คู่มือประสิทธิภาพ Rust สำหรับนักพัฒนา Hayabusa¶
ผู้เขียน¶
Fukusuke Takahashi
การแปลภาษาอังกฤษ¶
Zach Mathis (@yamatosecurity)
เกี่ยวกับเอกสารนี้¶
Hayabusa (ภาษาอังกฤษ: "peregrine falcon" หรือเหยี่ยวเพเรกริน) เป็นเครื่องมือวิเคราะห์ทางนิติวิทยาศาสตร์ที่รวดเร็วซึ่งพัฒนาโดยกลุ่ม Yamato Security ในประเทศญี่ปุ่น มันถูกพัฒนาด้วย Rust เพื่อให้สามารถ (ภัยคุกคาม) ล่าได้รวดเร็วเทียบเท่าเหยี่ยวเพเรกริน Rust เป็นภาษาที่รวดเร็วในตัวมันเองอยู่แล้ว อย่างไรก็ตาม มีจุดที่อาจพลาดได้หลายจุดซึ่งอาจส่งผลให้ความเร็วช้าลงและการใช้หน่วยความจำสูงขึ้น เราสร้างเอกสารนี้ขึ้นจากการปรับปรุงประสิทธิภาพจริงใน Hayabusa (ดู บันทึกการเปลี่ยนแปลงได้ที่นี่) แต่เทคนิคเหล่านี้น่าจะนำไปใช้ได้กับโปรแกรม Rust อื่น ๆ ได้เช่นกัน เราหวังว่าคุณจะได้รับประโยชน์จากความรู้ที่เราได้รับผ่านการลองผิดลองถูกของเรา
การปรับปรุงความเร็ว¶
เปลี่ยน memory allocator¶
เพียงแค่เปลี่ยน memory allocator เริ่มต้นก็อาจช่วยปรับปรุงความเร็วได้อย่างมาก ตัวอย่างเช่น ตาม benchmarks เหล่านี้ memory allocator สองตัวต่อไปนี้
เร็วกว่า memory allocator เริ่มต้นมาก เราสามารถยืนยันการปรับปรุงความเร็วได้อย่างมีนัยสำคัญด้วยการเปลี่ยน memory allocator ของเราจาก jemalloc เป็น mimalloc ดังนั้นเราจึงทำให้ mimalloc เป็นค่าเริ่มต้นตั้งแต่เวอร์ชัน 1.8.0 (แม้ว่า mimalloc จะใช้หน่วยความจำมากกว่า jemalloc เล็กน้อยก็ตาม)
ก่อน ¶
หลัง ¶
คุณเพียงแค่ต้องทำ 2 ขั้นตอนต่อไปนี้เพื่อเปลี่ยน global memory allocator:
- เพิ่ม mimalloc crate ลงในไฟล์
Cargo.tomlที่ [dependencies] section: - กำหนดว่าคุณต้องการใช้ mimalloc ภายใต้ #[global_allocator] ที่ใดที่หนึ่งในโปรแกรม: นั่นคือทั้งหมดที่คุณต้องทำเพื่อเปลี่ยน memory allocator
ประสิทธิผล(ตัวอย่างจริงจาก Pull Request) ¶
ความเร็วจะปรับปรุงได้มากเพียงใดขึ้นอยู่กับโปรแกรม แต่ในตัวอย่างต่อไปนี้
การเปลี่ยน memory allocator เป็น mimalloc ส่งผลให้ประสิทธิภาพเพิ่มขึ้น 20-30% บน Intel CPU (ด้วยเหตุผลบางอย่าง ประสิทธิภาพไม่ได้เพิ่มขึ้นอย่างมีนัยสำคัญบนอุปกรณ์ macOS ที่ใช้ ARM)
