Hayabusa डेवलपर्स के लिए Rust परफ़ॉर्मेंस गाइड¶
लेखक¶
Fukusuke Takahashi
अंग्रेज़ी अनुवाद¶
Zach Mathis (@yamatosecurity)
इस दस्तावेज़ के बारे में¶
Hayabusa (अंग्रेज़ी: "peregrine falcon") जापान के Yamato Security समूह द्वारा विकसित एक तेज़ फ़ोरेंसिक विश्लेषण टूल है। इसे Rust में विकसित किया गया है ताकि यह एक peregrine falcon जितनी तेज़ी से (खतरों का) शिकार कर सके। Rust स्वयं में एक तेज़ भाषा है, हालाँकि, ऐसी कई कमियाँ हैं जिनके परिणामस्वरूप धीमी गति और उच्च मेमोरी उपयोग हो सकता है। हमने यह दस्तावेज़ Hayabusa में वास्तविक परफ़ॉर्मेंस सुधारों के आधार पर बनाया है (यहाँ changelog देखें), लेकिन ये तकनीकें अन्य Rust प्रोग्रामों पर भी लागू होनी चाहिए। हमें आशा है कि आप उस ज्ञान से लाभ उठा सकते हैं जो हमने अपने प्रयोग और त्रुटि के माध्यम से प्राप्त किया है।
गति सुधार¶
मेमोरी आवंटक (allocator) बदलें¶
केवल डिफ़ॉल्ट मेमोरी आवंटक बदलने से गति में काफ़ी सुधार हो सकता है। उदाहरण के लिए, इन benchmarks के अनुसार, निम्नलिखित दो मेमोरी आवंटक
डिफ़ॉल्ट मेमोरी आवंटक की तुलना में बहुत तेज़ हैं। हम अपने मेमोरी आवंटक को jemalloc से mimalloc में बदलकर गति में महत्वपूर्ण सुधार की पुष्टि कर पाए, इसलिए हमने संस्करण 1.8.0 से mimalloc को डिफ़ॉल्ट बना दिया। (हालाँकि mimalloc jemalloc की तुलना में थोड़ी अधिक मेमोरी का उपयोग करता है।)
Before ¶
After ¶
ग्लोबल memory allocator को बदलने के लिए आपको केवल निम्नलिखित 2 चरण निष्पादित करने होंगे:
Cargo.tomlफ़ाइल के [dependencies] section में mimalloc crate जोड़ें:- प्रोग्राम में कहीं #[global_allocator] के अंतर्गत परिभाषित करें कि आप mimalloc का उपयोग करना चाहते हैं: मेमोरी आवंटक बदलने के लिए आपको बस इतना ही करना होगा।
Effectiveness(Real example from a Pull Request) ¶
गति में कितना सुधार होता है यह प्रोग्राम पर निर्भर करेगा, लेकिन निम्नलिखित उदाहरण में
मेमोरी आवंटक को mimalloc में बदलने से Intel CPUs पर 20-30% परफ़ॉर्मेंस वृद्धि हुई। (किसी कारणवश, ARM आधारित macOS डिवाइसों पर इतनी महत्वपूर्ण परफ़ॉर्मेंस वृद्धि नहीं हुई।)
लूप्स में IO प्रोसेसिंग कम करें¶
