Guía de rendimiento de Rust para desarrolladores de Hayabusa¶
Autor¶
Fukusuke Takahashi
Traducción al inglés¶
Zach Mathis (@yamatosecurity)
Acerca de este documento¶
Hayabusa (en inglés: "peregrine falcon", halcón peregrino) es una herramienta rápida de análisis forense desarrollada por el grupo Yamato Security en Japón. Está desarrollada en Rust para poder cazar (amenazas) tan rápido como un halcón peregrino. Rust es un lenguaje rápido en sí mismo, sin embargo, hay muchas trampas que pueden resultar en velocidades lentas y un alto uso de memoria. Creamos este documento basándonos en mejoras reales de rendimiento en Hayabusa (consulta el registro de cambios aquí), pero estas técnicas también deberían ser aplicables a otros programas de Rust. Esperamos que puedas beneficiarte del conocimiento que hemos adquirido a través de nuestra prueba y error.
Mejora de la velocidad¶
Cambia el asignador de memoria¶
Simplemente cambiar el asignador de memoria predeterminado puede mejorar la velocidad significativamente. Por ejemplo, según estos benchmarks, los siguientes dos asignadores de memoria
son mucho más rápidos que el asignador de memoria predeterminado. Pudimos confirmar una mejora significativa de la velocidad al cambiar nuestro asignador de memoria de jemalloc a mimalloc, por lo que hicimos de mimalloc el predeterminado desde la versión 1.8.0. (Aunque mimalloc usa un poco más de memoria que jemalloc.)
Antes ¶
Después ¶
Solo necesitas realizar los siguientes 2 pasos para cambiar el asignador de memoria global:
- Agrega el crate mimalloc a la sección [dependencies] del archivo
Cargo.toml: - Define que quieres usar mimalloc bajo #[global_allocator] en algún lugar del programa: Eso es todo lo que necesitas hacer para cambiar el asignador de memoria.
Eficacia(Ejemplo real de un Pull Request) ¶
Cuánto mejora la velocidad dependerá del programa, pero en el siguiente ejemplo
cambiar el asignador de memoria a mimalloc resultó en un aumento de rendimiento del 20-30% en CPU Intel. (Por alguna razón, no hubo un aumento de rendimiento tan significativo en dispositivos macOS basados en ARM.)
Reduce el procesamiento de IO en bucles¶
El procesamiento de IO de disco es mucho más lento que el procesamiento en memoria. Por lo tanto, es deseable evitar el procesamiento de IO tanto como sea posible, especialmente en bucles.
Antes ¶
El ejemplo a continuación muestra la apertura de un archivo que ocurre un millón de veces en un bucle:
use std::fs;
fn main() {
for _ in 0..1000000 {
let f = fs::read_to_string("sample.txt").unwrap();
f.len();
}
}
Después ¶
Al abrir el archivo fuera del bucle de la siguiente manera
use std::fs;
fn main() {
let f = fs::read_to_string("sample.txt").unwrap();
for _ in 0..1000000 {
f.len();
}
}
Eficacia(Ejemplo real de un Pull Request) ¶
En el siguiente ejemplo, el procesamiento de IO al manejar un resultado de detección a la vez pudo realizarse fuera del bucle:
Esto resultó en una mejora de velocidad de aproximadamente el 20%.
Evita la compilación de expresiones regulares en bucles¶
La compilación de expresiones regulares es un proceso muy costoso en comparación con la coincidencia de expresiones regulares. Por lo tanto, es aconsejable evitar la compilación de expresiones regulares tanto como sea posible, especialmente en bucles.
Antes ¶
Por ejemplo, el siguiente proceso crea 100.000 intentos de coincidir con una expresión regular en un bucle:
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..100000 {
if Regex::new(match_str).unwrap().is_match(text){ // Regular expression compilation in a loop
println!("matched!");
}
}
}
Después ¶
Al realizar una compilación de expresión regular fuera del bucle, como se muestra a continuación
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap(); // Compile the regular expression outside the loop
for _ in 0..100000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Eficacia(Ejemplo real de un Pull Request) ¶
En el siguiente ejemplo, la compilación de expresiones regulares se realiza fuera del bucle y se almacena en caché.
