Hayabusa Geliştiricileri için Rust Performans Kılavuzu¶
Yazar¶
Fukusuke Takahashi
İngilizce çeviri¶
Zach Mathis (@yamatosecurity)
Bu belge hakkında¶
Hayabusa (Türkçe: "gökdoğan"), Japonya'daki Yamato Security grubu tarafından geliştirilen hızlı bir adli analiz aracıdır. Bir gökdoğan kadar hızlı (tehdit) avlamak amacıyla Rust ile geliştirilmiştir. Rust kendi başına hızlı bir dildir, ancak yavaş hızlara ve yüksek bellek kullanımına yol açabilecek birçok tuzak vardır. Bu belgeyi Hayabusa'daki gerçek performans iyileştirmelerine dayanarak oluşturduk (bkz. buradaki değişiklik günlüğü), ancak bu teknikler diğer Rust programlarına da uygulanabilir olmalıdır. Deneme yanılma yoluyla edindiğimiz bilgilerden yararlanabileceğinizi umuyoruz.
Hız iyileştirmesi¶
Bellek ayırıcıyı değiştirin¶
Varsayılan bellek ayırıcıyı değiştirmek tek başına hızı önemli ölçüde artırabilir. Örneğin, bu karşılaştırmalara göre, aşağıdaki iki bellek ayırıcı
varsayılan bellek ayırıcıdan çok daha hızlıdır. Bellek ayırıcımızı jemalloc'tan mimalloc'a değiştirerek önemli bir hız iyileştirmesi doğrulayabildik, bu yüzden 1.8.0 sürümünden itibaren mimalloc'u varsayılan yaptık. (Her ne kadar mimalloc, jemalloc'tan biraz daha fazla bellek kullansa da.)
Before ¶
After ¶
Global bellek ayırıcıyı değiştirmek için yalnızca aşağıdaki 2 adımı gerçekleştirmeniz gerekir:
- mimalloc crate'ini
Cargo.tomldosyasının [dependencies] bölümüne ekleyin: - Programın bir yerinde #[global_allocator] altında mimalloc kullanmak istediğinizi tanımlayın: Bellek ayırıcıyı değiştirmek için yapmanız gereken tek şey budur.
Effectiveness(Real example from a Pull Request) ¶
Hızın ne kadar iyileşeceği programa bağlı olacaktır, ancak aşağıdaki örnekte
bellek ayırıcıyı mimalloc olarak değiştirmek, Intel CPU'larda %20-30'luk bir performans artışıyla sonuçlandı. (Nedense, ARM tabanlı macOS cihazlarında bu kadar önemli bir performans artışı olmadı.)
Döngülerdeki IO işlemlerini azaltın¶
Disk IO işlemleri, bellekteki işlemlerden çok daha yavaştır. Bu nedenle, özellikle döngülerde, IO işlemlerinden mümkün olduğunca kaçınmak arzu edilir.
Before ¶
Aşağıdaki örnek, bir döngüde bir milyon kez gerçekleşen bir dosya açma işlemini göstermektedir:
use std::fs;
fn main() {
for _ in 0..1000000 {
let f = fs::read_to_string("sample.txt").unwrap();
f.len();
}
}
After ¶
Dosyayı aşağıdaki gibi döngünün dışında açarak
use std::fs;
fn main() {
let f = fs::read_to_string("sample.txt").unwrap();
for _ in 0..1000000 {
f.len();
}
}
Effectiveness(Real example from a Pull Request) ¶
Aşağıdaki örnekte, her seferinde bir algılama sonucu işlenirken yapılan IO işlemi, döngünün dışında gerçekleştirilebildi:
Bu, yaklaşık %20'lik bir hız iyileştirmesiyle sonuçlandı.
Döngülerde düzenli ifade derlemesinden kaçının¶
Düzenli ifade derlemesi, düzenli ifade eşleştirmesine kıyasla çok maliyetli bir işlemdir. Bu nedenle, özellikle döngülerde, düzenli ifade derlemesinden mümkün olduğunca kaçınmak tavsiye edilir.
