Guia de Performance em Rust para Desenvolvedores do Hayabusa¶
Autor¶
Fukusuke Takahashi
Tradução para o inglês¶
Zach Mathis (@yamatosecurity)
Sobre este documento¶
O Hayabusa (em inglês: "peregrine falcon", o falcão-peregrino) é uma ferramenta rápida de análise forense desenvolvida pelo grupo Yamato Security no Japão. Ele é desenvolvido em Rust para caçar (ameaças) tão rápido quanto um falcão-peregrino. Rust é, por si só, uma linguagem rápida, porém existem muitas armadilhas que podem resultar em baixa velocidade e alto uso de memória. Criamos este documento com base em melhorias de performance reais no Hayabusa (veja o changelog aqui), mas essas técnicas também devem ser aplicáveis a outros programas em Rust. Esperamos que você possa se beneficiar do conhecimento que adquirimos por meio de nossa tentativa e erro.
Melhoria de velocidade¶
Troque o alocador de memória¶
Simplesmente trocar o alocador de memória padrão pode melhorar a velocidade significativamente. Por exemplo, de acordo com estes benchmarks, os dois alocadores de memória a seguir
são muito mais rápidos que o alocador de memória padrão. Conseguimos confirmar uma melhoria significativa de velocidade ao trocar nosso alocador de memória de jemalloc para mimalloc, então tornamos o mimalloc o padrão desde a versão 1.8.0. (Embora o mimalloc use um pouco mais de memória que o jemalloc.)
Antes ¶
Depois ¶
Você só precisa realizar os 2 passos a seguir para trocar o alocador de memória global:
- Adicione o crate mimalloc à seção [dependencies] do arquivo
Cargo.toml: - Defina que você quer usar o mimalloc sob #[global_allocator] em algum lugar do programa: Isso é tudo o que você precisa fazer para trocar o alocador de memória.
Eficácia(Exemplo real de um Pull Request) ¶
O quanto a velocidade melhora vai depender do programa, mas no exemplo a seguir
trocar o alocador de memória para mimalloc resultou em um aumento de performance de 20-30% em CPUs Intel. (Por algum motivo, não houve um aumento de performance tão significativo em dispositivos macOS baseados em ARM.)
Reduza o processamento de IO em loops¶
O processamento de IO em disco é muito mais lento que o processamento em memória. Portanto, é desejável evitar o processamento de IO o máximo possível, especialmente em loops.
Antes ¶
O exemplo abaixo mostra a abertura de um arquivo ocorrendo um milhão de vezes em um loop:
use std::fs;
fn main() {
for _ in 0..1000000 {
let f = fs::read_to_string("sample.txt").unwrap();
f.len();
}
}
Depois ¶
Ao abrir o arquivo fora do loop, da seguinte forma
use std::fs;
fn main() {
let f = fs::read_to_string("sample.txt").unwrap();
for _ in 0..1000000 {
f.len();
}
}
Eficácia(Exemplo real de um Pull Request) ¶
No exemplo a seguir, o processamento de IO ao lidar com um resultado de detecção por vez pôde ser realizado fora do loop:
Isso resultou em uma melhoria de velocidade de cerca de 20%.
Evite a compilação de expressões regulares em loops¶
A compilação de expressões regulares é um processo muito custoso comparado à correspondência de expressões regulares. Portanto, é aconselhável evitar a compilação de expressões regulares o máximo possível, especialmente em loops.
Antes ¶
Por exemplo, o processo a seguir cria 100.000 tentativas de correspondência de uma expressão regular em um loop:
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..100000 {
if Regex::new(match_str).unwrap().is_match(text){ // Regular expression compilation in a loop
println!("matched!");
}
}
}
Depois ¶
Ao fazer a compilação da expressão regular fora do loop, como mostrado abaixo
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap(); // Compile the regular expression outside the loop
for _ in 0..100000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Eficácia(Exemplo real de um Pull Request) ¶
No exemplo a seguir, a compilação de expressões regulares é realizada fora do loop e armazenada em cache.
Isso resultou em melhorias significativas de velocidade.
Use IO com buffer¶
Sem IO com buffer, o IO de arquivos é lento. Com IO com buffer, as operações de IO são realizadas por meio de buffers em memória, reduzindo o número de chamadas de sistema e melhorando a velocidade.
Antes ¶
Por exemplo, no processo a seguir, o write ocorre 1.000.000 de vezes.
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
for _ in 0..1000000 {
f.write(b"hello world!");
}
}
Depois ¶
Ao usar o BufWriter da seguinte forma
use std::fs::File;
use std::io::{BufWriter, Write};
fn main() {
let mut f = File::create("sample.txt").unwrap();
let mut writer = BufWriter::new(f);
for _ in 0..1000000 {
writer.write(b"some text");
}
writer.flush().unwrap();
}
Eficácia(Exemplo real de um Pull Request) ¶
O método descrito acima foi implementado aqui
e resultou em melhorias significativas de velocidade no processamento de saída.
Use métodos padrão de String em vez de expressões regulares¶
Embora as expressões regulares possam cobrir padrões de correspondência complexos, elas são mais lentas que os métodos padrão de String. Portanto, é mais rápido usar métodos padrão de String para correspondências simples de strings, como as seguintes.
- Correspondência por início(Regex:
foo.*)-> String::starts_with() - Correspondência por fim(Regex:
.*foo)-> String::ends_with() - Correspondência por conteúdo(Regex:
.*foo.*)-> String::contains()
Antes ¶
Por exemplo, o código a seguir realiza uma correspondência por fim com uma expressão regular um milhão de vezes.