Esto resultó en mejoras significativas de velocidad.
Usa IO con búfer¶
Sin IO con búfer, el IO de archivos es lento. Con IO con búfer, las operaciones de IO se realizan a través de búferes en memoria, reduciendo el número de llamadas al sistema y mejorando la velocidad.
Antes ¶
Por ejemplo, en el siguiente proceso, write ocurre 1.000.000 de veces.
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
for _ in 0..1000000 {
f.write(b"hello world!");
}
}
Después ¶
Al usar BufWriter de la siguiente manera
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
let mut writer = BufWriter::new(f);
for _ in 0..1000000 {
writer.write(b"some text");
}
writer.flush().unwrap();
}
Eficacia(Ejemplo real de un Pull Request) ¶
El método descrito anteriormente se implementó aquí
y ha resultado en mejoras significativas de velocidad en el procesamiento de salida.
Usa métodos estándar de String en lugar de expresiones regulares¶
Si bien las expresiones regulares pueden cubrir patrones de coincidencia complejos, son más lentas que los métodos estándar de String. Por lo tanto, es más rápido usar métodos estándar de String para coincidencias simples de cadenas como las siguientes.
- Coincidencia de inicio(Regex:
foo.*)-> String::starts_with() - Coincidencia de final(Regex:
.*foo)-> String::ends_with() - Coincidencia de contenido(Regex:
.*foo.*)-> String::contains()
Antes ¶
Por ejemplo, el siguiente código realiza una coincidencia de final con una expresión regular un millón de veces.
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = ".*abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Después ¶
Al usar String::ends_with() de la siguiente manera
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..1000000 {
if text.ends_with(match_str) {
println!("matched!");
}
}
}
Eficacia(Ejemplo real de un Pull Request) ¶
Dado que Hayabusa requiere comparación de cadenas sin distinción de mayúsculas y minúsculas, usamos to_lowercase() y luego aplicamos el método anterior. Aun así, en los siguientes ejemplos
- Imporving speed by changing wildcard search process from regular expression match to starts_with/ends_with match #890
- Improving speed by using eq_ignore_ascii_case() before regular expression match #884
la velocidad ha mejorado aproximadamente un 15% en comparación con antes.
Filtra por longitud de cadena¶
Dependiendo de las características de las cadenas que se manejan, agregar un filtro simple puede reducir el número de intentos de coincidencia de cadenas y acelerar el proceso. Si a menudo comparas cadenas de longitudes no fijas y no coincidentes, puedes acelerar el proceso usando la longitud de la cadena como filtro principal.
Antes ¶
Por ejemplo, el siguiente código intenta un millón de coincidencias de expresión regular.
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Después ¶
Al usar String::len() como filtro principal, como se muestra a continuación
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if text.len() == match_str.len() { // Primary filter by string length
if r.is_match(text) {
println!("matched!");
}
}
}
}
Eficacia(Ejemplo real de un Pull Request) ¶
En el siguiente ejemplo, se utiliza el método anterior.
Esto mejoró la velocidad aproximadamente un 15%.
No compiles con codegen-units=1¶
Muchos artículos sobre optimización de rendimiento con Rust aconsejan agregar codegen-units = 1 bajo la sección [profile.release].
Esto causará tiempos de compilación más lentos ya que el valor predeterminado es compilar en paralelo, pero en teoría debería resultar en código más optimizado y rápido.
Sin embargo, en nuestras pruebas, Hayabusa en realidad se ejecuta más lento con esta opción activada y la compilación tarda más, por lo que la mantenemos desactivada.
El tamaño del binario del ejecutable es aproximadamente 100kb más pequeño, por lo que esto puede ser ideal para sistemas embebidos donde el espacio en disco duro es limitado.