Before ¶
Örneğin, aşağıdaki işlem bir döngüde bir düzenli ifadeyi eşleştirmek için 100.000 deneme oluşturur:
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..100000 {
if Regex::new(match_str).unwrap().is_match(text){ // Regular expression compilation in a loop
println!("matched!");
}
}
}
After ¶
Aşağıda gösterildiği gibi düzenli ifade derlemesini döngünün dışında yaparak
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap(); // Compile the regular expression outside the loop
for _ in 0..100000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Effectiveness(Real example from a Pull Request) ¶
Aşağıdaki örnekte, düzenli ifade derlemesi döngünün dışında gerçekleştirilir ve önbelleğe alınır.
Bu, önemli hız iyileştirmeleriyle sonuçlandı.
Tampon IO kullanın¶
Tampon IO olmadan, dosya IO'su yavaştır. Tampon IO ile, IO işlemleri bellekteki tamponlar aracılığıyla gerçekleştirilir, bu da sistem çağrılarının sayısını azaltır ve hızı artırır.
Before ¶
Örneğin, aşağıdaki işlemde write 1.000.000 kez gerçekleşir.
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
for _ in 0..1000000 {
f.write(b"hello world!");
}
}
After ¶
BufWriter kullanarak aşağıdaki gibi
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
let mut writer = BufWriter::new(f);
for _ in 0..1000000 {
writer.write(b"some text");
}
writer.flush().unwrap();
}
Effectiveness(Real example from a Pull Request) ¶
Yukarıda açıklanan yöntem burada uygulandı
ve çıktı işlemede önemli hız iyileştirmeleriyle sonuçlandı.
Düzenli ifadeler yerine standart String yöntemlerini kullanın¶
Düzenli ifadeler karmaşık eşleştirme desenlerini kapsayabilse de, standart String yöntemlerinden daha yavaştırlar. Bu nedenle, aşağıdaki gibi basit dize eşleştirmesi için standart String yöntemlerini kullanmak daha hızlıdır.
- Başlangıç eşleştirmesi(Regex:
foo.*)-> String::starts_with() - Bitiş eşleştirmesi(Regex:
.*foo)-> String::ends_with() - İçerme eşleştirmesi(Regex:
.*foo.*)-> String::contains()
Before ¶
Örneğin, aşağıdaki kod bir düzenli ifadede bir milyon kez bitiş eşleştirmesi gerçekleştirir.
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = ".*abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
After ¶
String::ends_with() kullanarak aşağıdaki gibi
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..1000000 {
if text.ends_with(match_str) {
println!("matched!");
}
}
}
Effectiveness(Real example from a Pull Request) ¶
Hayabusa, büyük/küçük harfe duyarsız dize karşılaştırması gerektirdiğinden, to_lowercase() kullanır ve ardından yukarıdaki yöntemi uygularız. O zaman bile, aşağıdaki örneklerde
- Imporving speed by changing wildcard search process from regular expression match to starts_with/ends_with match #890
- Improving speed by using eq_ignore_ascii_case() before regular expression match #884
hız öncesine kıyasla yaklaşık %15 iyileşti.
Dize uzunluğuna göre filtreleyin¶
İşlenen dizelerin özelliklerine bağlı olarak, basit bir filtre eklemek dize eşleştirme denemelerinin sayısını azaltabilir ve işlemi hızlandırabilir. Sabit olmayan ve eşleşmeyen dize uzunluklarına sahip dizeleri sık sık karşılaştırıyorsanız, dize uzunluğunu birincil filtre olarak kullanarak işlemi hızlandırabilirsiniz.
Before ¶
Örneğin, aşağıdaki kod bir milyon düzenli ifade eşleştirmesi dener.
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
After ¶
Aşağıda gösterildiği gibi String::len() kullanarak birincil filtre olarak
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if text.len() == match_str.len() { // Primary filter by string length
if r.is_match(text) {
println!("matched!");
}
}
}
}
Effectiveness(Real example from a Pull Request) ¶
Aşağıdaki örnekte yukarıdaki yöntem kullanılmaktadır.
Bu, hızı yaklaşık %15 iyileştirdi.
codegen-units=1 ile derlemeyin¶
Rust ile performans optimizasyonu hakkındaki birçok makale, [profile.release] bölümü altına codegen-units = 1 eklemeyi tavsiye eder.
Varsayılan olarak paralel derleme yapıldığından bu, daha yavaş derleme sürelerine neden olur, ancak teorik olarak daha optimize ve daha hızlı kodla sonuçlanmalıdır.