डिस्क IO प्रोसेसिंग मेमोरी में प्रोसेसिंग की तुलना में बहुत धीमी होती है। इसलिए, विशेष रूप से लूप्स में, IO प्रोसेसिंग से यथासंभव बचना उचित है।
Before ¶
नीचे दिए गए उदाहरण में एक लूप में दस लाख बार फ़ाइल खुलती है:
use std::fs;
fn main() {
for _ in 0..1000000 {
let f = fs::read_to_string("sample.txt").unwrap();
f.len();
}
}
After ¶
निम्नानुसार लूप के बाहर फ़ाइल खोलने से
use std::fs;
fn main() {
let f = fs::read_to_string("sample.txt").unwrap();
for _ in 0..1000000 {
f.len();
}
}
Effectiveness(Real example from a Pull Request) ¶
निम्नलिखित उदाहरण में, एक समय में एक पहचान परिणाम को संभालते समय की IO प्रोसेसिंग को लूप के बाहर निष्पादित किया जा सका:
इसके परिणामस्वरूप लगभग 20% गति सुधार हुआ।
लूप्स में रेगुलर एक्सप्रेशन संकलन से बचें¶
रेगुलर एक्सप्रेशन संकलन, रेगुलर एक्सप्रेशन मैचिंग की तुलना में बहुत महँगी प्रक्रिया है। इसलिए, विशेष रूप से लूप्स में, रेगुलर एक्सप्रेशन संकलन से यथासंभव बचना उचित है।
Before ¶
उदाहरण के लिए, निम्नलिखित प्रक्रिया एक लूप में रेगुलर एक्सप्रेशन मैच करने के 100,000 प्रयास बनाती है:
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..100000 {
if Regex::new(match_str).unwrap().is_match(text){ // Regular expression compilation in a loop
println!("matched!");
}
}
}
After ¶
नीचे दिखाए अनुसार लूप के बाहर रेगुलर एक्सप्रेशन संकलन करने से
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap(); // Compile the regular expression outside the loop
for _ in 0..100000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Effectiveness(Real example from a Pull Request) ¶
निम्नलिखित उदाहरण में, रेगुलर एक्सप्रेशन संकलन लूप के बाहर किया जाता है और कैश किया जाता है।
इसके परिणामस्वरूप महत्वपूर्ण गति सुधार हुए।
बफ़र IO का उपयोग करें¶
बफ़र IO के बिना, फ़ाइल IO धीमी होती है। बफ़र IO के साथ, IO ऑपरेशन मेमोरी में बफ़र्स के माध्यम से किए जाते हैं, जिससे सिस्टम कॉल्स की संख्या कम होती है और गति में सुधार होता है।
Before ¶
उदाहरण के लिए, निम्नलिखित प्रक्रिया में, write 1,000,000 बार होता है।