ลดการประมวลผล IO ในลูป¶
การประมวลผล Disk IO ช้ากว่าการประมวลผลในหน่วยความจำมาก ดังนั้นจึงควรหลีกเลี่ยงการประมวลผล IO ให้มากที่สุดเท่าที่จะเป็นไปได้ โดยเฉพาะอย่างยิ่งในลูป
ก่อน ¶
ตัวอย่างด้านล่างแสดงการเปิดไฟล์เกิดขึ้นหนึ่งล้านครั้งในลูป:
use std::fs;
fn main() {
for _ in 0..1000000 {
let f = fs::read_to_string("sample.txt").unwrap();
f.len();
}
}
หลัง ¶
ด้วยการเปิดไฟล์นอกลูปดังต่อไปนี้
use std::fs;
fn main() {
let f = fs::read_to_string("sample.txt").unwrap();
for _ in 0..1000000 {
f.len();
}
}
ประสิทธิผล(ตัวอย่างจริงจาก Pull Request) ¶
ในตัวอย่างต่อไปนี้ การประมวลผล IO เมื่อจัดการผลการตรวจจับทีละรายการสามารถทำได้นอกลูป:
ส่งผลให้ความเร็วปรับปรุงได้ประมาณ 20%
หลีกเลี่ยงการคอมไพล์ regular expression ในลูป¶
การคอมไพล์ regular expression เป็นกระบวนการที่มีต้นทุนสูงมากเมื่อเทียบกับการจับคู่ regular expression ดังนั้นจึงควรหลีกเลี่ยงการคอมไพล์ regular expression ให้มากที่สุดเท่าที่จะเป็นไปได้ โดยเฉพาะอย่างยิ่งในลูป
ก่อน ¶
ตัวอย่างเช่น กระบวนการต่อไปนี้สร้างความพยายามจับคู่ regular expression 100,000 ครั้งในลูป:
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..100000 {
if Regex::new(match_str).unwrap().is_match(text){ // Regular expression compilation in a loop
println!("matched!");
}
}
}
หลัง ¶
ด้วยการคอมไพล์ regular expression นอกลูปดังที่แสดงด้านล่าง
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap(); // Compile the regular expression outside the loop
for _ in 0..100000 {
if r.is_match(text) {
println!("matched!");
}
}
}
ประสิทธิผล(ตัวอย่างจริงจาก Pull Request) ¶
ในตัวอย่างต่อไปนี้ การคอมไพล์ regular expression ทำนอกลูปและถูกแคชไว้
ส่งผลให้ความเร็วปรับปรุงได้อย่างมีนัยสำคัญ
ใช้ buffer IO¶