Ancak, testlerimizde Hayabusa aslında bu seçenek açıkken daha yavaş çalışır ve derleme daha uzun sürer, bu yüzden bunu kapalı tutuyoruz.
Yürütülebilir dosyanın ikili boyutu yaklaşık 100kb daha küçüktür, bu yüzden bu, sabit disk alanının sınırlı olduğu gömülü sistemler için ideal olabilir.
Bellek kullanımını azaltma¶
clone(), to_string() ve to_owned() öğelerinin gereksiz kullanımından kaçının¶
clone() veya to_string() kullanmak, sahiplik ile ilgili derleme hatalarını çözmenin kolay yollarıdır. Ancak, genellikle yüksek bellek kullanımına neden olurlar ve bunlardan kaçınılmalıdır. Önce onları düşük maliyetli referanslarla değiştirip değiştiremeyeceğinizi görmek her zaman en iyisidir.
Before ¶
Örneğin, aynı Vec üzerinde birden çok kez yineleme yapmak istiyorsanız, derleme hatalarını ortadan kaldırmak için clone() kullanabilirsiniz.
fn main() {
let lst = vec![1, 2, 3];
for x in lst.clone() { // In order to eliminate compile errors
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
After ¶
Ancak, aşağıda gösterildiği gibi referanslar kullanarak, clone() kullanma ihtiyacını ortadan kaldırabilirsiniz.
fn main() {
let lst = vec![1, 2, 3];
for x in &lst { // Eliminate compile errors with a reference
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
Effectiveness(Real example from a Pull Request) ¶
Aşağıdaki örnekte, gereksiz clone(), to_string() ve to_owned() kullanımını değiştirerek,
bellek kullanımını önemli ölçüde azaltabildik.
Vec yerine Iterator kullanın¶
Vec tüm öğeleri bellekte tutar, bu yüzden öğe sayısıyla orantılı olarak çok fazla bellek kullanır. Bir seferde bir öğeyi işlemek yeterliyse, bunun yerine bir Iterator kullanmak çok daha az bellek kullanacaktır.
Before ¶
Örneğin, aşağıdaki return_lines() fonksiyonu yaklaşık 1 GB'lık bir dosyayı okur ve bir Vec döndürür:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> Vec<String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
.collect()
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
After ¶
Bunun yerine aşağıdaki gibi bir Iterator Trait döndürmelisiniz:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> impl Iterator<Item=String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
// ここでcollect()せずに、Iteratorを戻り値として返す
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
Box<dyn Iterator<Item = T>> döndürebilirsiniz:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines(need_filter:bool) -> Box<dyn Iterator<Item = String>> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
if need_filter {
let result= buf.lines()
.filter_map(|l| l.ok())
.map(|l| l.replace("A", "B"));
return Box::new(result)
}
let result= buf.lines()
.map(|l| l.expect("Could not parse line"));
Box::new(result)
}
fn main() {
let lines = return_lines(true);
for line in lines {
println!("{}", line)
}
}
Effectiveness(Real example from a Pull Request) ¶
Aşağıdaki örnek yukarıda açıklanan yöntemi kullanır:
1.7GB'lık bir JSON dosyası üzerinde test edildiğinde, bellek %75 azaldı.
Kısa dizeleri işlerken compact_str crate'ini kullanın¶
24 bayttan az olan çok sayıda kısa dizeyle uğraşırken, bellek kullanımını azaltmak için compact_str crate'i kullanılabilir.
Before ¶
Aşağıdaki örnekte, Vec 10 milyon dize tutar.
fn main() {
let v: Vec<String> = vec![String::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
After ¶
Onları bir CompactString ile değiştirmek daha iyidir:
use compact_str::CompactString;
fn main() {
let v: Vec<CompactString> = vec![CompactString::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
Effectiveness(Real example from a Pull Request) ¶
Aşağıdaki örnekte, kısa dizeler CompactString ile işlenir:
Bu, bellek kullanımında yaklaşık %20'lik bir azalma sağladı.
Uzun ömürlü yapılarda gereksiz alanları silin¶
İşlem başlatma sırasında bellekte tutulmaya devam eden yapılar, genel bellek kullanımını etkileyebilir. Hayabusa'da, özellikle aşağıdaki yapılar (2.2.2 sürümü itibarıyla) çok sayıda tutulur.