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
for _ in 0..1000000 {
f.write(b"hello world!");
}
}
After ¶
निम्नानुसार BufWriter का उपयोग करने से
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
let mut writer = BufWriter::new(f);
for _ in 0..1000000 {
writer.write(b"some text");
}
writer.flush().unwrap();
}
Effectiveness(Real example from a Pull Request) ¶
ऊपर वर्णित विधि यहाँ लागू की गई थी
और इसके परिणामस्वरूप आउटपुट प्रोसेसिंग में महत्वपूर्ण गति सुधार हुए हैं।
रेगुलर एक्सप्रेशन के बजाय मानक String विधियों का उपयोग करें¶
हालाँकि रेगुलर एक्सप्रेशन जटिल मैचिंग पैटर्न को कवर कर सकते हैं, वे standard String methods की तुलना में धीमे होते हैं। इसलिए, निम्नलिखित जैसे सरल स्ट्रिंग मैचिंग के लिए मानक String विधियों का उपयोग करना तेज़ है।
- Starts-with मैचिंग(Regex:
foo.*)-> String::starts_with() - Ends-with मैचिंग(Regex:
.*foo)-> String::ends_with() - Contains मैचिंग(Regex:
.*foo.*)-> String::contains()
Before ¶
उदाहरण के लिए, निम्नलिखित कोड एक रेगुलर एक्सप्रेशन में दस लाख बार ends-with मैचिंग करता है।
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = ".*abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
After ¶
निम्नानुसार String::ends_with() का उपयोग करने से
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..1000000 {
if text.ends_with(match_str) {
println!("matched!");
}
}
}
Effectiveness(Real example from a Pull Request) ¶
चूँकि Hayabusa को केस-असंवेदनशील स्ट्रिंग तुलना की आवश्यकता है, हम to_lowercase() का उपयोग करते हैं और फिर उपरोक्त विधि लागू करते हैं। फिर भी, निम्नलिखित उदाहरणों में
- Imporving speed by changing wildcard search process from regular expression match to starts_with/ends_with match #890
- Improving speed by using eq_ignore_ascii_case() before regular expression match #884
पहले की तुलना में गति में लगभग 15% सुधार हुआ है।
स्ट्रिंग की लंबाई के आधार पर फ़िल्टर करें¶