หากไม่มี buffer IO การทำ file IO จะช้า ด้วย buffer IO การดำเนินการ IO จะทำผ่านบัฟเฟอร์ในหน่วยความจำ ลดจำนวน system call และปรับปรุงความเร็ว
ก่อน ¶
ตัวอย่างเช่น ในกระบวนการต่อไปนี้ write เกิดขึ้น 1,000,000 ครั้ง
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
for _ in 0..1000000 {
f.write(b"hello world!");
}
}
หลัง ¶
ด้วยการใช้ BufWriter ดังต่อไปนี้
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
let mut writer = BufWriter::new(f);
for _ in 0..1000000 {
writer.write(b"some text");
}
writer.flush().unwrap();
}
ประสิทธิผล(ตัวอย่างจริงจาก Pull Request) ¶
วิธีที่อธิบายข้างต้นถูกนำมาใช้ที่นี่
และส่งผลให้ความเร็วปรับปรุงได้อย่างมีนัยสำคัญในการประมวลผลเอาต์พุต
ใช้เมธอด String มาตรฐานแทน regular expression¶
แม้ว่า regular expression จะสามารถครอบคลุมรูปแบบการจับคู่ที่ซับซ้อนได้ แต่ก็ช้ากว่า เมธอด String มาตรฐาน ดังนั้นการใช้เมธอด String มาตรฐานสำหรับการจับคู่สตริงแบบง่าย ๆ เช่นต่อไปนี้จึงเร็วกว่า
- การจับคู่แบบ Starts-with(Regex:
foo.*)-> String::starts_with() - การจับคู่แบบ Ends-with(Regex:
.*foo)-> String::ends_with() - การจับคู่แบบ Contains(Regex:
.*foo.*)-> String::contains()
ก่อน ¶
ตัวอย่างเช่น โค้ดต่อไปนี้ทำการจับคู่แบบ ends-with ใน regular expression หนึ่งล้านครั้ง
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = ".*abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
หลัง ¶
ด้วยการใช้ String::ends_with() ดังต่อไปนี้
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..1000000 {
if text.ends_with(match_str) {
println!("matched!");
}
}
}
ประสิทธิผล(ตัวอย่างจริงจาก Pull Request) ¶
เนื่องจาก Hayabusa ต้องการการเปรียบเทียบสตริงแบบไม่สนใจตัวพิมพ์เล็กพิมพ์ใหญ่ เราจึงใช้ to_lowercase() แล้วจึงใช้วิธีข้างต้น แม้กระนั้น ในตัวอย่างต่อไปนี้
- Imporving speed by changing wildcard search process from regular expression match to starts_with/ends_with match #890