Yukarıdaki yapılarla ilişkili alanların kaldırılması, genel bellek kullanımını azaltmada bir miktar etkili oldu.
Before ¶
Örneğin, DetectInfo alanı, 1.8.1 sürümüne kadar şöyleydi:
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
pub record_information: CompactString,
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
After ¶
record_information alanını aşağıdaki gibi silerek
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
// remove record_information field
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
Effectiveness(Real example from a Pull Request) ¶
Aşağıdaki örnekte, algılama sonucu kayıtlarının sayısının yaklaşık 1,5 milyon olduğu veriler üzerinde test edildiğinde,
- Reduced memory usage of DetectInfo/EvtxRecordInfo #837
- Reduce memory usage by removing unnecessary regex #894
bellek kullanımında yaklaşık 300MB'lık bir azalma elde edebildik.
Karşılaştırmalı değerlendirme (Benchmarking)¶
Bellek ayırıcının istatistik fonksiyonunu kullanın.¶
Bazı bellek ayırıcılar kendi bellek kullanım istatistiklerini tutar. Örneğin, mimalloc içinde, bellek kullanımını elde etmek için mi_stats_print_out() fonksiyonu çağrılabilir.
İstatistikler nasıl elde edilir ¶
Önkoşullar: Bellek ayırıcıyı değiştirin bölümünde açıklandığı gibi mimalloc kullanıyor olmanız gerekir.
Cargo.toml'un dependencies bölümünde, libmimalloc-sys crate'ini ekleyin:- Bellek kullanım istatistiklerini yazdırmak istediğiniz her yerde, aşağıdaki kodu yazın ve bir
unsafebloğu içinde mi_stats_print_out() öğesini çağırın. Bellek kullanım istatistikleri standart çıktıya gönderilecektir. -
Sol üstteki
peak/reserveddeğeri maksimum bellek kullanımıdır.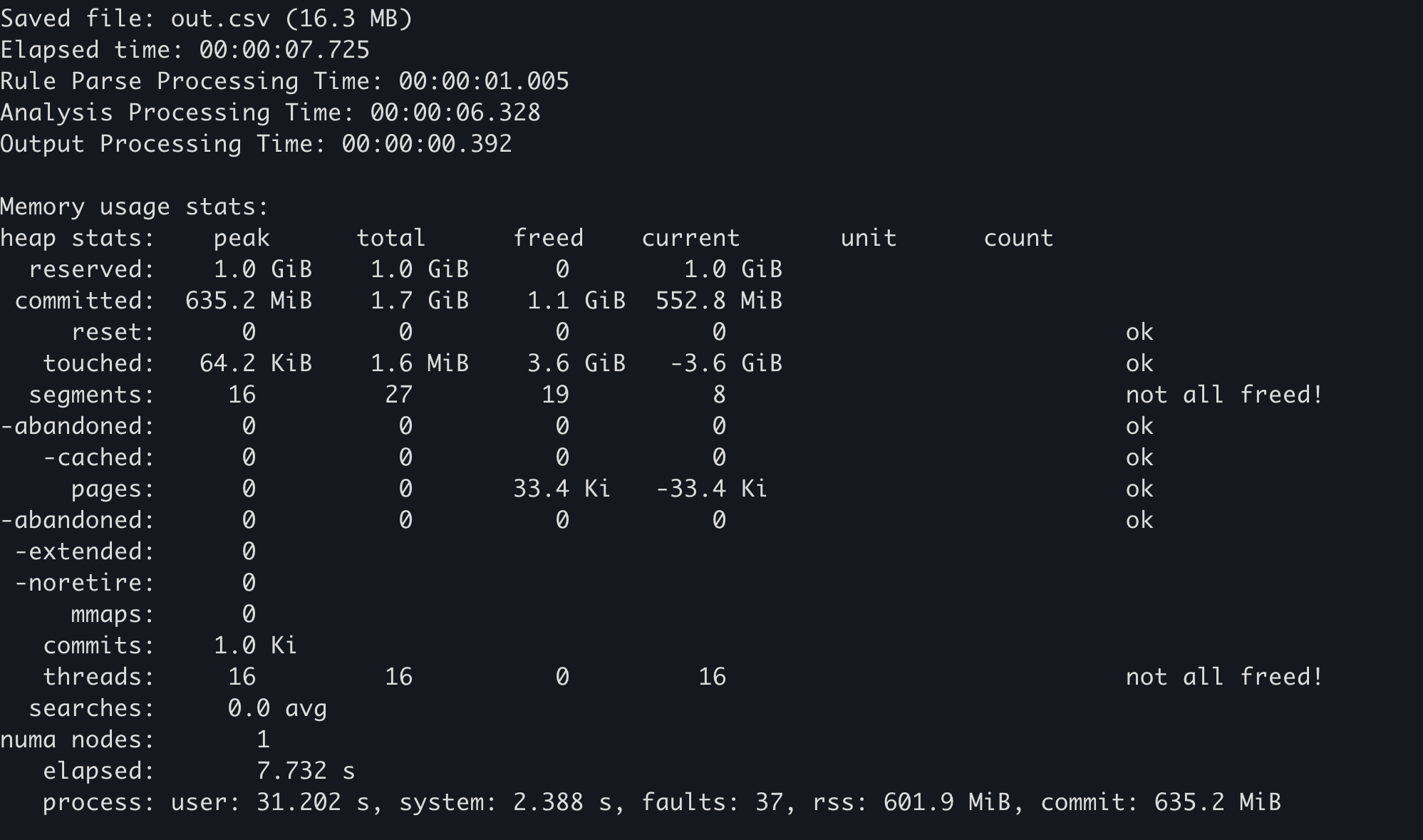
Örnek ¶
Yukarıdaki uygulama aşağıdakinde uygulandı:
Hayabusa'da, --debug seçeneğini eklerseniz, bellek kullanım istatistikleri sonunda gönderilecektir.
Windows'un performans sayacını kullanın¶
İşletim sistemi tarafında elde edilebilen istatistiklerden çeşitli kaynak kullanımları kontrol edilebilir. Bu durumda, aşağıdaki iki noktaya dikkat edilmelidir.
- Anti-virüs yazılımının (Windows Defender) etkisi