संभाले जा रहे स्ट्रिंग्स की विशेषताओं के आधार पर, एक सरल फ़िल्टर जोड़ने से स्ट्रिंग मैचिंग प्रयासों की संख्या कम हो सकती है और प्रक्रिया तेज़ हो सकती है। यदि आप अक्सर गैर-निश्चित और बेमेल स्ट्रिंग लंबाई वाले स्ट्रिंग्स की तुलना करते हैं, तो आप स्ट्रिंग की लंबाई को प्राथमिक फ़िल्टर के रूप में उपयोग करके प्रक्रिया को तेज़ कर सकते हैं।
Before ¶
उदाहरण के लिए, निम्नलिखित कोड दस लाख रेगुलर एक्सप्रेशन मैच का प्रयास करता है।
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
After ¶
नीचे दिखाए अनुसार String::len() को प्राथमिक फ़िल्टर के रूप में उपयोग करने से
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if text.len() == match_str.len() { // Primary filter by string length
if r.is_match(text) {
println!("matched!");
}
}
}
}
Effectiveness(Real example from a Pull Request) ¶
निम्नलिखित उदाहरण में, उपरोक्त विधि का उपयोग किया गया है।
इससे गति में लगभग 15% सुधार हुआ।
codegen-units=1 के साथ संकलित न करें¶
Rust के साथ परफ़ॉर्मेंस ऑप्टिमाइज़ेशन पर कई लेख [profile.release] सेक्शन के अंतर्गत codegen-units = 1 जोड़ने की सलाह देते हैं।
इससे संकलन समय धीमा हो जाएगा क्योंकि डिफ़ॉल्ट समानांतर रूप से संकलित करना है लेकिन सिद्धांत रूप में इसके परिणामस्वरूप अधिक ऑप्टिमाइज़्ड और तेज़ कोड होना चाहिए।
हालाँकि, हमारे परीक्षण में, इस विकल्प को चालू करने पर Hayabusa वास्तव में धीमा चलता है और संकलन में अधिक समय लगता है इसलिए हम इसे बंद रखते हैं।
निष्पादन योग्य की बाइनरी आकार लगभग 100kb छोटी होती है इसलिए यह एम्बेडेड सिस्टमों के लिए आदर्श हो सकता है जहाँ हार्ड डिस्क स्थान सीमित है।
मेमोरी उपयोग कम करना¶
clone(), to_string(), और to_owned() के अनावश्यक उपयोग से बचें¶
clone() या to_string() का उपयोग ownership से संबंधित संकलन त्रुटियों को हल करने के आसान तरीके हैं। हालाँकि, वे आमतौर पर मेमोरी के उच्च उपयोग का परिणाम होंगे और उनसे बचना चाहिए। हमेशा सबसे पहले यह देखना सबसे अच्छा है कि क्या आप उन्हें कम लागत वाले references से बदल सकते हैं।
Before ¶
उदाहरण के लिए, यदि आप एक ही Vec को कई बार इटरेट करना चाहते हैं, तो आप संकलन त्रुटियों को समाप्त करने के लिए clone() का उपयोग कर सकते हैं।
