Посібник з продуктивності Rust для розробників Hayabusa¶
Автор¶
Fukusuke Takahashi
Англійський переклад¶
Zach Mathis (@yamatosecurity)
Про цей документ¶
Hayabusa (англійською: "peregrine falcon", сапсан) — це швидкий інструмент для криміналістичного аналізу, розроблений групою Yamato Security в Японії. Він розроблений на Rust, щоб полювати (на загрози) так само швидко, як сапсан. Rust сам по собі є швидкою мовою, проте існує багато підводних каменів, які можуть призвести до низької швидкості та високого споживання пам'яті. Ми створили цей документ на основі реальних покращень продуктивності в Hayabusa (див. журнал змін тут), але ці прийоми мають бути застосовними і до інших програм на Rust. Сподіваємося, що ви зможете скористатися знаннями, які ми здобули методом проб і помилок.
Покращення швидкості¶
Змініть розподільник пам'яті¶
Просто зміна стандартного розподільника пам'яті може значно покращити швидкість. Наприклад, згідно з цими бенчмарками, наступні два розподільники пам'яті
є набагато швидшими за стандартний розподільник пам'яті. Нам вдалося підтвердити значне покращення швидкості, змінивши наш розподільник пам'яті з jemalloc на mimalloc, тому ми зробили mimalloc стандартним починаючи з версії 1.8.0. (Хоча mimalloc дійсно використовує трохи більше пам'яті, ніж jemalloc.)
До ¶
Після ¶
Вам потрібно виконати лише наступні 2 кроки, щоб змінити глобальний розподільник пам'яті:
- Додайте крейт mimalloc до секції [dependencies] файлу
Cargo.toml: - Визначте, що ви хочете використовувати mimalloc під #[global_allocator] десь у програмі: Це все, що потрібно зробити, щоб змінити розподільник пам'яті.
Ефективність(Реальний приклад з Pull Request) ¶
Наскільки покращиться швидкість, залежить від програми, але в наступному прикладі
зміна розподільника пам'яті на mimalloc призвела до покращення продуктивності на 20-30% на процесорах Intel. (З якоїсь причини не було такого значного приросту продуктивності на пристроях macOS на базі ARM.)
Зменшіть IO-обробку в циклах¶
Дискова IO-обробка набагато повільніша за обробку в пам'яті. Тому бажано уникати IO-обробки настільки, наскільки це можливо, особливо в циклах.
До ¶
Наведений нижче приклад показує відкриття файлу мільйон разів у циклі:
use std::fs;
fn main() {
for _ in 0..1000000 {
let f = fs::read_to_string("sample.txt").unwrap();
f.len();
}
}
Після ¶
Відкривши файл за межами циклу, як показано нижче
use std::fs;
fn main() {
let f = fs::read_to_string("sample.txt").unwrap();
for _ in 0..1000000 {
f.len();
}
}
Ефективність(Реальний приклад з Pull Request) ¶
У наступному прикладі IO-обробку, що виконувалася при обробці одного результату виявлення за раз, вдалося винести за межі циклу:
Це призвело до покращення швидкості приблизно на 20%.
Уникайте компіляції регулярних виразів у циклах¶
Компіляція регулярних виразів є дуже витратним процесом порівняно зі співставленням регулярних виразів. Тому доцільно уникати компіляції регулярних виразів настільки, наскільки це можливо, особливо в циклах.
До ¶
Наприклад, наступний процес створює 100 000 спроб співставлення регулярного виразу в циклі:
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..100000 {
if Regex::new(match_str).unwrap().is_match(text){ // Regular expression compilation in a loop
println!("matched!");
}
}
}
Після ¶
Виконавши компіляцію регулярного виразу за межами циклу, як показано нижче
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap(); // Compile the regular expression outside the loop
for _ in 0..100000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Ефективність(Реальний приклад з Pull Request) ¶
У наступному прикладі компіляція регулярного виразу виконується за межами циклу та кешується.