- Improving speed by using eq_ignore_ascii_case() before regular expression match #884
ความเร็วปรับปรุงได้ประมาณ 15% เมื่อเทียบกับก่อนหน้า
กรองตามความยาวสตริง¶
ขึ้นอยู่กับลักษณะของสตริงที่กำลังจัดการ การเพิ่มตัวกรองแบบง่าย ๆ อาจช่วยลดจำนวนความพยายามจับคู่สตริงและเร่งความเร็วของกระบวนการ หากคุณมักเปรียบเทียบสตริงที่มีความยาวไม่คงที่และไม่ตรงกัน คุณสามารถเร่งความเร็วของกระบวนการได้ด้วยการใช้ความยาวสตริงเป็นตัวกรองหลัก
ก่อน ¶
ตัวอย่างเช่น โค้ดต่อไปนี้พยายามจับคู่ regular expression หนึ่งล้านครั้ง
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
หลัง ¶
ด้วยการใช้ String::len() เป็นตัวกรองหลัก ดังที่แสดงด้านล่าง
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if text.len() == match_str.len() { // Primary filter by string length
if r.is_match(text) {
println!("matched!");
}
}
}
}
ประสิทธิผล(ตัวอย่างจริงจาก Pull Request) ¶
ในตัวอย่างต่อไปนี้ มีการใช้วิธีข้างต้น
ซึ่งปรับปรุงความเร็วได้ประมาณ 15%
อย่าคอมไพล์ด้วย codegen-units=1¶
บทความจำนวนมากเกี่ยวกับการปรับแต่งประสิทธิภาพด้วย Rust แนะนำให้เพิ่ม codegen-units = 1 ภายใต้ส่วน [profile.release]
สิ่งนี้จะทำให้เวลาในการคอมไพล์ช้าลงเนื่องจากค่าเริ่มต้นคือการคอมไพล์แบบขนาน แต่ในทางทฤษฎีควรส่งผลให้โค้ดได้รับการปรับแต่งมากขึ้นและเร็วขึ้น
อย่างไรก็ตาม ในการทดสอบของเรา Hayabusa ทำงานช้าลงจริง ๆ เมื่อเปิดตัวเลือกนี้และการคอมไพล์ใช้เวลานานขึ้น ดังนั้นเราจึงปิดไว้
ขนาดไบนารีของไฟล์ปฏิบัติการเล็กลงประมาณ 100kb ดังนั้นสิ่งนี้อาจเหมาะสำหรับระบบฝังตัวที่พื้นที่ฮาร์ดดิสก์มีจำกัด
การลดการใช้หน่วยความจำ¶
หลีกเลี่ยงการใช้ clone(), to_string() และ to_owned() ที่ไม่จำเป็น¶
การใช้ clone() หรือ to_string() เป็นวิธีง่าย ๆ ในการแก้ไขข้อผิดพลาดในการคอมไพล์ที่เกี่ยวข้องกับ ownership อย่างไรก็ตาม มักจะส่งผลให้มีการใช้หน่วยความจำสูงและควรหลีกเลี่ยง ทางที่ดีที่สุดคือดูก่อนเสมอว่าคุณสามารถแทนที่ด้วย references ที่มีต้นทุนต่ำได้หรือไม่