fn main() {
let lst = vec![1, 2, 3];
for x in lst.clone() { // In order to eliminate compile errors
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
After ¶
हालाँकि, नीचे दिखाए अनुसार references का उपयोग करके, आप clone() का उपयोग करने की आवश्यकता को हटा सकते हैं।
fn main() {
let lst = vec![1, 2, 3];
for x in &lst { // Eliminate compile errors with a reference
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
Effectiveness(Real example from a Pull Request) ¶
निम्नलिखित उदाहरण में, अनावश्यक clone(), to_string(), और to_owned() उपयोग को बदलकर,
हम मेमोरी उपयोग को काफ़ी कम करने में सक्षम हुए।
Vec के बजाय Iterator का उपयोग करें¶
Vec सभी एलिमेंट्स को मेमोरी में रखता है, इसलिए यह एलिमेंट्स की संख्या के अनुपात में बहुत अधिक मेमोरी का उपयोग करता है। यदि एक समय में एक एलिमेंट को प्रोसेस करना पर्याप्त है, तो इसके बजाय एक Iterator का उपयोग करने से बहुत कम मेमोरी का उपयोग होगा।
Before ¶
उदाहरण के लिए, निम्नलिखित return_lines() फ़ंक्शन लगभग 1 GB की एक फ़ाइल पढ़ता है और एक Vec लौटाता है:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> Vec<String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
.collect()
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
After ¶
इसके बजाय आपको निम्नानुसार एक Iterator Trait लौटाना चाहिए:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> impl Iterator<Item=String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
// ここでcollect()せずに、Iteratorを戻り値として返す
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
Box<dyn Iterator<Item = T>> लौटा सकते हैं:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines(need_filter:bool) -> Box<dyn Iterator<Item = String>> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
if need_filter {
let result= buf.lines()
.filter_map(|l| l.ok())
.map(|l| l.replace("A", "B"));
return Box::new(result)
}
let result= buf.lines()
.map(|l| l.expect("Could not parse line"));