Це призвело до значних покращень швидкості.
Використовуйте буферизований IO¶
Без буферизованого IO файловий IO повільний. З буферизованим IO операції IO виконуються через буфери в пам'яті, зменшуючи кількість системних викликів та покращуючи швидкість.
До ¶
Наприклад, у наступному процесі write відбувається 1 000 000 разів.
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
for _ in 0..1000000 {
f.write(b"hello world!");
}
}
Після ¶
Використовуючи BufWriter, як показано нижче
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
let mut writer = BufWriter::new(f);
for _ in 0..1000000 {
writer.write(b"some text");
}
writer.flush().unwrap();
}
Ефективність(Реальний приклад з Pull Request) ¶
Описаний вище метод був реалізований тут
і призвів до значних покращень швидкості в обробці виведення.
Використовуйте стандартні методи String замість регулярних виразів¶
Хоча регулярні вирази можуть охоплювати складні шаблони співставлення, вони повільніші за стандартні методи String. Тому швидше використовувати стандартні методи String для простого співставлення рядків, як, наприклад, наступне.
- Співставлення за початком(Regex:
foo.*)-> String::starts_with() - Співставлення за закінченням(Regex:
.*foo)-> String::ends_with() - Співставлення за входженням(Regex:
.*foo.*)-> String::contains()
До ¶
Наприклад, наступний код виконує співставлення за закінченням у регулярному виразі мільйон разів.
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = ".*abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Після ¶
Використовуючи String::ends_with(), як показано нижче
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..1000000 {
if text.ends_with(match_str) {
println!("matched!");
}
}
}
Ефективність(Реальний приклад з Pull Request) ¶
Оскільки Hayabusa потребує порівняння рядків без урахування регістру, ми використовуємо to_lowercase(), а потім застосовуємо вищезгаданий метод. Навіть тоді, у наступних прикладах
- Imporving speed by changing wildcard search process from regular expression match to starts_with/ends_with match #890
- Improving speed by using eq_ignore_ascii_case() before regular expression match #884
швидкість покращилася приблизно на 15% порівняно з попередньою.
Фільтруйте за довжиною рядка¶
Залежно від характеристик рядків, що обробляються, додавання простого фільтра може зменшити кількість спроб співставлення рядків та прискорити процес. Якщо ви часто порівнюєте рядки нефіксованої та неспівпадаючої довжини, ви можете прискорити процес, використовуючи довжину рядка як первинний фільтр.
До ¶
Наприклад, наступний код намагається виконати мільйон співставлень регулярних виразів.
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Після ¶
Використовуючи String::len() як первинний фільтр, як показано нижче
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if text.len() == match_str.len() { // Primary filter by string length
if r.is_match(text) {
println!("matched!");
}
}
}
}
Ефективність(Реальний приклад з Pull Request) ¶
У наступному прикладі використовується вищезгаданий метод.
Це покращило швидкість приблизно на 15%.
Не компілюйте з codegen-units=1¶
Багато статей про оптимізацію продуктивності з Rust радять додати codegen-units = 1 під секцією [profile.release].
Це призведе до повільнішого часу компіляції, оскільки за замовчуванням компіляція відбувається паралельно, але теоретично має призвести до більш оптимізованого та швидшого коду.
Однак у наших тестах Hayabusa насправді працює повільніше з увімкненою цією опцією, і компіляція займає більше часу, тому ми тримаємо це вимкненим.
Розмір бінарного файлу виконуваного файлу приблизно на 100kb менший, тому це може бути ідеальним для вбудованих систем, де простір на жорсткому диску обмежений.
Зменшення споживання пам'яті¶
Уникайте непотрібного використання clone(), to_string() та to_owned()¶
Використання clone() або to_string() — це прості способи вирішення помилок компіляції, пов'язаних із володінням. Однак вони зазвичай призводять до високого споживання пам'яті, і їх слід уникати. Завжди найкраще спочатку перевірити, чи можете ви замінити їх на низьковитратні посилання.