ก่อน ¶
ตัวอย่างเช่น หากคุณต้องการวนซ้ำ Vec เดียวกันหลายครั้ง คุณสามารถใช้ clone() เพื่อกำจัดข้อผิดพลาดในการคอมไพล์
fn main() {
let lst = vec![1, 2, 3];
for x in lst.clone() { // In order to eliminate compile errors
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
หลัง ¶
อย่างไรก็ตาม ด้วยการใช้ references ดังที่แสดงด้านล่าง คุณสามารถลบความจำเป็นในการใช้ clone() ได้
fn main() {
let lst = vec![1, 2, 3];
for x in &lst { // Eliminate compile errors with a reference
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
ประสิทธิผล(ตัวอย่างจริงจาก Pull Request) ¶
ในตัวอย่างต่อไปนี้ ด้วยการแทนที่การใช้ clone(), to_string() และ to_owned() ที่ไม่จำเป็น
เราสามารถลดการใช้หน่วยความจำได้อย่างมีนัยสำคัญ
ใช้ Iterator แทน Vec¶
Vec เก็บองค์ประกอบทั้งหมดไว้ในหน่วยความจำ ดังนั้นจึงใช้หน่วยความจำมากตามสัดส่วนของจำนวนองค์ประกอบ หากการประมวลผลทีละองค์ประกอบเพียงพอ การใช้ Iterator แทนจะใช้หน่วยความจำน้อยกว่ามาก
ก่อน ¶
ตัวอย่างเช่น ฟังก์ชัน return_lines() ต่อไปนี้อ่านไฟล์ขนาดประมาณ 1 GB และคืนค่า Vec:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> Vec<String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
.collect()
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
หลัง ¶
แทนที่ คุณควรคืนค่า Iterator Trait ดังต่อไปนี้:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> impl Iterator<Item=String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
// ここでcollect()せずに、Iteratorを戻り値として返す
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
Box<dyn Iterator<Item = T>> ดังต่อไปนี้:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines(need_filter:bool) -> Box<dyn Iterator<Item = String>> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
if need_filter {
let result= buf.lines()
.filter_map(|l| l.ok())