Box::new(result)
}
fn main() {
let lines = return_lines(true);
for line in lines {
println!("{}", line)
}
}
Effectiveness(Real example from a Pull Request) ¶
निम्नलिखित उदाहरण ऊपर वर्णित विधि का उपयोग करता है:
जब एक 1.7GB JSON फ़ाइल पर परीक्षण किया गया, तो मेमोरी 75% कम हो गई।
छोटे स्ट्रिंग्स को संभालते समय compact_str crate का उपयोग करें¶
24 बाइट्स से कम के बड़ी संख्या में छोटे स्ट्रिंग्स से निपटते समय, मेमोरी उपयोग कम करने के लिए compact_str crate का उपयोग किया जा सकता है।
Before ¶
नीचे दिए गए उदाहरण में, Vec 1 करोड़ स्ट्रिंग्स रखता है।
fn main() {
let v: Vec<String> = vec![String::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
After ¶
उन्हें एक CompactString से बदलना बेहतर है:
use compact_str::CompactString;
fn main() {
let v: Vec<CompactString> = vec![CompactString::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
Effectiveness(Real example from a Pull Request) ¶
निम्नलिखित उदाहरण में, छोटे स्ट्रिंग्स को CompactString से संभाला जाता है:
इससे मेमोरी उपयोग में लगभग 20% की कमी आई।
दीर्घकालिक संरचनाओं में अनावश्यक फ़ील्ड हटाएँ¶
प्रक्रिया प्रारंभ के दौरान मेमोरी में बनी रहने वाली संरचनाएँ समग्र मेमोरी उपयोग को प्रभावित कर सकती हैं। Hayabusa में, निम्नलिखित संरचनाएँ (संस्करण 2.2.2 के अनुसार), विशेष रूप से, बड़ी संख्या में बनी रहती हैं।
उपरोक्त संरचनाओं से जुड़े फ़ील्ड हटाने से समग्र मेमोरी उपयोग कम करने पर कुछ प्रभाव पड़ा।
Before ¶
उदाहरण के लिए, DetectInfo फ़ील्ड, संस्करण 1.8.1 तक, निम्नलिखित था:
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
pub record_information: CompactString,
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
After ¶
निम्नानुसार record_information फ़ील्ड को हटाकर
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
// remove record_information field
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
Effectiveness(Real example from a Pull Request) ¶
निम्नलिखित उदाहरण में, जब लगभग 15 लाख पहचान परिणाम रिकॉर्ड वाले डेटा पर परीक्षण किया गया,
