Hayabusa 개발자를 위한 Rust 성능 가이드¶
저자¶
Fukusuke Takahashi
영어 번역¶
Zach Mathis (@yamatosecurity)
이 문서에 대하여¶
Hayabusa (영어: "peregrine falcon", 송골매)는 일본의 Yamato Security 그룹이 개발한 빠른 포렌식 분석 도구입니다. 송골매처럼 빠르게 (위협을) 헌팅하기 위해 Rust로 개발되었습니다. Rust 자체는 빠른 언어이지만, 느린 속도와 높은 메모리 사용으로 이어질 수 있는 함정이 많이 있습니다. 우리는 Hayabusa의 실제 성능 개선 사례(여기서 changelog 보기)를 바탕으로 이 문서를 작성했지만, 이러한 기법들은 다른 Rust 프로그램에도 적용할 수 있을 것입니다. 우리가 시행착오를 통해 얻은 지식이 여러분에게도 도움이 되기를 바랍니다.
속도 개선¶
메모리 할당자 변경¶
기본 메모리 할당자를 단순히 변경하는 것만으로도 속도가 크게 향상될 수 있습니다. 예를 들어, 이 벤치마크에 따르면 다음 두 메모리 할당자
는 기본 메모리 할당자보다 훨씬 빠릅니다. 우리는 메모리 할당자를 jemalloc에서 mimalloc으로 변경하여 상당한 속도 향상을 확인할 수 있었기 때문에, 버전 1.8.0부터 mimalloc을 기본값으로 설정했습니다. (다만 mimalloc은 jemalloc보다 약간 더 많은 메모리를 사용합니다.)
Before ¶
After ¶
전역 메모리 할당자를 변경하려면 다음 2단계만 수행하면 됩니다:
Cargo.toml파일의 [dependencies] 섹션에 mimalloc crate를 추가합니다:- 프로그램 어딘가에서 #[global_allocator] 아래에 mimalloc을 사용하겠다고 정의합니다: 메모리 할당자를 변경하기 위해 해야 할 일은 이것이 전부입니다.
효과(Pull Request의 실제 예시) ¶
속도가 얼마나 개선되는지는 프로그램에 따라 다르지만, 다음 예시에서
메모리 할당자를 mimalloc으로 변경하자 Intel CPU에서 20-30%의 성능 향상이 있었습니다. (어떤 이유에서인지 ARM 기반 macOS 장치에서는 그만큼 큰 성능 향상이 없었습니다.)
루프 내 IO 처리 줄이기¶
디스크 IO 처리는 메모리 내 처리보다 훨씬 느립니다. 따라서 특히 루프 안에서는 IO 처리를 가능한 한 피하는 것이 바람직합니다.
Before ¶
아래 예시는 루프 안에서 파일 열기가 백만 번 발생하는 것을 보여줍니다:
use std::fs;
fn main() {
for _ in 0..1000000 {
let f = fs::read_to_string("sample.txt").unwrap();
f.len();
}
}
After ¶
다음과 같이 루프 밖에서 파일을 열면
use std::fs;
fn main() {
let f = fs::read_to_string("sample.txt").unwrap();
for _ in 0..1000000 {
f.len();
}
}
효과(Pull Request의 실제 예시) ¶
다음 예시에서는 한 번에 하나의 탐지 결과를 처리할 때의 IO 처리를 루프 밖에서 수행할 수 있었습니다:
이로 인해 약 20%의 속도 개선이 있었습니다.
루프 내 정규 표현식 컴파일 피하기¶
정규 표현식 컴파일은 정규 표현식 매칭에 비해 매우 비용이 큰 작업입니다. 따라서 특히 루프 안에서는 정규 표현식 컴파일을 가능한 한 피하는 것이 좋습니다.
Before ¶
예를 들어, 다음 처리는 루프 안에서 정규 표현식 매칭을 10만 번 시도합니다:
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..100000 {
if Regex::new(match_str).unwrap().is_match(text){ // Regular expression compilation in a loop
println!("matched!");
}
}
}
After ¶
아래와 같이 루프 밖에서 정규 표현식 컴파일을 수행하면
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap(); // Compile the regular expression outside the loop
for _ in 0..100000 {
if r.is_match(text) {
println!("matched!");
}
}
}
효과(Pull Request의 실제 예시) ¶
다음 예시에서는 정규 표현식 컴파일을 루프 밖에서 수행하고 캐시합니다.