Reducir el uso de memoria¶
Evita el uso innecesario de clone(), to_string() y to_owned()¶
Usar clone() o to_string() son maneras fáciles de resolver errores de compilación relacionados con la propiedad (ownership). Sin embargo, generalmente resultan en un alto uso de memoria y deben evitarse. Siempre es mejor ver primero si puedes reemplazarlos con referencias de bajo costo.
Antes ¶
Por ejemplo, si quieres iterar el mismo Vec varias veces, puedes usar clone() para eliminar errores de compilación.
fn main() {
let lst = vec![1, 2, 3];
for x in lst.clone() { // In order to eliminate compile errors
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
Después ¶
Sin embargo, al usar referencias como se muestra a continuación, puedes eliminar la necesidad de usar clone().
fn main() {
let lst = vec![1, 2, 3];
for x in &lst { // Eliminate compile errors with a reference
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
Eficacia(Ejemplo real de un Pull Request) ¶
En el siguiente ejemplo, al reemplazar el uso innecesario de clone(), to_string() y to_owned(),
pudimos reducir significativamente el uso de memoria.
Usa Iterator en lugar de Vec¶
Vec mantiene todos los elementos en memoria, por lo que usa mucha memoria en proporción al número de elementos. Si procesar un elemento a la vez es suficiente, entonces usar un Iterator en su lugar usará mucha menos memoria.
Antes ¶
Por ejemplo, la siguiente función return_lines() lee un archivo de aproximadamente 1 GB y devuelve un Vec:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> Vec<String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
.collect()
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
Después ¶
En su lugar, deberías devolver un Iterator Trait de la siguiente manera:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> impl Iterator<Item=String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
// ここでcollect()せずに、Iteratorを戻り値として返す
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
Box<dyn Iterator<Item = T>> de la siguiente manera:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines(need_filter:bool) -> Box<dyn Iterator<Item = String>> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
if need_filter {
let result= buf.lines()
.filter_map(|l| l.ok())
.map(|l| l.replace("A", "B"));
return Box::new(result)
}
let result= buf.lines()
.map(|l| l.expect("Could not parse line"));
Box::new(result)
}
fn main() {
let lines = return_lines(true);
for line in lines {
println!("{}", line)
}
}
Eficacia(Ejemplo real de un Pull Request) ¶
El siguiente ejemplo usa el método descrito anteriormente:
Cuando se probó en un archivo JSON de 1.7GB, la memoria disminuyó en un 75%.
Usa el crate compact_str al manejar cadenas cortas¶
Al tratar con una gran cantidad de cadenas cortas de menos de 24 bytes, el crate compact_str puede usarse para reducir el uso de memoria.
Antes ¶
En el ejemplo a continuación, el Vec contiene 10 millones de cadenas.
fn main() {
let v: Vec<String> = vec![String::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
Después ¶
Es mejor reemplazarlas con un CompactString:
use compact_str::CompactString;
fn main() {
let v: Vec<CompactString> = vec![CompactString::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
Eficacia(Ejemplo real de un Pull Request) ¶
En el siguiente ejemplo, las cadenas cortas se manejan con CompactString:
Esto dio una reducción del uso de memoria de aproximadamente el 20%.
Elimina campos innecesarios en estructuras de larga duración¶
Las estructuras que continúan reteniéndose en memoria durante el inicio del proceso pueden afectar el uso general de memoria. En Hayabusa, las siguientes estructuras (a partir de la versión 2.2.2), en particular, se retienen en grandes cantidades.
La eliminación de campos asociados con las estructuras anteriores tuvo cierto efecto en la reducción del uso general de memoria.
Antes ¶
Por ejemplo, el campo DetectInfo era, hasta la versión 1.8.1, el siguiente:
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
pub record_information: CompactString,
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
Después ¶
Al eliminar el campo record_information de la siguiente manera
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
// remove record_information field
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
Eficacia(Ejemplo real de un Pull Request) ¶
En el siguiente ejemplo, cuando se probó contra datos donde el número de registros de resultados de detección era de aproximadamente 1.5 millones,
- Reduced memory usage of DetectInfo/EvtxRecordInfo #837
- Reduce memory usage by removing unnecessary regex #894
pudimos lograr una reducción de aproximadamente 300MB en el uso de memoria.