- Reduced memory usage of DetectInfo/EvtxRecordInfo #837
- Reduce memory usage by removing unnecessary regex #894
हम मेमोरी उपयोग में लगभग 300MB की कमी प्राप्त करने में सक्षम हुए।
बेंचमार्किंग¶
मेमोरी आवंटक के सांख्यिकी फ़ंक्शन का उपयोग करें।¶
कुछ मेमोरी आवंटक अपने स्वयं के मेमोरी उपयोग सांख्यिकी बनाए रखते हैं। उदाहरण के लिए, mimalloc में, मेमोरी उपयोग प्राप्त करने के लिए mi_stats_print_out() फ़ंक्शन को कॉल किया जा सकता है।
सांख्यिकी कैसे प्राप्त करें ¶
पूर्वापेक्षाएँ: आपको mimalloc का उपयोग करना होगा जैसा कि मेमोरी आवंटक बदलें सेक्शन में समझाया गया है।
Cargo.tomlके dependencies section में, libmimalloc-sys crate जोड़ें:- जब भी आप मेमोरी उपयोग सांख्यिकी प्रिंट करना चाहें, निम्नलिखित कोड लिखें और एक
unsafeब्लॉक के अंदर, mi_stats_print_out() को कॉल करें। मेमोरी उपयोग सांख्यिकी standard out पर आउटपुट की जाएगी। -
ऊपरी बाईं ओर का
peak/reservedमान अधिकतम मेमोरी उपयोग है।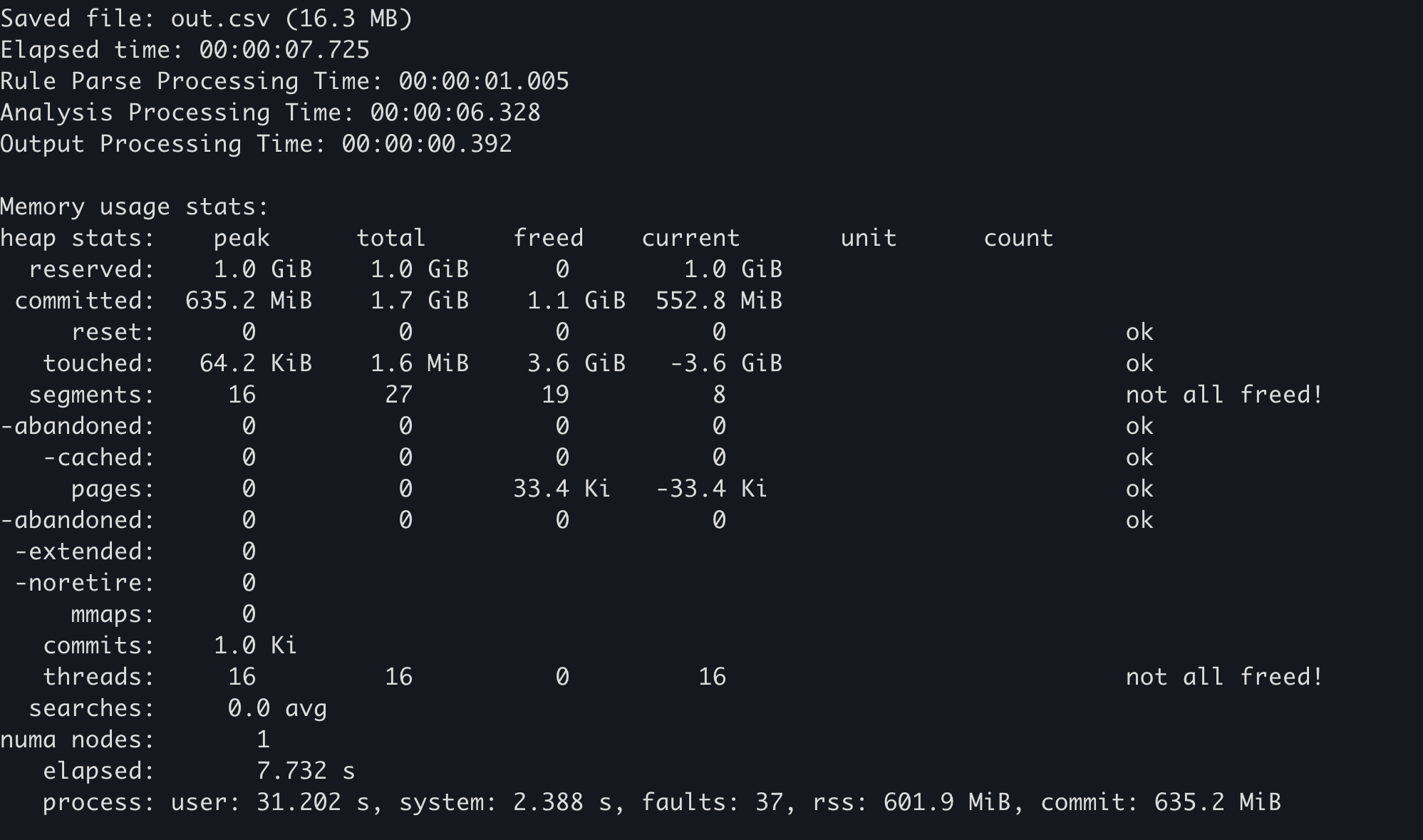
उदाहरण ¶
उपरोक्त कार्यान्वयन निम्नलिखित में लागू किया गया था:
Hayabusa में, यदि आप --debug विकल्प जोड़ते हैं, तो अंत में मेमोरी उपयोग सांख्यिकी आउटपुट की जाएगी।
Windows के परफ़ॉर्मेंस काउंटर का उपयोग करें¶
OS की ओर से प्राप्त की जा सकने वाली सांख्यिकी से विभिन्न संसाधन उपयोग की जाँच की जा सकती है। इस मामले में, निम्नलिखित दो बिंदुओं पर ध्यान देना चाहिए।
- एंटी-वायरस सॉफ़्टवेयर (Windows Defender) से प्रभाव
- केवल पहला रन स्कैन से प्रभावित होता है और धीमा होता है, इसलिए बिल्ड के बाद दूसरे और उसके बाद के रनों के परिणाम तुलना के लिए उपयुक्त हैं। (या अधिक सटीक परिणामों के लिए आप अपना एंटी-वायरस अक्षम कर सकते हैं।)
- फ़ाइल कैशिंग से प्रभाव
- OS स्टार्टअप के बाद दूसरी और उसके बाद की बार के परिणाम पहली बार की तुलना में तेज़ होते हैं क्योंकि evtx और अन्य फ़ाइल IO मेमोरी में फ़ाइल कैश से पढ़े जाते हैं, इसलिए OS बूट होने के बाद पहली बार के परिणाम बेंचमार्क लेने के लिए अधिक आदर्श होते हैं।
कैसे प्राप्त करें ¶