이로 인해 상당한 속도 개선이 있었습니다.
버퍼 IO 사용¶
버퍼 IO가 없으면 파일 IO가 느립니다. 버퍼 IO를 사용하면 메모리 내 버퍼를 통해 IO 작업이 수행되어 시스템 호출 횟수가 줄어들고 속도가 향상됩니다.
Before ¶
예를 들어, 다음 처리에서는 write가 1,000,000번 발생합니다.
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
for _ in 0..1000000 {
f.write(b"hello world!");
}
}
After ¶
다음과 같이 BufWriter를 사용하면
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
let mut writer = BufWriter::new(f);
for _ in 0..1000000 {
writer.write(b"some text");
}
writer.flush().unwrap();
}
효과(Pull Request의 실제 예시) ¶
위에서 설명한 방법은 여기서 구현되었으며
출력 처리에서 상당한 속도 개선을 가져왔습니다.
정규 표현식 대신 표준 String 메서드 사용¶
정규 표현식은 복잡한 매칭 패턴을 다룰 수 있지만, 표준 String 메서드보다 느립니다. 따라서 다음과 같은 단순한 문자열 매칭에는 표준 String 메서드를 사용하는 것이 더 빠릅니다.
- 시작 매칭(Regex:
foo.*)-> String::starts_with() - 끝 매칭(Regex:
.*foo)-> String::ends_with() - 포함 매칭(Regex:
.*foo.*)-> String::contains()
Before ¶
예를 들어, 다음 코드는 정규 표현식으로 끝 매칭을 백만 번 수행합니다.
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = ".*abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
After ¶
다음과 같이 String::ends_with()를 사용하면
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..1000000 {
if text.ends_with(match_str) {
println!("matched!");
}
}
}
효과(Pull Request의 실제 예시) ¶
Hayabusa는 대소문자를 구분하지 않는 문자열 비교가 필요하므로, to_lowercase()를 사용한 후 위 방법을 적용합니다. 그렇게 하더라도, 다음 예시에서
- Imporving speed by changing wildcard search process from regular expression match to starts_with/ends_with match #890
- Improving speed by using eq_ignore_ascii_case() before regular expression match #884
이전에 비해 약 15% 속도가 향상되었습니다.
문자열 길이로 필터링¶
다루는 문자열의 특성에 따라, 단순한 필터를 추가하면 문자열 매칭 시도 횟수를 줄이고 처리 속도를 높일 수 있습니다. 고정되지 않은 길이의 일치하지 않는 문자열을 자주 비교하는 경우, 문자열 길이를 1차 필터로 사용하여 처리 속도를 높일 수 있습니다.
Before ¶
예를 들어, 다음 코드는 정규 표현식 매칭을 백만 번 시도합니다.
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
After ¶
아래와 같이 String::len()을 1차 필터로 사용하면
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if text.len() == match_str.len() { // Primary filter by string length
if r.is_match(text) {
println!("matched!");
}
}
}
}
효과(Pull Request의 실제 예시) ¶
다음 예시에서는 위 방법을 사용합니다.
이로 인해 속도가 약 15% 개선되었습니다.
codegen-units=1로 컴파일하지 않기¶
Rust의 성능 최적화에 관한 많은 글에서는 [profile.release] 섹션 아래에 codegen-units = 1을 추가하라고 권장합니다.
기본값은 병렬로 컴파일하는 것이므로 이렇게 하면 컴파일 시간이 느려지지만, 이론적으로는 더 최적화되고 빠른 코드가 생성됩니다.
그러나 우리의 테스트에서는 이 옵션을 켜면 Hayabusa가 실제로 더 느리게 실행되고 컴파일에 더 오래 걸리므로 이 옵션을 꺼 둡니다.