Benchmarking¶
Usa la función de estadísticas del asignador de memoria.¶
Algunos asignadores de memoria mantienen sus propias estadísticas de uso de memoria. Por ejemplo, en mimalloc, se puede llamar a la función mi_stats_print_out() para obtener el uso de memoria.
Cómo obtener estadísticas ¶
Requisitos previos: Necesitas estar usando mimalloc como se explica en la sección Cambia el asignador de memoria.
- En la sección dependencies de
Cargo.toml, agrega el crate libmimalloc-sys: - Siempre que quieras imprimir las estadísticas de uso de memoria, escribe el siguiente código y dentro de un bloque
unsafe, llama a mi_stats_print_out(). Las estadísticas de uso de memoria se enviarán a la salida estándar. -
El valor
peak/reserveden la parte superior izquierda es el uso máximo de memoria.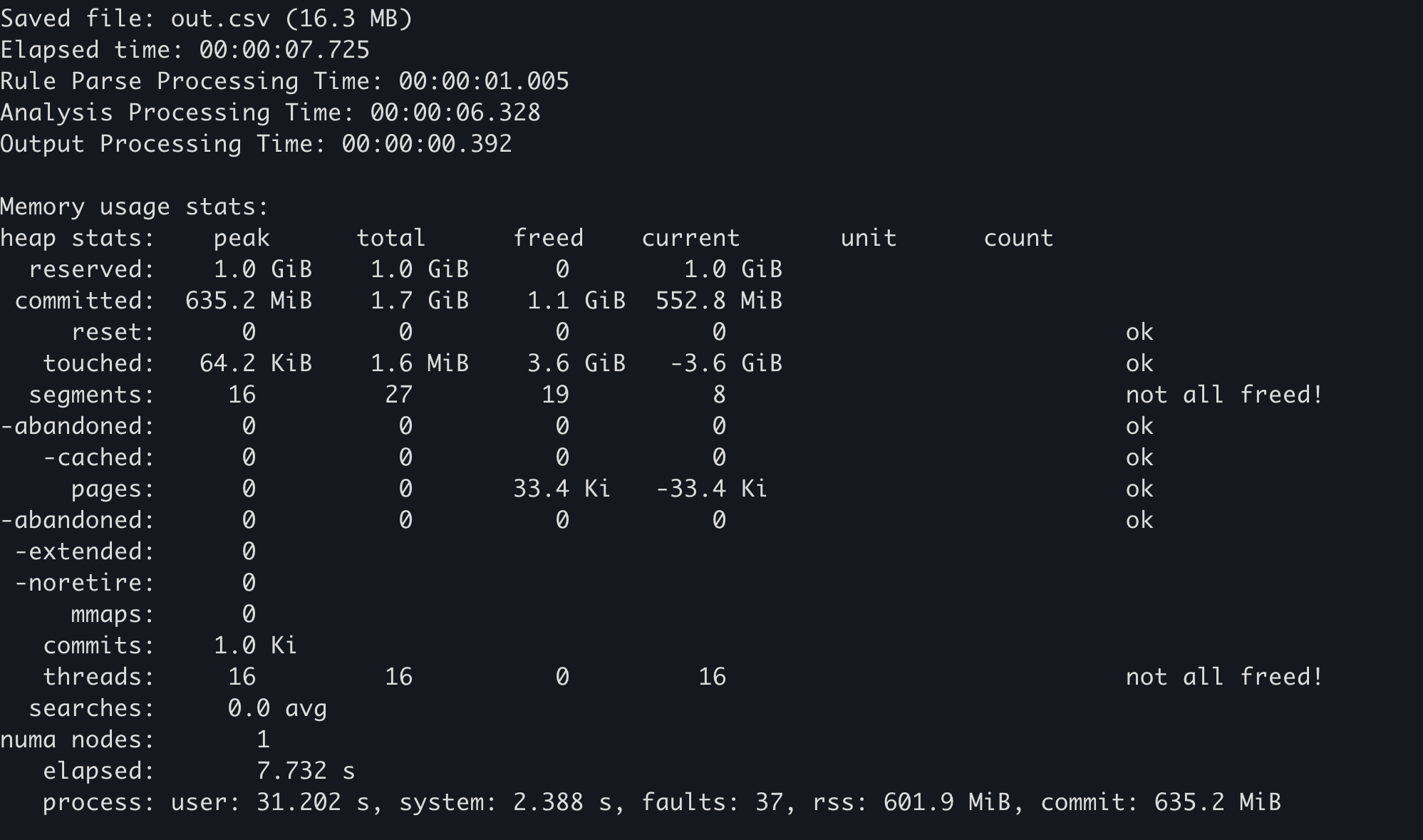
Ejemplo ¶
La implementación anterior se aplicó en lo siguiente:
En Hayabusa, si agregas la opción --debug, las estadísticas de uso de memoria se enviarán al final.
