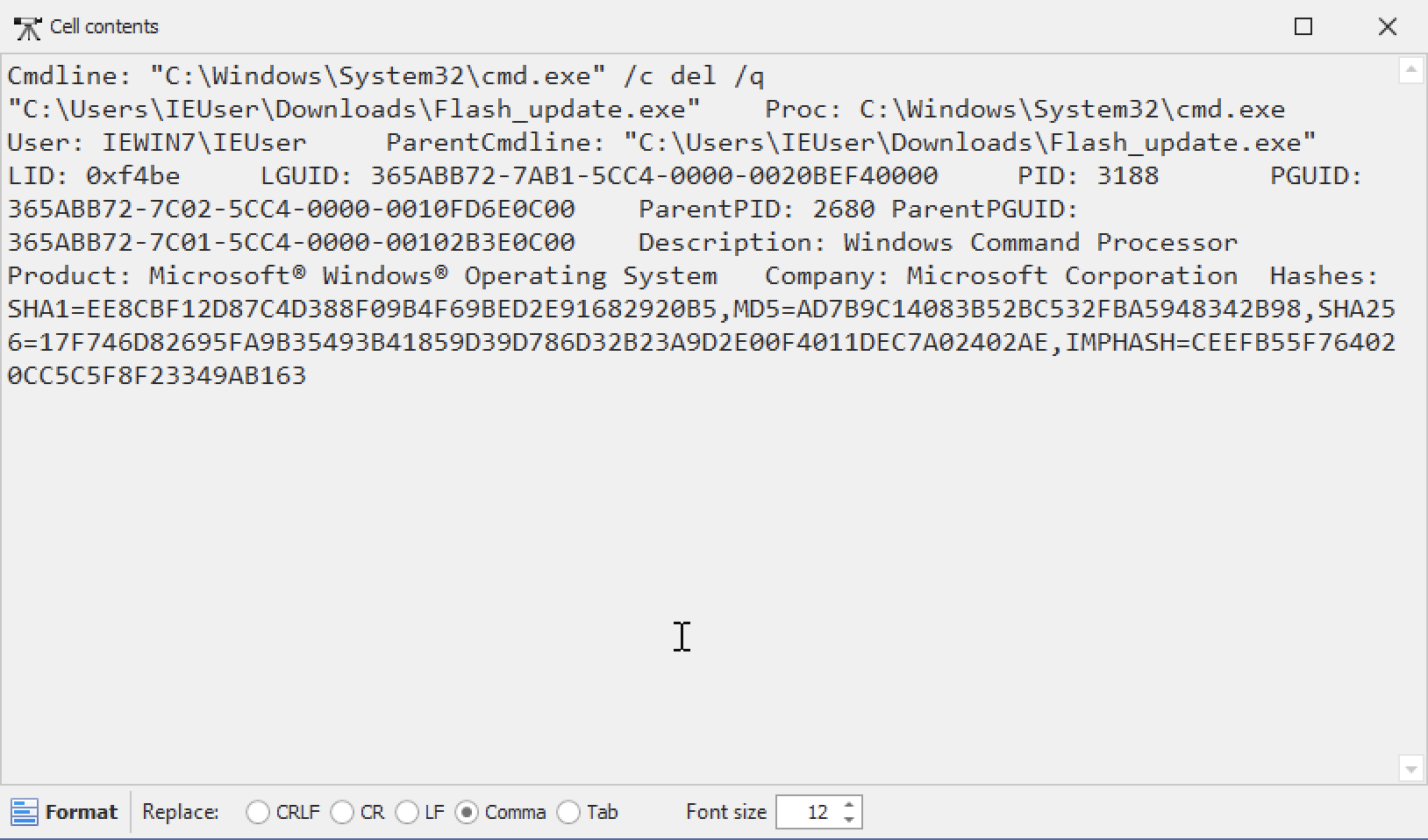
इसके समाधान के रूप में, Hayabusa v3.1.0 के अनुसार, आप फ़ील्ड को टैब द्वारा अलग कर सकते हैं:

यह पहचानना थोड़ा कठिन है कि एक फ़ील्ड कहां समाप्त होता है और अगला कहां शुरू होता है। साथ ही, जब आप डबल-क्लिक करके सेल की सामग्री खोलते हैं तो फ़ील्ड स्वचालित रूप से फ़ॉर्मेट नहीं होते:
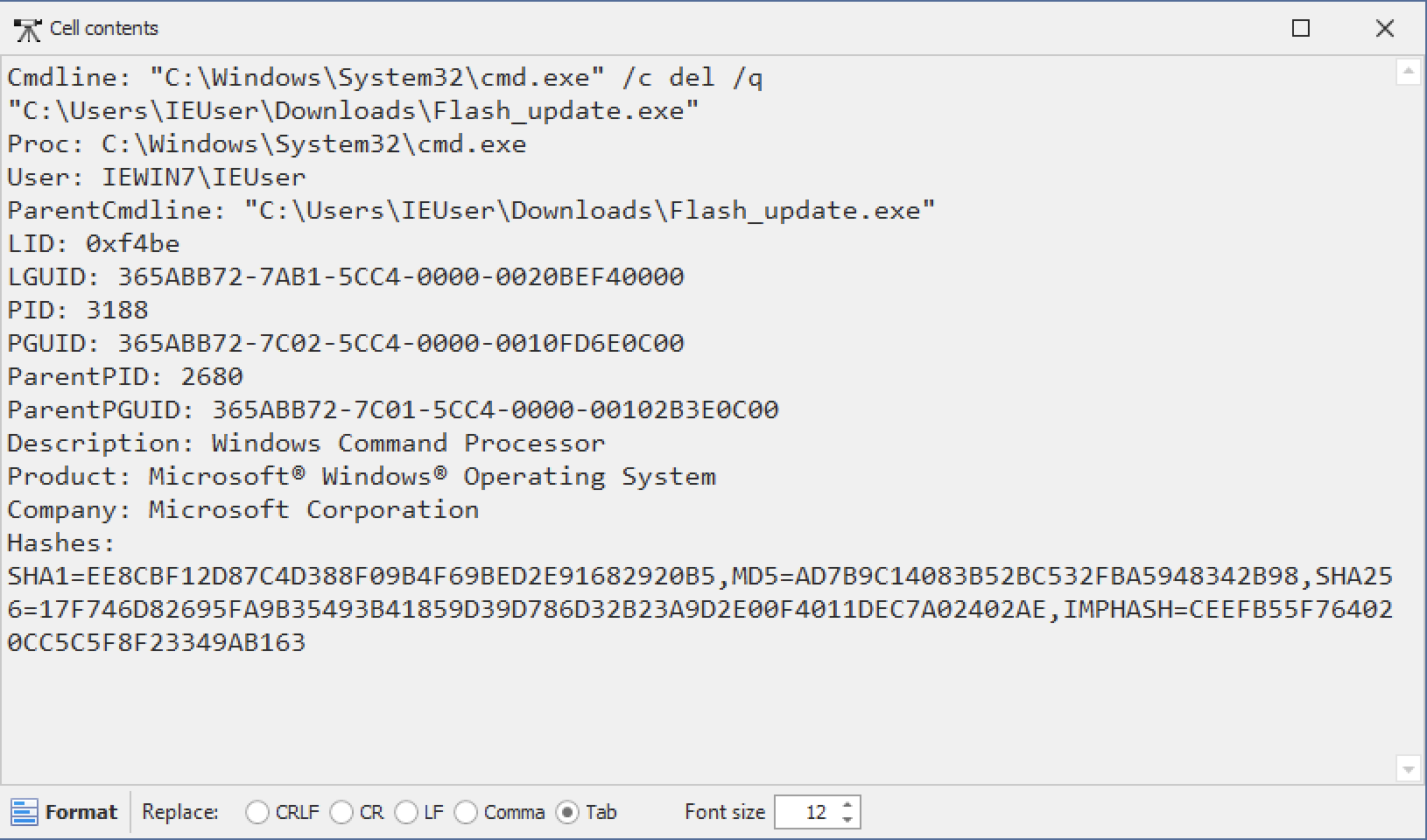
हालांकि, यदि आप नीचे Tab पर क्लिक करते हैं और फिर Format पर, तो आप फ़ील्ड को आसानी से पढ़ने योग्य व्यू में फ़ॉर्मेट कर सकते हैं:
स्किन¶
यदि आप डार्क मोड आदि पसंद करते हैं तो आप Tools -> Skins से रंग थीम बदल सकते हैं...
सेशन¶
यदि आप कॉलम, दिखावट को अनुकूलित करते हैं, फ़िल्टर जोड़ते हैं आदि... और आप उन सेटिंग्स को बाद के लिए सहेजना चाहते हैं, तो File -> Session -> Save से अपना सेशन सहेजना सुनिश्चित करें।