실행 파일의 바이너리 크기는 약 100kb 더 작아지므로 하드 디스크 공간이 제한된 임베디드 시스템에는 이상적일 수 있습니다.
메모리 사용량 줄이기¶
clone(), to_string(), to_owned()의 불필요한 사용 피하기¶
clone()이나 to_string()을 사용하면 소유권과 관련된 컴파일 오류를 쉽게 해결할 수 있습니다. 그러나 이들은 일반적으로 높은 메모리 사용으로 이어지므로 피해야 합니다. 먼저 비용이 낮은 참조로 대체할 수 있는지 확인하는 것이 항상 가장 좋습니다.
Before ¶
예를 들어, 같은 Vec를 여러 번 반복하려는 경우 clone()을 사용하여 컴파일 오류를 제거할 수 있습니다.
fn main() {
let lst = vec![1, 2, 3];
for x in lst.clone() { // In order to eliminate compile errors
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
After ¶
그러나 아래와 같이 참조를 사용하면 clone()을 사용할 필요가 없어집니다.
fn main() {
let lst = vec![1, 2, 3];
for x in &lst { // Eliminate compile errors with a reference
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
효과(Pull Request의 실제 예시) ¶
다음 예시에서는 불필요한 clone(), to_string(), to_owned() 사용을 대체하여
메모리 사용량을 크게 줄일 수 있었습니다.
Vec 대신 Iterator 사용¶
Vec는 모든 요소를 메모리에 유지하므로 요소 수에 비례하여 많은 메모리를 사용합니다. 한 번에 하나의 요소를 처리하는 것으로 충분하다면, 대신 Iterator를 사용하면 훨씬 적은 메모리를 사용합니다.
Before ¶
예를 들어, 다음 return_lines() 함수는 약 1 GB의 파일을 읽고 Vec를 반환합니다:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> Vec<String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
.collect()
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
After ¶
대신 다음과 같이 Iterator Trait를 반환해야 합니다:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> impl Iterator<Item=String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
// ここでcollect()せずに、Iteratorを戻り値として返す
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
Box<dyn Iterator<Item = T>>를 반환할 수 있습니다:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines(need_filter:bool) -> Box<dyn Iterator<Item = String>> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
if need_filter {
let result= buf.lines()
.filter_map(|l| l.ok())
.map(|l| l.replace("A", "B"));
return Box::new(result)
}
let result= buf.lines()
.map(|l| l.expect("Could not parse line"));
Box::new(result)
}
fn main() {
let lines = return_lines(true);
for line in lines {
println!("{}", line)
}
}
효과(Pull Request의 실제 예시) ¶
다음 예시는 위에서 설명한 방법을 사용합니다:
1.7GB JSON 파일에서 테스트했을 때, 메모리가 75% 감소했습니다.
짧은 문자열을 다룰 때 compact_str crate 사용¶
24바이트 미만의 짧은 문자열을 대량으로 다룰 때, compact_str crate를 사용하여 메모리 사용량을 줄일 수 있습니다.
Before ¶
아래 예시에서 Vec는 천만 개의 문자열을 보유합니다.
fn main() {
let v: Vec<String> = vec![String::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
After ¶
이를 CompactString으로 대체하는 것이 좋습니다:
use compact_str::CompactString;
fn main() {
let v: Vec<CompactString> = vec![CompactString::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
효과(Pull Request의 실제 예시) ¶
다음 예시에서는 짧은 문자열을 CompactString으로 다룹니다:
이로 인해 메모리 사용량이 약 20% 감소했습니다.
오래 유지되는 구조체에서 불필요한 필드 삭제¶
프로세스 시작 중에 메모리에 계속 유지되는 구조체는 전체 메모리 사용량에 영향을 줄 수 있습니다. Hayabusa에서는 특히 다음 구조체들(버전 2.2.2 기준)이 대량으로 유지됩니다.
위 구조체들과 관련된 필드를 제거하니 전체 메모리 사용량을 줄이는 데 어느 정도 효과가 있었습니다.