До ¶
Наприклад, якщо ви хочете ітерувати один і той самий Vec кілька разів, ви можете використати clone(), щоб усунути помилки компіляції.
fn main() {
let lst = vec![1, 2, 3];
for x in lst.clone() { // In order to eliminate compile errors
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
Після ¶
Однак, використовуючи посилання, як показано нижче, ви можете усунути потребу у використанні clone().
fn main() {
let lst = vec![1, 2, 3];
for x in &lst { // Eliminate compile errors with a reference
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
Ефективність(Реальний приклад з Pull Request) ¶
У наступному прикладі, замінивши непотрібне використання clone(), to_string() та to_owned(),
нам вдалося значно зменшити споживання пам'яті.
Використовуйте Iterator замість Vec¶
Vec зберігає всі елементи в пам'яті, тому він використовує багато пам'яті пропорційно до кількості елементів. Якщо достатньо обробляти один елемент за раз, то використання Iterator замість нього використовуватиме набагато менше пам'яті.
До ¶
Наприклад, наступна функція return_lines() читає файл розміром близько 1 ГБ і повертає Vec:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> Vec<String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
.collect()
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
Після ¶
Замість цього ви повинні повертати Iterator Trait, як показано нижче:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> impl Iterator<Item=String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
// ここでcollect()せずに、Iteratorを戻り値として返す
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
Box<dyn Iterator<Item = T>>, як показано нижче:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines(need_filter:bool) -> Box<dyn Iterator<Item = String>> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
if need_filter {
let result= buf.lines()
.filter_map(|l| l.ok())
.map(|l| l.replace("A", "B"));
return Box::new(result)
}
let result= buf.lines()
.map(|l| l.expect("Could not parse line"));
Box::new(result)
}
fn main() {
let lines = return_lines(true);
for line in lines {
println!("{}", line)
}
}
Ефективність(Реальний приклад з Pull Request) ¶
Наступний приклад використовує описаний вище метод:
Під час тестування на JSON-файлі розміром 1.7ГБ пам'ять зменшилася на 75%.
Використовуйте крейт compact_str при обробці коротких рядків¶
При роботі з великою кількістю коротких рядків розміром менше 24 байтів можна використовувати крейт compact_str, щоб зменшити споживання пам'яті.
До ¶
У наведеному нижче прикладі Vec містить 10 мільйонів рядків.
fn main() {
let v: Vec<String> = vec![String::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
Після ¶
Краще замінити їх на CompactString:
use compact_str::CompactString;
fn main() {
let v: Vec<CompactString> = vec![CompactString::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
Ефективність(Реальний приклад з Pull Request) ¶
У наступному прикладі короткі рядки обробляються за допомогою CompactString:
Це дало зменшення споживання пам'яті приблизно на 20%.
Видаляйте непотрібні поля в довгоживучих структурах¶
Структури, які продовжують зберігатися в пам'яті під час запуску процесу, можуть впливати на загальне споживання пам'яті. У Hayabusa наступні структури (станом на версію 2.2.2), зокрема, зберігаються у великій кількості.
Видалення полів, пов'язаних із вищезгаданими структурами, мало певний ефект на зменшення загального споживання пам'яті.
До ¶
Наприклад, поле DetectInfo було, до версії 1.8.1, наступним:
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
pub record_information: CompactString,
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
Після ¶
Видаливши поле record_information, як показано нижче
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
// remove record_information field
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
Ефективність(Реальний приклад з Pull Request) ¶
У наступному прикладі, при тестуванні на даних, де кількість записів результатів виявлення становила близько 1,5 мільйона,
- Reduced memory usage of DetectInfo/EvtxRecordInfo #837
- Reduce memory usage by removing unnecessary regex #894
нам вдалося досягти зменшення споживання пам'яті приблизно на 300МБ.