Usa el contador de rendimiento de Windows¶
Se pueden verificar diversos usos de recursos a partir de estadísticas que se pueden obtener del lado del sistema operativo. En este caso, deben tenerse en cuenta los siguientes dos puntos.
- Influencia del software antivirus (Windows Defender)
- Solo la primera ejecución se ve afectada por el escaneo y es más lenta, por lo que los resultados de la segunda ejecución y las siguientes después de la compilación son adecuados para la comparación. (O puedes desactivar tu antivirus para obtener resultados más precisos.)
- Influencia del almacenamiento en caché de archivos
- Los resultados de la segunda vez y las siguientes después del inicio del sistema operativo son más rápidos que la primera vez porque las IO de evtx y otros archivos se leen desde la caché de archivos en memoria, por lo que los resultados de la primera vez después de que el sistema operativo arranca son más ideales para tomar benchmarks.
Cómo obtener ¶
Requisitos previos:El siguiente procedimiento solo es válido para entornos donde PowerShell 7 ya está instalado en Windows.
- Reinicia el sistema operativo
- Ejecuta el comando Get-Counter de
PowerShell 7que registrará continuamente el contador de rendimiento cada segundo en un archivo CSV. (Si deseas medir recursos distintos a los enumerados a continuación, este artículo es una buena referencia.) - Ejecuta el proceso que quieres medir.
Ejemplo ¶
Lo siguiente contiene un procedimiento de ejemplo para medir el rendimiento con Hayabusa.
Usa heaptrack¶
heaptrack es un sofisticado perfilador de memoria disponible para Linux y macOS. Al usar heaptrack, puedes investigar a fondo los cuellos de botella.
Cómo obtener ¶
Requisitos previos: A continuación se muestra el procedimiento para Ubuntu 22.04. No puedes usar heaptrack en Windows.
- Instala heaptrack con los siguientes dos comandos.
- Elimina el siguiente código de mimalloc de Hayabusa. (No puedes usar el perfilador de memoria de heaptrack con mimalloc.
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L32-L33
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L59-L60
-
https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L632-L634
-
Elimina la sección [profile.release] en el archivo
Cargo.tomlde Hayabusa y cámbiala a lo siguiente: -
Compila una compilación de release:
cargo build --release - Ejecuta
heaptrack hayabusa csv-timeline -d sample -o out.csv
Ahora, cuando Hayabusa termine de ejecutarse, los resultados de heaptrack se abrirán automáticamente en una aplicación GUI.
Ejemplos ¶
A continuación se muestra un ejemplo de los resultados de heaptrack. Las pestañas Flame Graph y Top-Down te permiten verificar visualmente las funciones con un alto uso de memoria.