Before ¶
예를 들어, DetectInfo 필드는 버전 1.8.1까지 다음과 같았습니다:
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
pub record_information: CompactString,
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
After ¶
다음과 같이 record_information 필드를 삭제하여
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
// remove record_information field
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
효과(Pull Request의 실제 예시) ¶
다음 예시에서는 탐지 결과 레코드 수가 약 150만 개인 데이터에 대해 테스트했을 때,
- Reduced memory usage of DetectInfo/EvtxRecordInfo #837
- Reduce memory usage by removing unnecessary regex #894
약 300MB의 메모리 사용량 감소를 달성할 수 있었습니다.
벤치마킹¶
메모리 할당자의 통계 기능 사용¶
일부 메모리 할당자는 자체 메모리 사용량 통계를 유지합니다. 예를 들어, mimalloc에서는 mi_stats_print_out() 함수를 호출하여 메모리 사용량을 얻을 수 있습니다.
통계를 얻는 방법 ¶
전제 조건: 메모리 할당자 변경 섹션에서 설명한 대로 mimalloc을 사용하고 있어야 합니다.
Cargo.toml의 dependencies 섹션에 libmimalloc-sys crate를 추가합니다:- 메모리 사용량 통계를 출력하려는 곳에서마다 다음 코드를 작성하고,
unsafe블록 안에서 mi_stats_print_out()을 호출합니다. 메모리 사용량 통계가 표준 출력으로 출력됩니다. -
왼쪽 상단의
peak/reserved값이 최대 메모리 사용량입니다.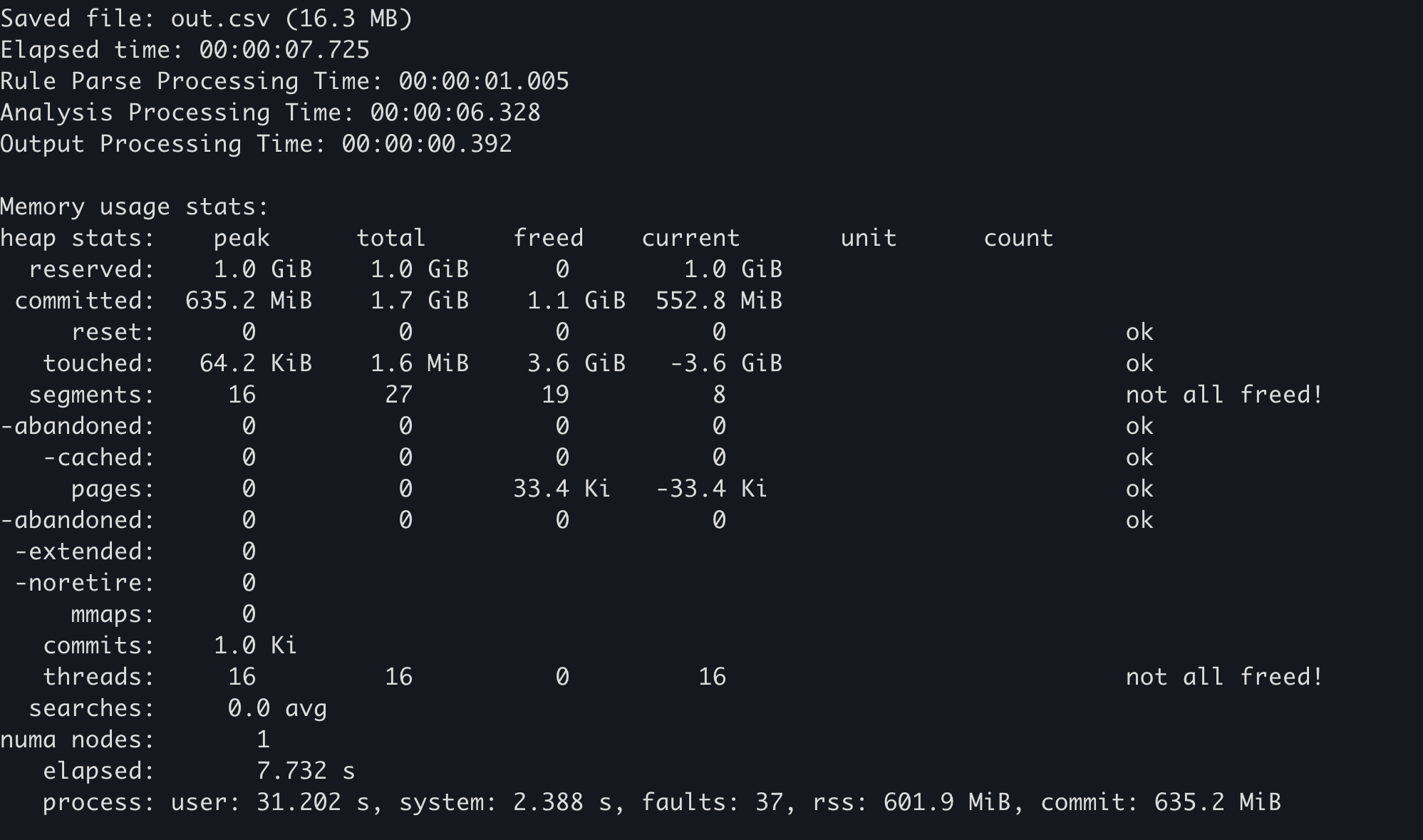
예시 ¶
위 구현은 다음에 적용되었습니다:
Hayabusa에서는 --debug 옵션을 추가하면 마지막에 메모리 사용량 통계가 출력됩니다.
Windows의 성능 카운터 사용¶
OS 측에서 얻을 수 있는 통계로부터 다양한 리소스 사용량을 확인할 수 있습니다. 이 경우, 다음 두 가지 점에 유의해야 합니다.