Бенчмаркінг¶
Використовуйте функцію статистики розподільника пам'яті.¶
Деякі розподільники пам'яті ведуть власну статистику споживання пам'яті. Наприклад, у mimalloc функцію mi_stats_print_out() можна викликати для отримання споживання пам'яті.
Як отримати статистику ¶
Передумови: Вам потрібно використовувати mimalloc, як пояснено в розділі Змініть розподільник пам'яті.
- У секції dependencies файлу
Cargo.tomlдодайте крейт libmimalloc-sys: - Щоразу, коли ви хочете вивести статистику споживання пам'яті, напишіть наступний код і всередині блоку
unsafeвикличте mi_stats_print_out(). Статистика споживання пам'яті буде виведена на стандартний вивід. -
Значення
peak/reservedу верхньому лівому куті — це максимальне споживання пам'яті.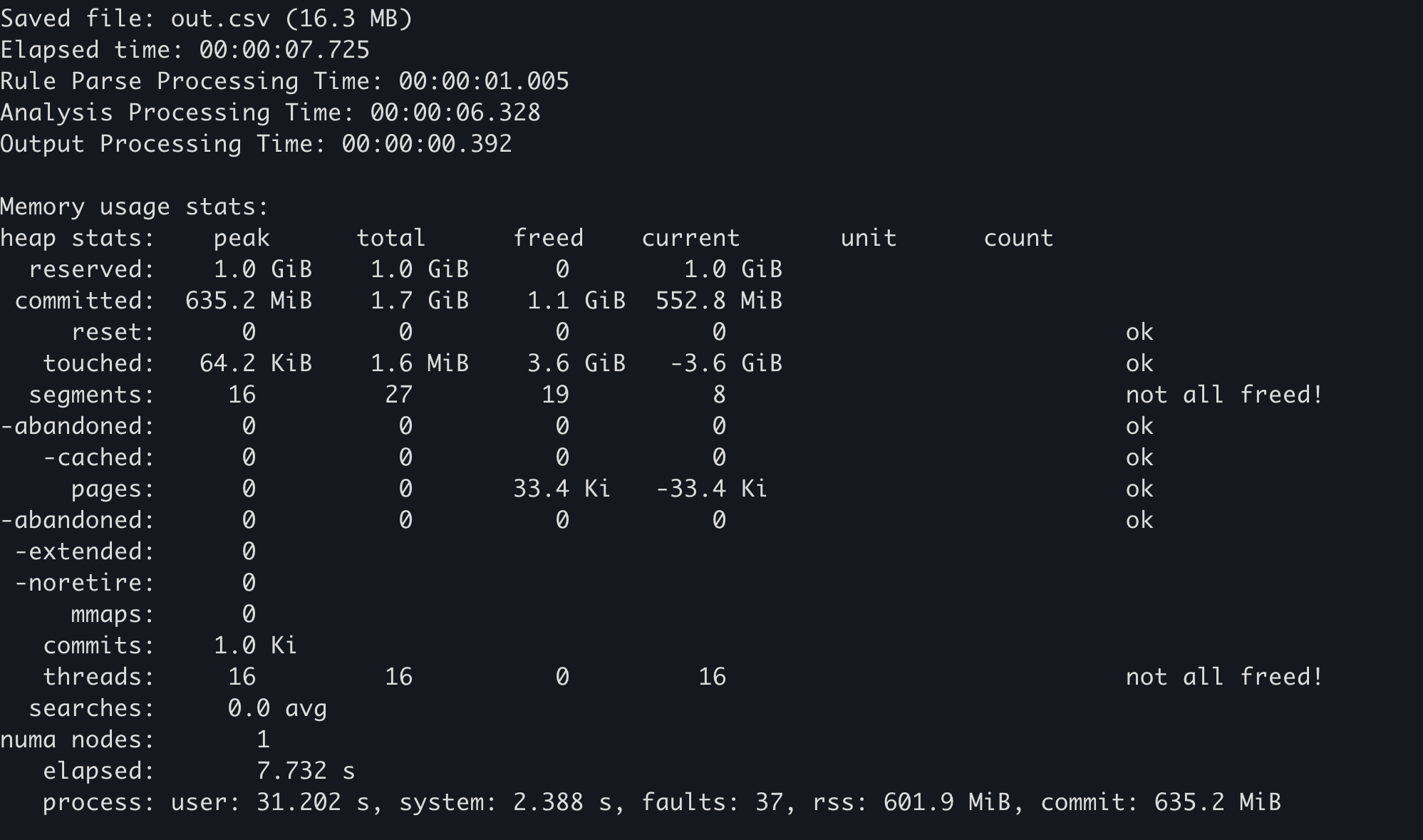
Приклад ¶
Вищезгадана реалізація була застосована в наступному:
У Hayabusa, якщо ви додасте опцію --debug, статистика споживання пам'яті буде виведена в кінці.