पूर्वापेक्षाएँ:निम्नलिखित प्रक्रिया केवल उन वातावरणों के लिए मान्य है जहाँ Windows पर PowerShell 7 पहले से इंस्टॉल है।
- OS को पुनः आरंभ करें
PowerShell 7का Get-Counter command चलाएँ जो प्रति सेकंड लगातार परफ़ॉर्मेंस काउंटर को एक CSV फ़ाइल में रिकॉर्ड करेगा। (यदि आप नीचे सूचीबद्ध संसाधनों के अलावा अन्य संसाधनों को मापना चाहते हैं, तो यह लेख एक अच्छा संदर्भ है।)- उस प्रक्रिया को निष्पादित करें जिसे आप मापना चाहते हैं।
उदाहरण ¶
निम्नलिखित में Hayabusa के साथ परफ़ॉर्मेंस मापने के लिए एक उदाहरण प्रक्रिया है।
heaptrack का उपयोग करें¶
heaptrack Linux और macOS के लिए उपलब्ध एक परिष्कृत मेमोरी प्रोफ़ाइलर है। heaptrack का उपयोग करके, आप बॉटलनेक्स की पूरी तरह से जाँच कर सकते हैं।
कैसे प्राप्त करें ¶
पूर्वापेक्षाएँ: नीचे Ubuntu 22.04 के लिए प्रक्रिया है। आप Windows पर heaptrack का उपयोग नहीं कर सकते।
- निम्नलिखित दो कमांड्स के साथ heaptrack इंस्टॉल करें।
- Hayabusa से निम्नलिखित mimalloc कोड हटाएँ। (आप mimalloc के साथ heaptrack के मेमोरी प्रोफ़ाइलर का उपयोग नहीं कर सकते।
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L32-L33
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L59-L60
-
https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L632-L634
-
Hayabusa की
Cargo.tomlफ़ाइल में [profile.release] section हटाएँ और इसे निम्नलिखित में बदलें: -
एक रिलीज़ बिल्ड बनाएँ:
cargo build --release heaptrack hayabusa csv-timeline -d sample -o out.csvचलाएँ
अब जब Hayabusa चलना समाप्त कर देगा, तो heaptrack के परिणाम स्वचालित रूप से एक GUI एप्लिकेशन में खुलेंगे।
उदाहरण ¶
heaptrack के परिणामों का एक उदाहरण नीचे दिखाया गया है। Flame Graph और Top-Down टैब आपको उच्च मेमोरी उपयोग वाले फ़ंक्शनों को दृश्य रूप से जाँचने की अनुमति देते हैं।
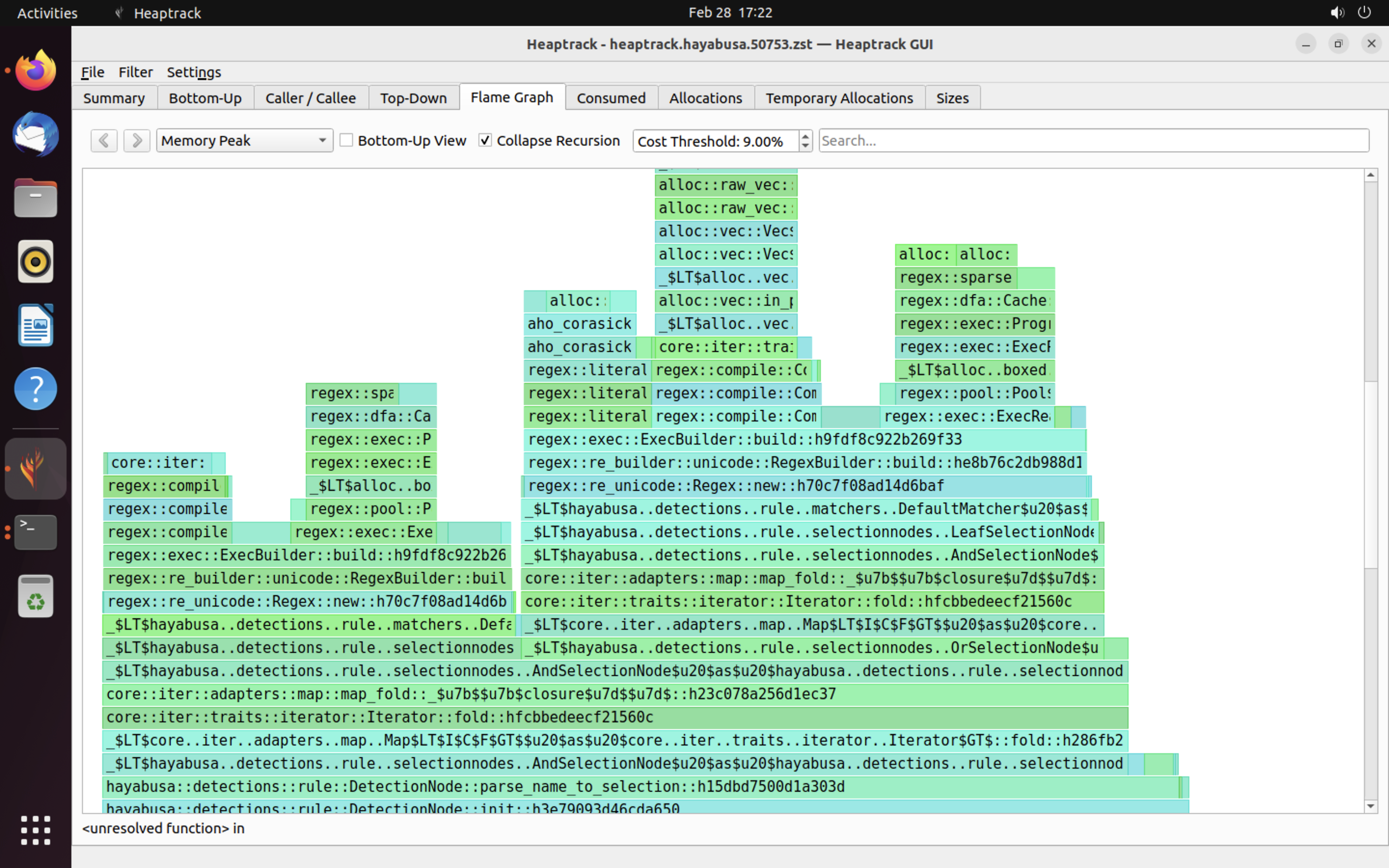
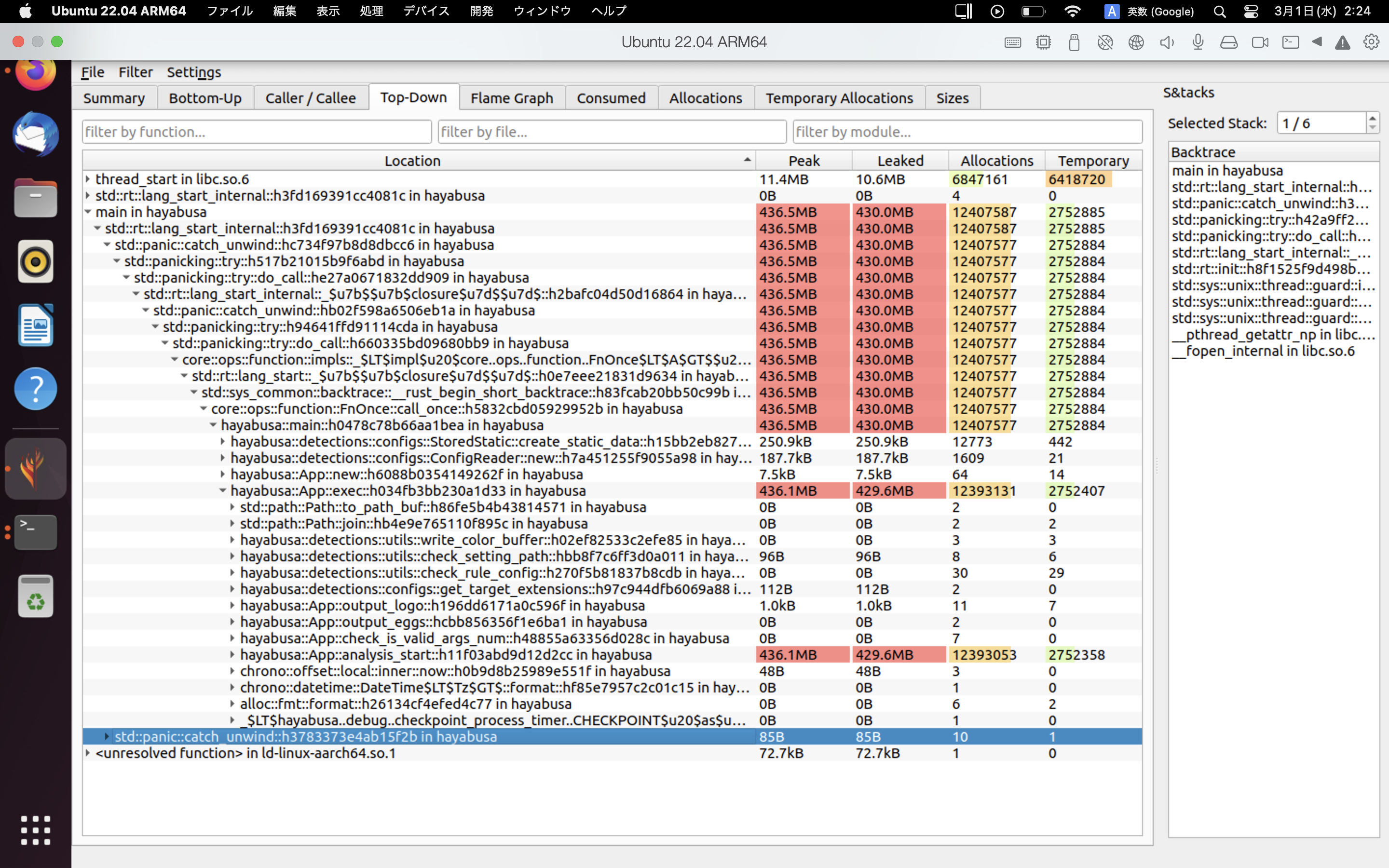
संदर्भ¶
योगदान¶
यह दस्तावेज़ Hayabusa में वास्तविक सुधार मामलों के निष्कर्षों पर आधारित है। यदि आपको कोई त्रुटि या ऐसी तकनीकें मिलती हैं जो परफ़ॉर्मेंस में सुधार कर सकती हैं, तो कृपया हमें एक issue या pull request भेजें।