- 안티바이러스 소프트웨어(Windows Defender)의 영향
- 첫 번째 실행만 스캔의 영향을 받아 더 느리므로, 빌드 후 두 번째 이후의 실행 결과가 비교에 적합합니다. (또는 더 정확한 결과를 위해 안티바이러스를 비활성화할 수 있습니다.)
- 파일 캐싱의 영향
- OS 시작 후 두 번째 이후의 결과는 evtx 및 기타 파일 IO가 메모리의 파일 캐시에서 읽히기 때문에 첫 번째보다 빠릅니다. 따라서 OS 부팅 후 첫 번째 결과가 벤치마크를 취하기에 더 이상적입니다.
얻는 방법 ¶
전제 조건:다음 절차는 Windows에 PowerShell 7이 이미 설치된 환경에서만 유효합니다.
- OS 재시작
PowerShell 7의 Get-Counter 명령을 실행하면 성능 카운터를 1초마다 CSV 파일에 지속적으로 기록합니다. (아래 나열된 것 외의 리소스를 측정하려면 이 글이 좋은 참고가 됩니다.)- 측정하려는 프로세스를 실행합니다.
예시 ¶
다음은 Hayabusa로 성능을 측정하는 예시 절차를 담고 있습니다.
heaptrack 사용¶
heaptrack은 Linux 및 macOS에서 사용할 수 있는 정교한 메모리 프로파일러입니다. heaptrack을 사용하면 병목 현상을 철저히 조사할 수 있습니다.
얻는 방법 ¶
전제 조건: 아래는 Ubuntu 22.04용 절차입니다. Windows에서는 heaptrack을 사용할 수 없습니다.
- 다음 두 명령으로 heaptrack을 설치합니다.
- Hayabusa에서 다음 mimalloc 코드를 제거합니다. (mimalloc에서는 heaptrack의 메모리 프로파일러를 사용할 수 없습니다.
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L32-L33
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L59-L60
-
https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L632-L634
-
Hayabusa의
Cargo.toml파일에서 [profile.release] 섹션을 삭제하고 다음과 같이 변경합니다: -
릴리스 빌드를 빌드합니다:
cargo build --release heaptrack hayabusa csv-timeline -d sample -o out.csv를 실행합니다
이제 Hayabusa 실행이 끝나면 heaptrack의 결과가 자동으로 GUI 애플리케이션에서 열립니다.