- Yalnızca ilk çalıştırma taramadan etkilenir ve daha yavaştır, bu yüzden derlemeden sonraki ikinci ve sonraki çalıştırmaların sonuçları karşılaştırma için uygundur. (Veya daha doğru sonuçlar için anti-virüsünüzü devre dışı bırakabilirsiniz.)
- Dosya önbelleğinin etkisi
- İşletim sistemi başlatıldıktan sonraki ikinci ve sonraki zamanların sonuçları, evtx ve diğer dosya IO'ları bellekteki dosya önbelleğinden okunduğundan ilk seferden daha hızlıdır, bu yüzden işletim sistemi başlatıldıktan sonraki ilk seferin sonuçları karşılaştırmalı değerlendirme yapmak için daha idealdir.
Nasıl elde edilir ¶
Önkoşullar:Aşağıdaki prosedür yalnızca Windows'ta PowerShell 7'nin zaten kurulu olduğu ortamlar için geçerlidir.
- İşletim sistemini yeniden başlatın
- Performans sayacını her saniye sürekli olarak bir CSV dosyasına kaydedecek olan
PowerShell 7'nin Get-Counter komutunu çalıştırın. (Aşağıda listelenenlerin dışındaki kaynakları ölçmek isterseniz, bu makale iyi bir referanstır.) - Ölçmek istediğiniz işlemi yürütün.
Örnek ¶
Aşağıda, Hayabusa ile performans ölçümü yapmak için örnek bir prosedür yer almaktadır.
heaptrack kullanın¶
heaptrack, Linux ve macOS için kullanılabilen gelişmiş bir bellek profil oluşturucudur. heaptrack kullanarak, darboğazları kapsamlı bir şekilde araştırabilirsiniz.
Nasıl elde edilir ¶
Önkoşullar: Aşağıda Ubuntu 22.04 için prosedür yer almaktadır. heaptrack'i Windows'ta kullanamazsınız.
- heaptrack'i aşağıdaki iki komutla kurun.
- Hayabusa'dan aşağıdaki mimalloc kodunu kaldırın. (heaptrack'in bellek profil oluşturucusunu mimalloc ile kullanamazsınız.
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L32-L33
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L59-L60
-
https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L632-L634
-
Hayabusa'nın
Cargo.tomldosyasındaki [profile.release] bölümünü silin ve aşağıdaki gibi değiştirin: -
Bir release derlemesi oluşturun:
cargo build --release heaptrack hayabusa csv-timeline -d sample -o out.csvçalıştırın
Artık Hayabusa çalışmayı bitirdiğinde, heaptrack'in sonuçları otomatik olarak bir GUI uygulamasında açılacaktır.