Використовуйте лічильник продуктивності Windows¶
Різне використання ресурсів можна перевірити за статистикою, яку можна отримати на боці ОС. У цьому випадку слід звернути увагу на наступні два моменти.
- Вплив антивірусного програмного забезпечення (Windows Defender)
- Лише перший запуск зазнає впливу сканування і є повільнішим, тому результати другого та наступних запусків після збірки придатні для порівняння. (Або ви можете вимкнути антивірус для більш точних результатів.)
- Вплив кешування файлів
- Результати другого та наступних разів після запуску ОС швидші за перший раз, оскільки evtx та інші файлові IO читаються з кешу файлів у пам'яті, тому результати першого разу після завантаження ОС більш ідеальні для проведення бенчмарків.
Як отримати ¶
Передумови:Наступна процедура дійсна лише для середовищ, де PowerShell 7 вже встановлений на Windows.
- Перезавантажте ОС
- Запустіть команду Get-Counter у
PowerShell 7, яка буде безперервно записувати лічильник продуктивності щосекунди у CSV-файл. (Якщо ви хочете виміряти ресурси, відмінні від наведених нижче, ця стаття є хорошим орієнтиром.) - Виконайте процес, який ви хочете виміряти.
Приклад ¶
Нижче наведено приклад процедури вимірювання продуктивності з Hayabusa.
Використовуйте heaptrack¶
heaptrack — це досконалий профайлер пам'яті, доступний для Linux та macOS. Використовуючи heaptrack, ви можете ретельно дослідити вузькі місця.
Як отримати ¶
Передумови: Нижче наведено процедуру для Ubuntu 22.04. Ви не можете використовувати heaptrack на Windows.
- Встановіть heaptrack за допомогою наступних двох команд.
- Видаліть наступний код mimalloc з Hayabusa. (Ви не можете використовувати профайлер пам'яті heaptrack з mimalloc.
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L32-L33
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L59-L60
-
https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L632-L634
-
Видаліть секцію [profile.release] у файлі
Cargo.tomlHayabusa та змініть її на наступне: -
Зберіть реліз-збірку:
cargo build --release - Запустіть
heaptrack hayabusa csv-timeline -d sample -o out.csv
Тепер, коли Hayabusa завершить роботу, результати heaptrack автоматично відкриються у GUI-застосунку.
Приклади ¶
Приклад результатів heaptrack показано нижче. Вкладки Flame Graph та Top-Down дозволяють візуально перевірити функції з високим споживанням пам'яті.