예시 ¶
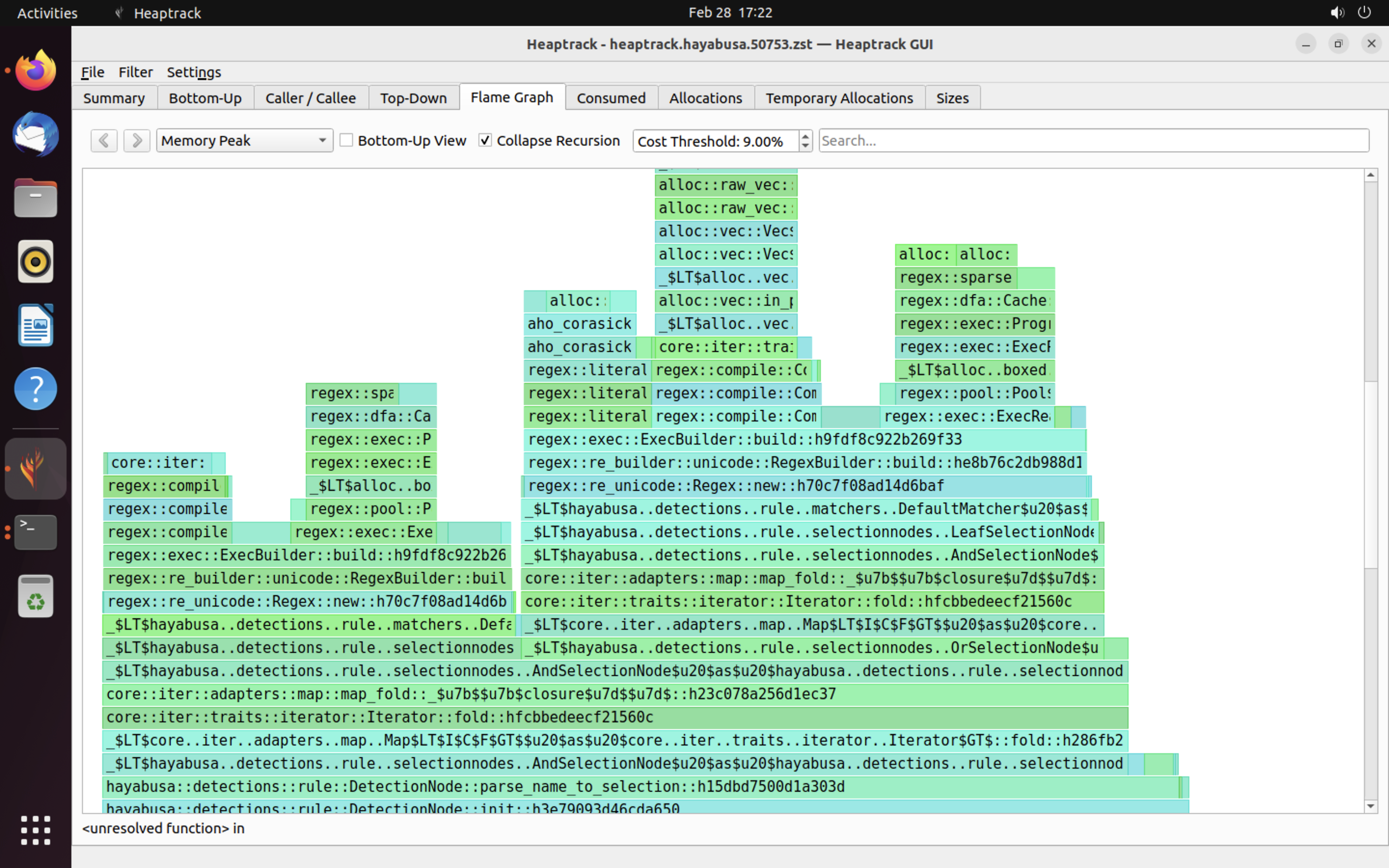
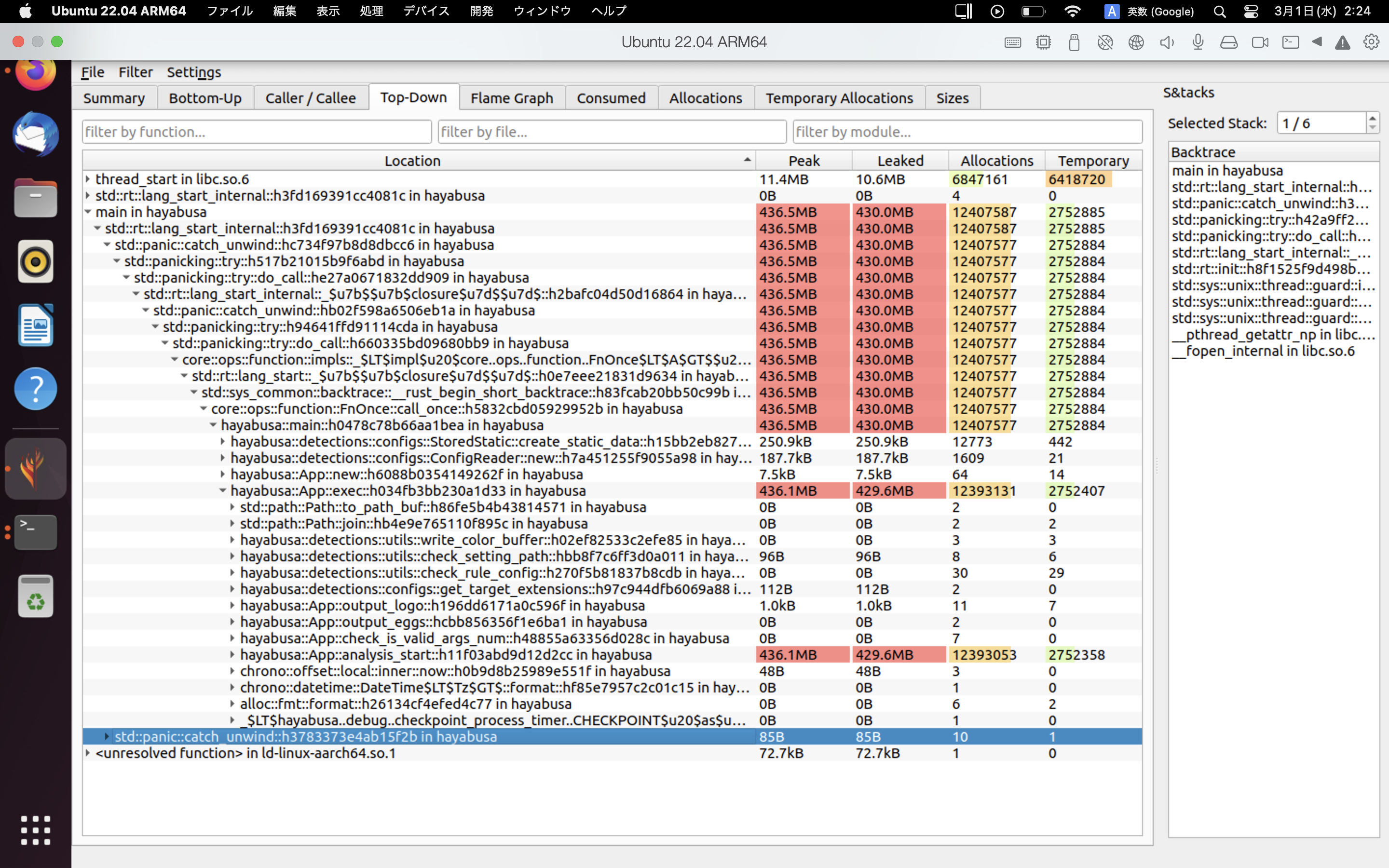
heaptrack 결과의 예시는 아래와 같습니다. Flame Graph 및 Top-Down 탭을 사용하면 메모리 사용량이 높은 함수를 시각적으로 확인할 수 있습니다.
참고 자료¶
기여¶
이 문서는 Hayabusa의 실제 개선 사례에서 얻은 결과를 바탕으로 합니다. 오류나 성능을 개선할 수 있는 기법을 발견하시면, issue 또는 pull request를 보내주시기 바랍니다.