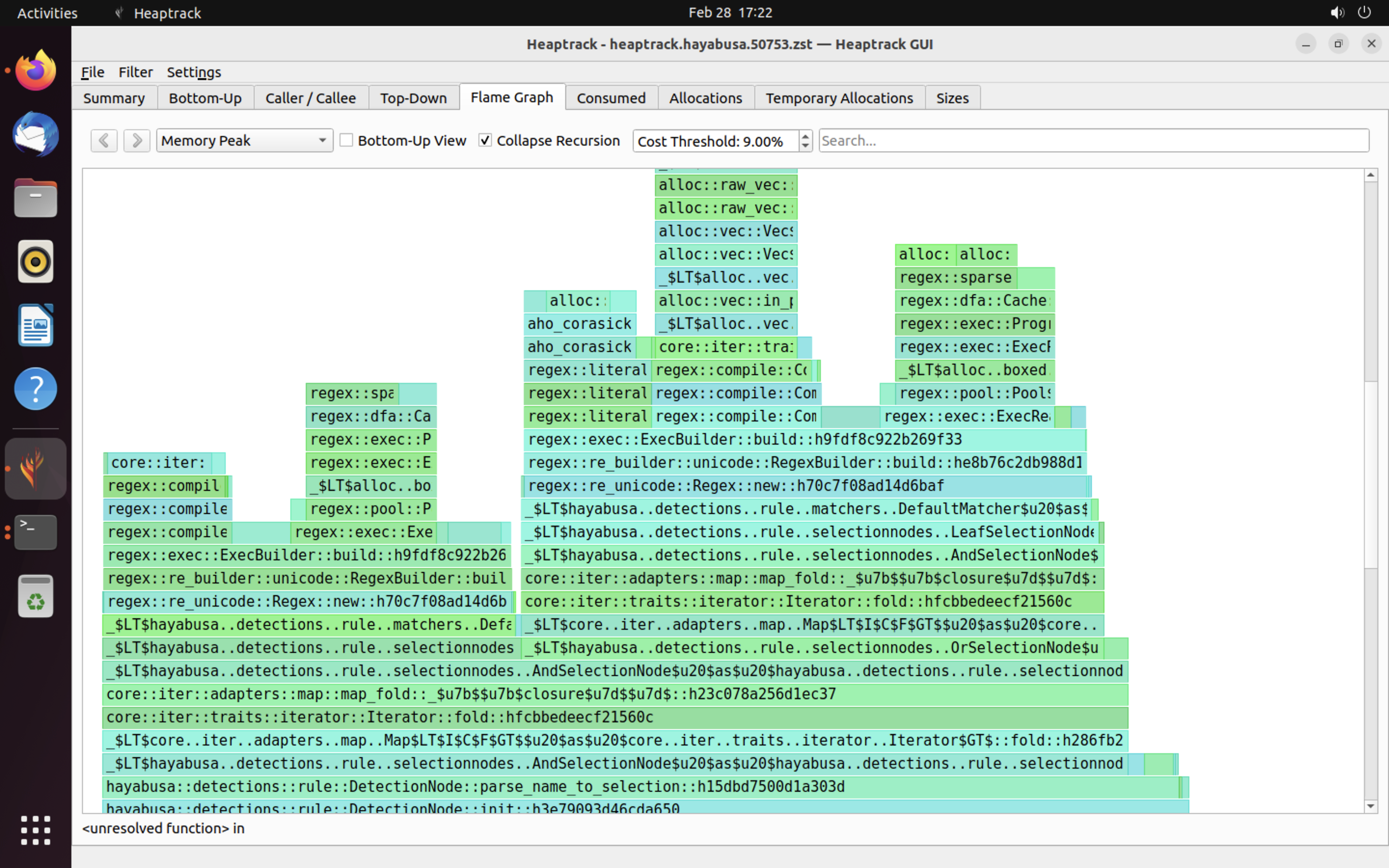
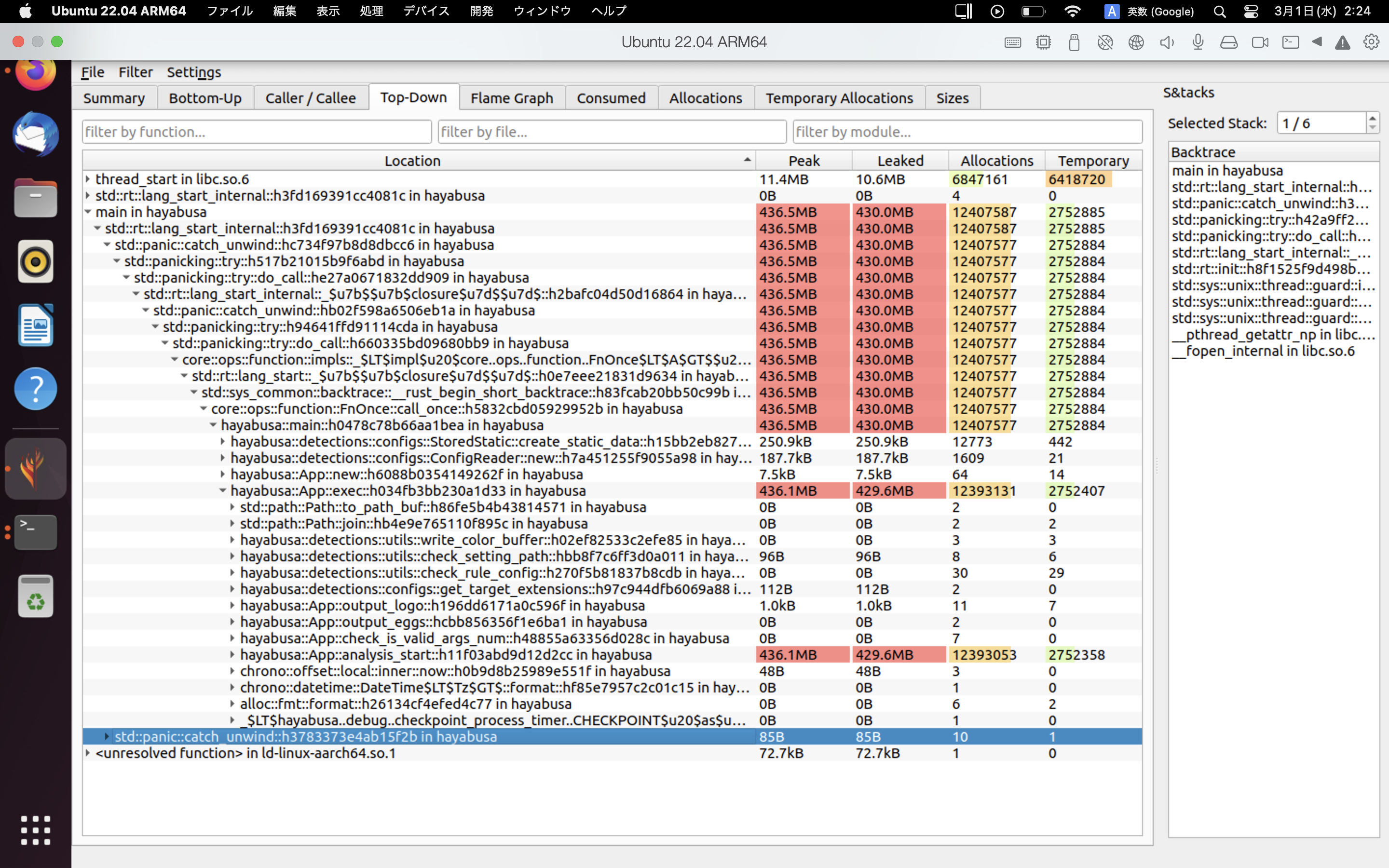
Referencias¶
Contribuciones¶
Este documento se basa en hallazgos de casos reales de mejora en Hayabusa. Si encuentras algún error o técnicas que puedan mejorar el rendimiento, envíanos un issue o un pull request.