.map(|l| l.replace("A", "B"));
return Box::new(result)
}
let result= buf.lines()
.map(|l| l.expect("Could not parse line"));
Box::new(result)
}
fn main() {
let lines = return_lines(true);
for line in lines {
println!("{}", line)
}
}
ประสิทธิผล(ตัวอย่างจริงจาก Pull Request) ¶
ตัวอย่างต่อไปนี้ใช้วิธีที่อธิบายข้างต้น:
เมื่อทดสอบกับไฟล์ JSON ขนาด 1.7GB หน่วยความจำลดลง 75%
ใช้ compact_str crate เมื่อจัดการสตริงสั้น¶
เมื่อจัดการกับสตริงสั้นจำนวนมากที่มีขนาดน้อยกว่า 24 ไบต์ สามารถใช้ compact_str crate เพื่อลดการใช้หน่วยความจำได้
ก่อน ¶
ในตัวอย่างด้านล่าง Vec เก็บสตริง 10 ล้านตัว
fn main() {
let v: Vec<String> = vec![String::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
หลัง ¶
ทางที่ดีกว่าคือแทนที่ด้วย CompactString:
use compact_str::CompactString;
fn main() {
let v: Vec<CompactString> = vec![CompactString::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
ประสิทธิผล(ตัวอย่างจริงจาก Pull Request) ¶
ในตัวอย่างต่อไปนี้ สตริงสั้นถูกจัดการด้วย CompactString:
สิ่งนี้ทำให้การใช้หน่วยความจำลดลงประมาณ 20%
ลบฟิลด์ที่ไม่จำเป็นในโครงสร้างที่มีอายุยาว¶
โครงสร้างที่ยังคงถูกเก็บไว้ในหน่วยความจำระหว่างการเริ่มต้นกระบวนการอาจส่งผลต่อการใช้หน่วยความจำโดยรวม ใน Hayabusa โครงสร้างต่อไปนี้ (ณ เวอร์ชัน 2.2.2) โดยเฉพาะอย่างยิ่ง ถูกเก็บไว้เป็นจำนวนมาก
การลบฟิลด์ที่เกี่ยวข้องกับโครงสร้างข้างต้นมีผลบางส่วนในการลดการใช้หน่วยความจำโดยรวม
ก่อน ¶
ตัวอย่างเช่น ฟิลด์ DetectInfo จนถึงเวอร์ชัน 1.8.1 เป็นดังต่อไปนี้:
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
pub record_information: CompactString,
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
หลัง ¶
ด้วยการลบฟิลด์ record_information ดังต่อไปนี้
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
// remove record_information field
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