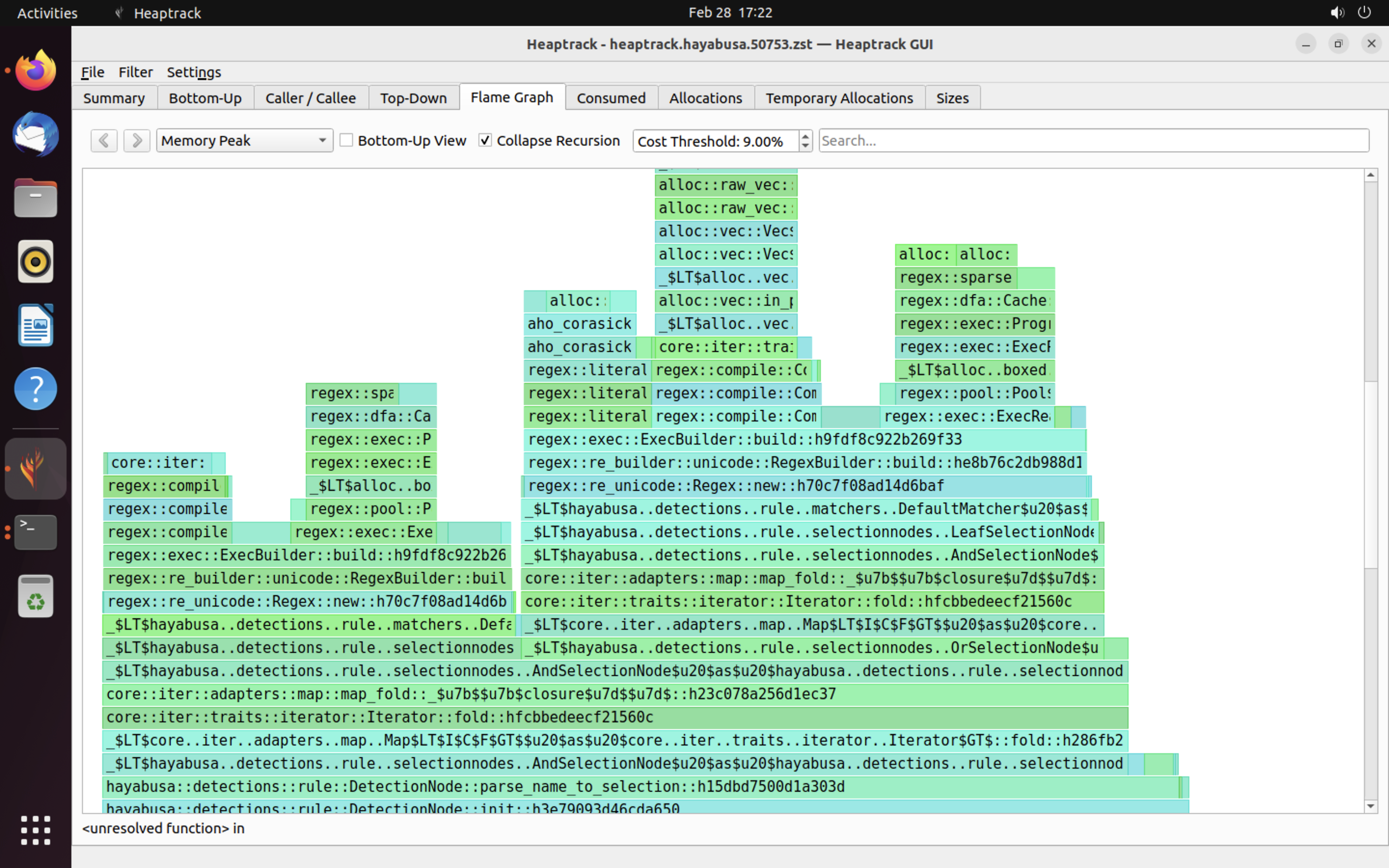
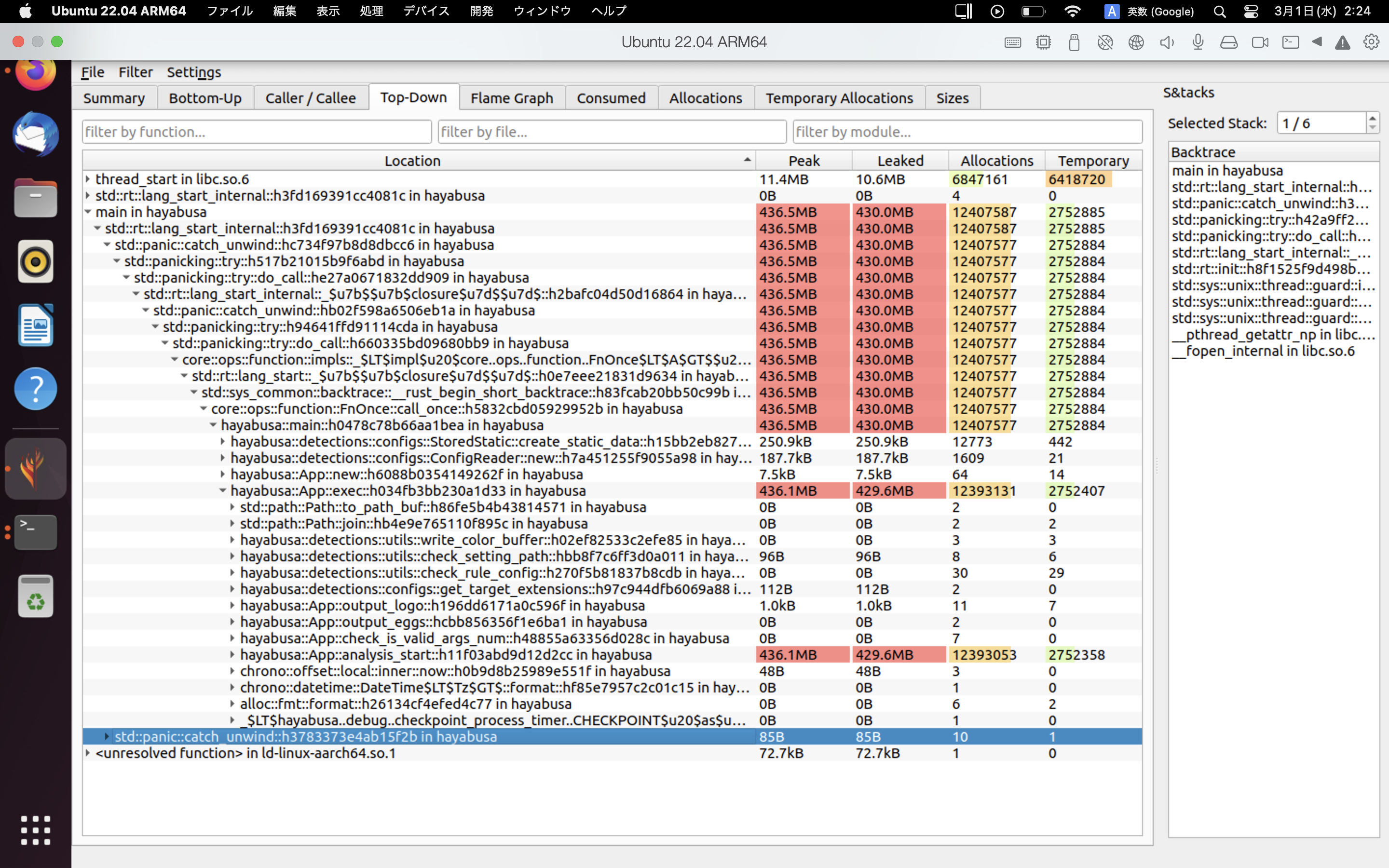
Посилання¶
Внески¶
Цей документ ґрунтується на висновках з реальних випадків покращення в Hayabusa. Якщо ви знайдете будь-які помилки або прийоми, які можуть покращити продуктивність, будь ласка, надішліть нам issue або pull request.