Örnekler ¶
heaptrack'in sonuçlarına bir örnek aşağıda gösterilmiştir. Flame Graph ve Top-Down sekmeleri, yüksek bellek kullanımına sahip fonksiyonları görsel olarak kontrol etmenize olanak tanır.
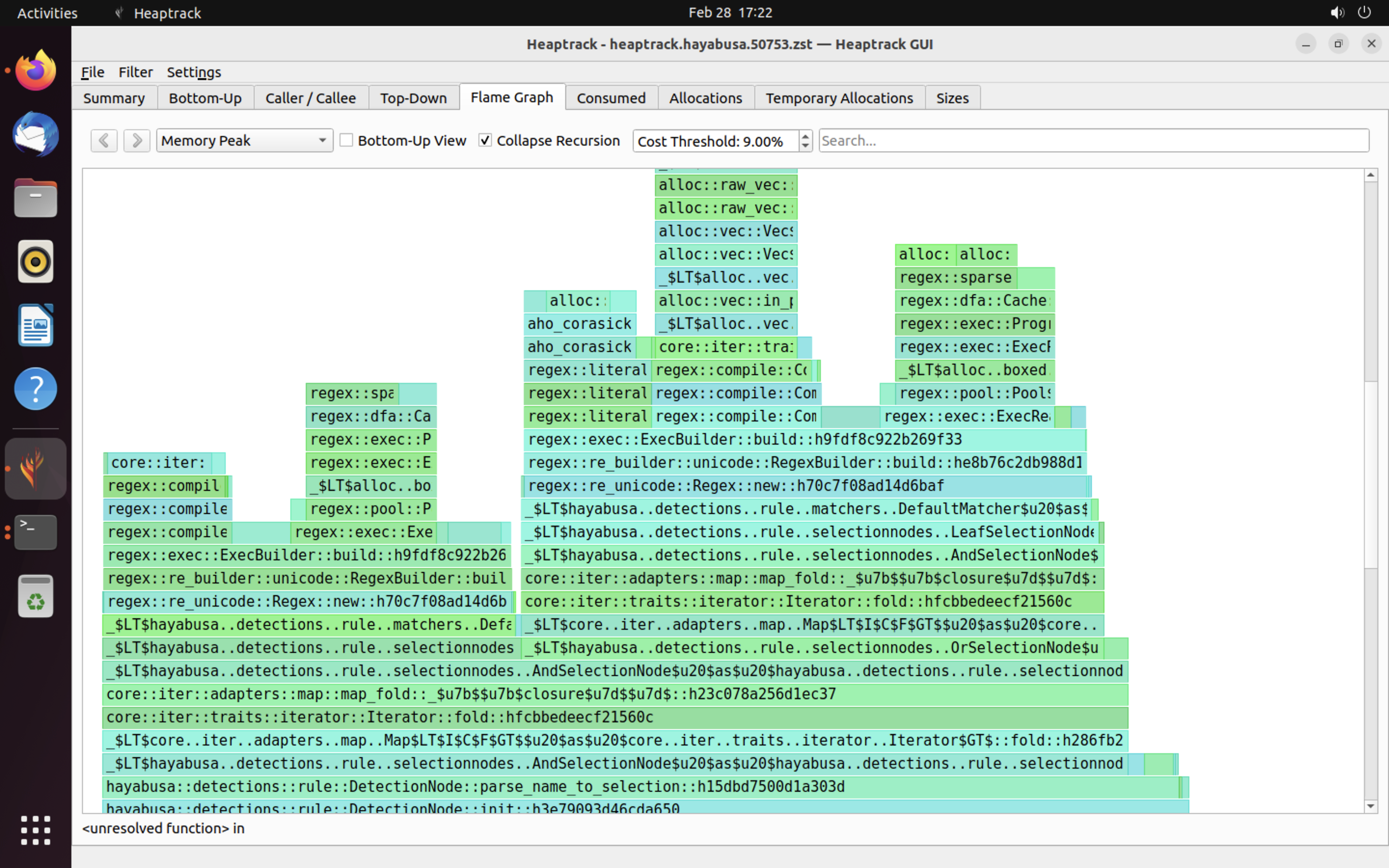
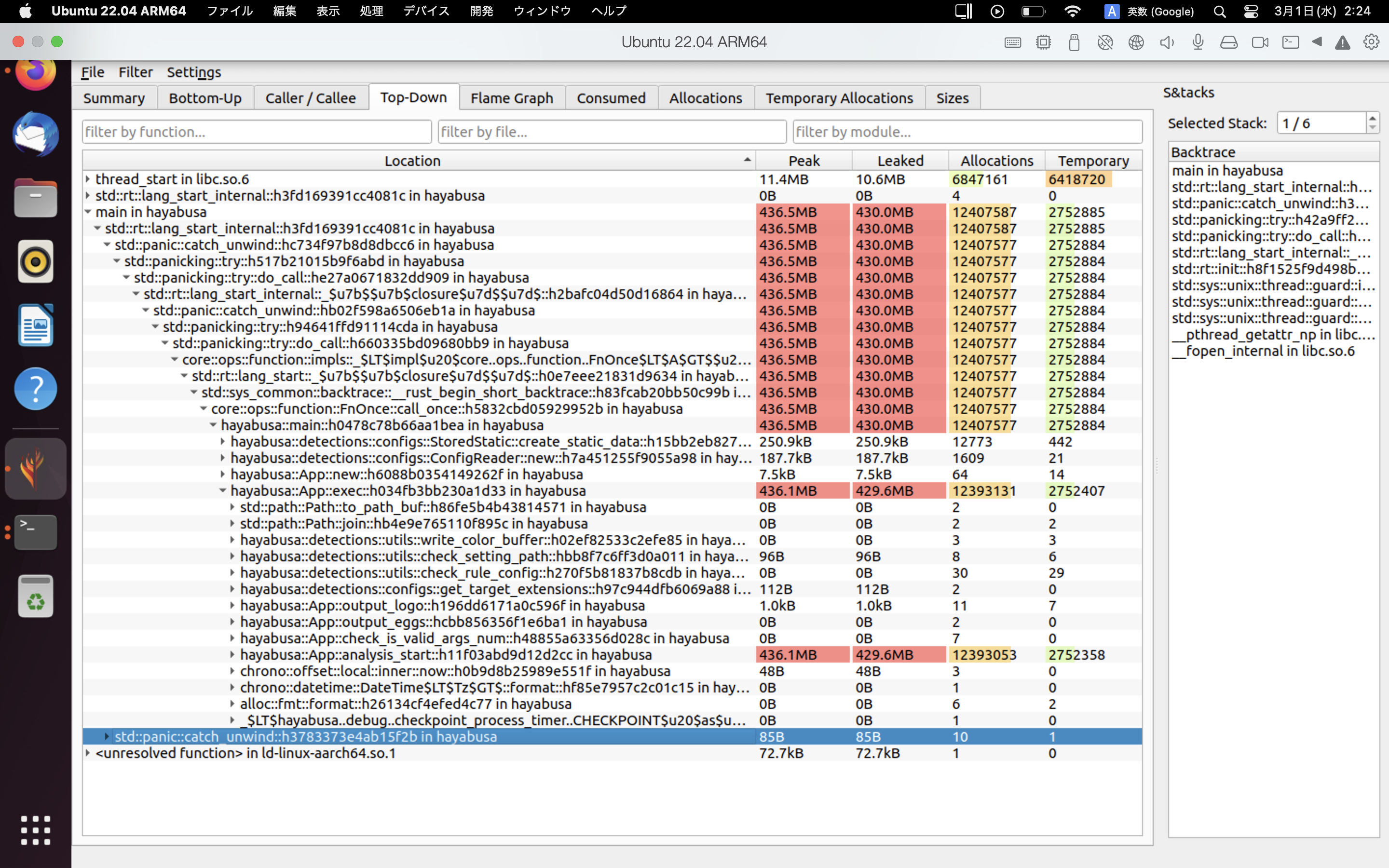
Referanslar¶
Katkılar¶
Bu belge, Hayabusa'daki gerçek iyileştirme vakalarından elde edilen bulgulara dayanmaktadır. Herhangi bir hata veya performansı iyileştirebilecek teknikler bulursanız, lütfen bize bir issue veya pull request gönderin.