ประสิทธิผล(ตัวอย่างจริงจาก Pull Request) ¶
ในตัวอย่างต่อไปนี้ เมื่อทดสอบกับข้อมูลที่มีจำนวนเรกคอร์ดผลการตรวจจับประมาณ 1.5 ล้านรายการ
- Reduced memory usage of DetectInfo/EvtxRecordInfo #837
- Reduce memory usage by removing unnecessary regex #894
เราสามารถลดการใช้หน่วยความจำได้ประมาณ 300MB
การวัดประสิทธิภาพ (Benchmarking)¶
ใช้ฟังก์ชันสถิติของ memory allocator¶
memory allocator บางตัวเก็บสถิติการใช้หน่วยความจำของตนเอง ตัวอย่างเช่น ใน mimalloc สามารถเรียกฟังก์ชัน mi_stats_print_out() เพื่อรับการใช้หน่วยความจำได้
วิธีการรับสถิติ ¶
ข้อกำหนดเบื้องต้น: คุณต้องใช้ mimalloc ตามที่อธิบายในส่วน เปลี่ยน memory allocator
- ใน
Cargo.tomlที่ dependencies section ให้เพิ่ม libmimalloc-sys crate: - เมื่อใดก็ตามที่คุณต้องการพิมพ์สถิติการใช้หน่วยความจำ ให้เขียนโค้ดต่อไปนี้และภายในบล็อก
unsafeให้เรียก mi_stats_print_out() สถิติการใช้หน่วยความจำจะถูกส่งออกไปยัง standard out -
ค่า
peak/reservedที่มุมซ้ายบนคือการใช้หน่วยความจำสูงสุด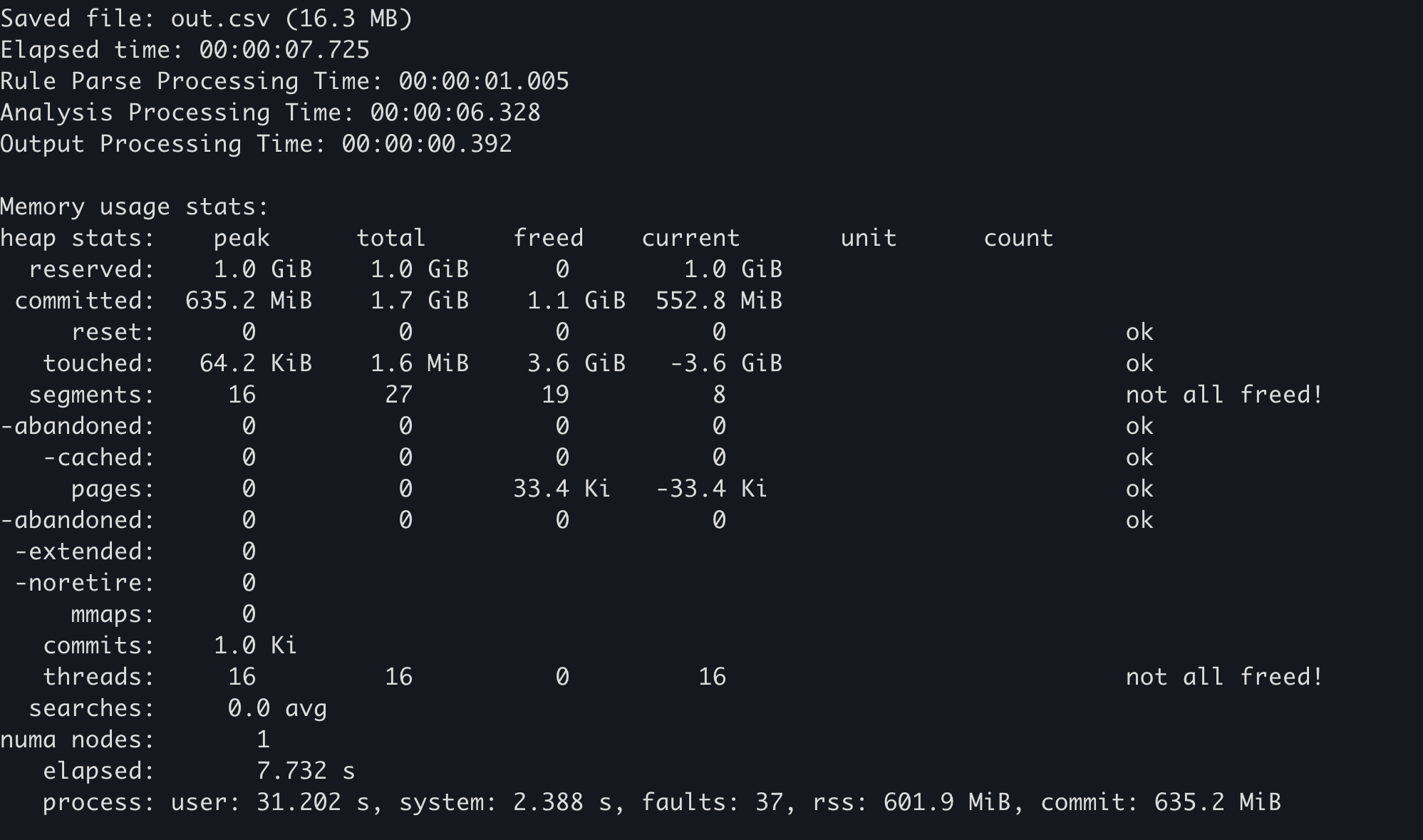
ตัวอย่าง ¶
การนำไปใช้ข้างต้นถูกนำมาใช้ในส่วนต่อไปนี้:
ใน Hayabusa หากคุณเพิ่มตัวเลือก --debug สถิติการใช้หน่วยความจำจะถูกส่งออกในตอนท้าย
ใช้ performance counter ของ Windows¶
สามารถตรวจสอบการใช้ทรัพยากรต่าง ๆ ได้จากสถิติที่ได้รับจากฝั่ง OS ในกรณีนี้ ควรสังเกตสองจุดต่อไปนี้
- อิทธิพลจากซอฟต์แวร์แอนตี้ไวรัส (Windows Defender)
- มีเพียงการรันครั้งแรกเท่านั้นที่ได้รับผลกระทบจากการสแกนและช้าลง ดังนั้นผลลัพธ์จากการรันครั้งที่สองและครั้งต่อ ๆ ไปหลังจากบิลด์จึงเหมาะสำหรับการเปรียบเทียบ (หรือคุณสามารถปิดใช้งานแอนตี้ไวรัสของคุณเพื่อผลลัพธ์ที่แม่นยำยิ่งขึ้น)
- อิทธิพลจากการแคชไฟล์
- ผลลัพธ์จากครั้งที่สองและครั้งต่อ ๆ ไปหลังจากเริ่มต้น OS จะเร็วกว่าครั้งแรกเนื่องจาก evtx และ file IO อื่น ๆ ถูกอ่านจากแคชไฟล์ในหน่วยความจำ ดังนั้นผลลัพธ์จากครั้งแรกหลังจาก OS บูตจึงเหมาะสมกว่าสำหรับการวัดประสิทธิภาพ
วิธีการรับ ¶
ข้อกำหนดเบื้องต้น:ขั้นตอนต่อไปนี้ใช้ได้เฉพาะกับสภาพแวดล้อมที่ติดตั้ง PowerShell 7 บน Windows อยู่แล้วเท่านั้น
- รีสตาร์ท OS
- รัน Get-Counter command ของ
PowerShell 7ซึ่งจะบันทึก performance counter อย่างต่อเนื่องทุกวินาทีลงในไฟล์ CSV (หากคุณต้องการวัดทรัพยากรอื่นนอกเหนือจากที่ระบุไว้ด้านล่าง บทความนี้ เป็นข้อมูลอ้างอิงที่ดี) - รันกระบวนการที่คุณต้องการวัด
ตัวอย่าง ¶
ส่วนต่อไปนี้มีตัวอย่างขั้นตอนการวัดประสิทธิภาพด้วย Hayabusa
ใช้ heaptrack¶
heaptrack เป็น memory profiler ที่ซับซ้อนซึ่งมีให้ใช้สำหรับ Linux และ macOS ด้วยการใช้ heaptrack คุณสามารถตรวจสอบคอขวดได้อย่างละเอียด
วิธีการรับ ¶
ข้อกำหนดเบื้องต้น: ด้านล่างเป็นขั้นตอนสำหรับ Ubuntu 22.04 คุณไม่สามารถใช้ heaptrack บน Windows ได้
- ติดตั้ง heaptrack ด้วยสองคำสั่งต่อไปนี้
- ลบโค้ด mimalloc ต่อไปนี้ออกจาก Hayabusa (คุณไม่สามารถใช้ memory profiler ของ heaptrack กับ mimalloc ได้
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L32-L33
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L59-L60
-
https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L632-L634
-
ลบ [profile.release] section ในไฟล์
Cargo.tomlของ Hayabusa และเปลี่ยนเป็นดังต่อไปนี้: -
สร้าง release build:
cargo build --release - รัน
heaptrack hayabusa csv-timeline -d sample -o out.csv
ตอนนี้เมื่อ Hayabusa รันเสร็จ ผลลัพธ์ของ heaptrack จะเปิดในแอปพลิเคชัน GUI โดยอัตโนมัติ
ตัวอย่าง ¶
ตัวอย่างผลลัพธ์ของ heaptrack แสดงไว้ด้านล่าง แท็บ Flame Graph และ Top-Down ช่วยให้คุณตรวจสอบฟังก์ชันที่ใช้หน่วยความจำสูงได้ด้วยสายตา
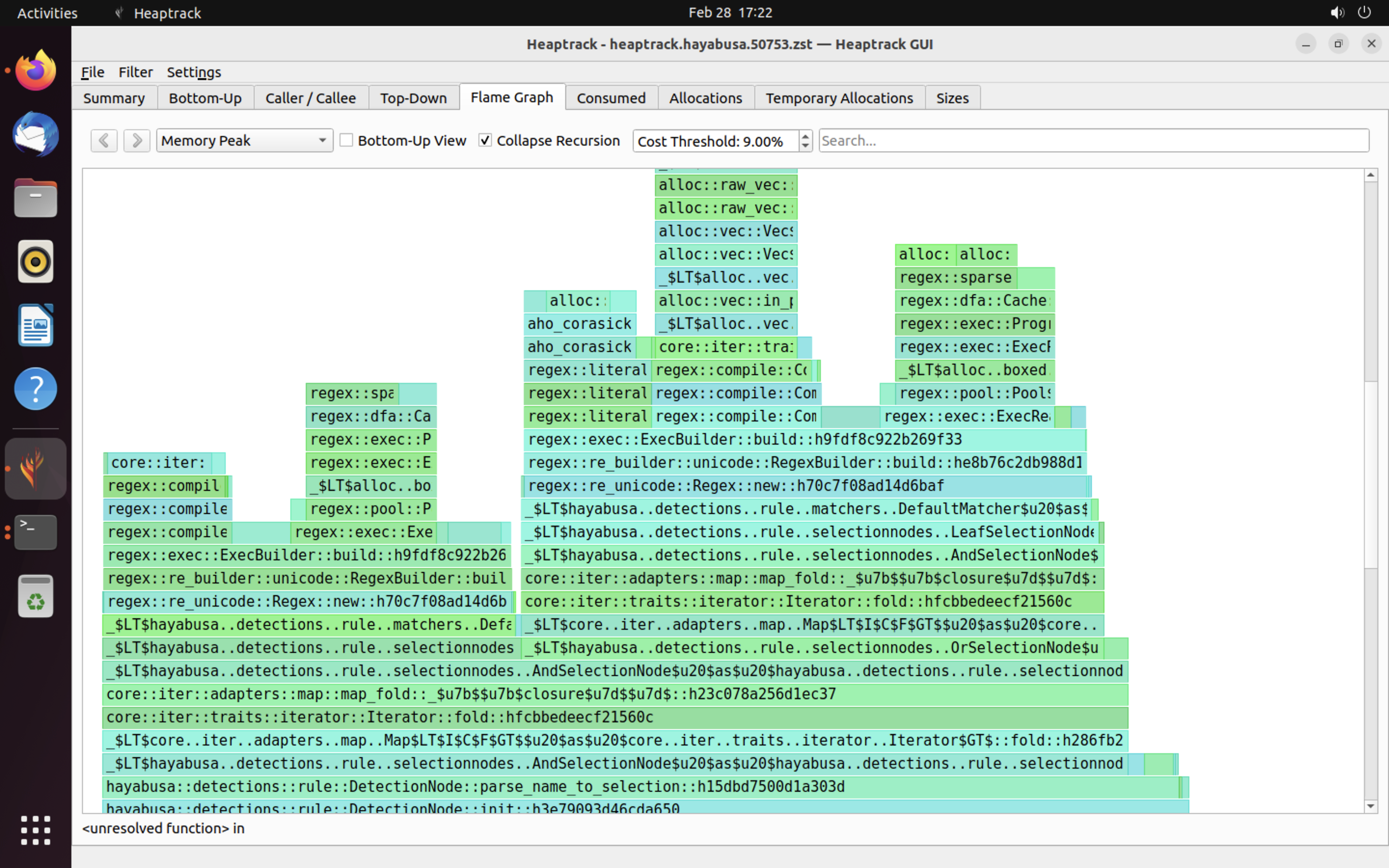
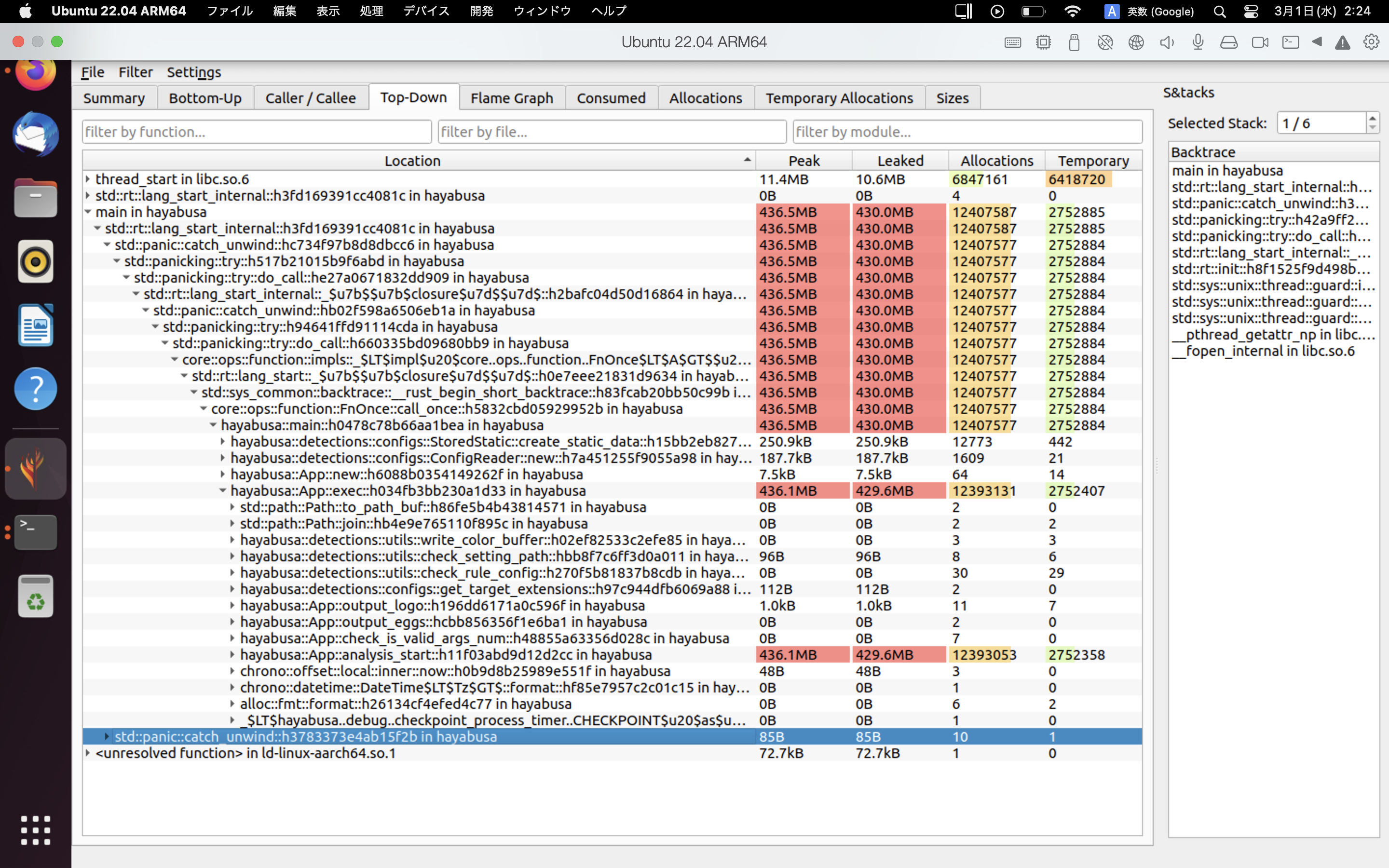
เอกสารอ้างอิง¶
การมีส่วนร่วม¶
เอกสารนี้อ้างอิงจากข้อค้นพบจากกรณีการปรับปรุงจริงใน Hayabusa หากคุณพบข้อผิดพลาดหรือเทคนิคใด ๆ ที่สามารถปรับปรุงประสิทธิภาพได้ โปรดส่ง issue หรือ pull request มาให้เรา