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = ".*abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Depois ¶
Ao usar o String::ends_with() da seguinte forma
fn main() {
let text = "1234567890";
let match_str = "abc";
for _ in 0..1000000 {
if text.ends_with(match_str) {
println!("matched!");
}
}
}
Eficácia(Exemplo real de um Pull Request) ¶
Como o Hayabusa requer comparação de strings sem diferenciação entre maiúsculas e minúsculas, usamos o to_lowercase() e então aplicamos o método acima. Mesmo assim, nos exemplos a seguir
- Imporving speed by changing wildcard search process from regular expression match to starts_with/ends_with match #890
- Improving speed by using eq_ignore_ascii_case() before regular expression match #884
a velocidade melhorou cerca de 15% em comparação com antes.
Filtre por tamanho da string¶
Dependendo das características das strings sendo manipuladas, adicionar um filtro simples pode reduzir o número de tentativas de correspondência de strings e acelerar o processo. Se você frequentemente compara strings de tamanhos não fixos e não correspondentes, pode acelerar o processo usando o tamanho da string como filtro primário.
Antes ¶
Por exemplo, o código a seguir tenta um milhão de correspondências de expressões regulares.
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if r.is_match(text) {
println!("matched!");
}
}
}
Depois ¶
Ao usar o String::len() como filtro primário, como mostrado abaixo
extern crate regex;
use regex::Regex;
fn main() {
let text = "1234567890";
let match_str = "abc";
let r = Regex::new(match_str).unwrap();
for _ in 0..1000000 {
if text.len() == match_str.len() { // Primary filter by string length
if r.is_match(text) {
println!("matched!");
}
}
}
}
Eficácia(Exemplo real de um Pull Request) ¶
No exemplo a seguir, o método acima é usado.
Isso melhorou a velocidade em cerca de 15%.
Não compile com codegen-units=1¶
Muitos artigos sobre otimização de performance com Rust aconselham adicionar codegen-units = 1 sob a seção [profile.release].
Isso causará tempos de compilação mais lentos, já que o padrão é compilar em paralelo, mas em teoria deveria resultar em um código mais otimizado e rápido.
No entanto, em nossos testes, o Hayabusa na verdade roda mais devagar com essa opção ativada e a compilação demora mais, então mantemos isso desativado.
O tamanho do binário do executável fica cerca de 100kb menor, então isso pode ser ideal para sistemas embarcados onde o espaço em disco é limitado.
Reduzindo o uso de memória¶
Evite o uso desnecessário de clone(), to_string() e to_owned()¶
Usar clone() ou to_string() são maneiras fáceis de resolver erros de compilação relacionados a ownership. No entanto, eles geralmente resultam em alto uso de memória e devem ser evitados. É sempre melhor primeiro ver se você consegue substituí-los por referências de baixo custo.
Antes ¶
Por exemplo, se você quiser iterar o mesmo Vec várias vezes, pode usar o clone() para eliminar erros de compilação.
fn main() {
let lst = vec![1, 2, 3];
for x in lst.clone() { // In order to eliminate compile errors
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
Depois ¶
No entanto, ao usar referências como mostrado abaixo, você pode eliminar a necessidade de usar o clone().
fn main() {
let lst = vec![1, 2, 3];
for x in &lst { // Eliminate compile errors with a reference
println!("{x}");
}
for x in lst {
println!("{x}");
}
}
Eficácia(Exemplo real de um Pull Request) ¶
No exemplo a seguir, ao substituir o uso desnecessário de clone(), to_string() e to_owned(),
conseguimos reduzir significativamente o uso de memória.
Use Iterator em vez de Vec¶
O Vec mantém todos os elementos em memória, então usa muita memória em proporção ao número de elementos. Se processar um elemento por vez for suficiente, então usar um Iterator em vez disso usará muito menos memória.
Antes ¶
Por exemplo, a função return_lines() a seguir lê um arquivo de cerca de 1 GB e retorna um Vec:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> Vec<String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
.collect()
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
Depois ¶
Em vez disso, você deve retornar um Iterator Trait da seguinte forma:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines() -> impl Iterator<Item=String> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
buf.lines()
.map(|l| l.expect("Could not parse line"))
// ここでcollect()せずに、Iteratorを戻り値として返す
}
fn main() {
let lines = return_lines();
for line in lines {
println!("{}", line)
}
}
Box<dyn Iterator<Item = T>> da seguinte forma:
use std::fs::File;
use std::io::{BufRead, BufReader};
fn return_lines(need_filter:bool) -> Box<dyn Iterator<Item = String>> {
let f = File::open("sample.txt").unwrap();
let buf = BufReader::new(f);
if need_filter {
let result= buf.lines()
.filter_map(|l| l.ok())
.map(|l| l.replace("A", "B"));
return Box::new(result)
}
let result= buf.lines()
.map(|l| l.expect("Could not parse line"));
Box::new(result)
}
fn main() {
let lines = return_lines(true);
for line in lines {
println!("{}", line)
}
}
Eficácia(Exemplo real de um Pull Request) ¶
O exemplo a seguir usa o método descrito acima:
Quando testado em um arquivo JSON de 1.7GB, a memória diminuiu em 75%.
Use o crate compact_str ao lidar com strings curtas¶
Ao lidar com um grande número de strings curtas de menos de 24 bytes, o crate compact_str pode ser usado para reduzir o uso de memória.
Antes ¶
No exemplo abaixo, o Vec armazena 10 milhões de strings.
fn main() {
let v: Vec<String> = vec![String::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
Depois ¶
É melhor substituí-las por uma CompactString:
use compact_str::CompactString;
fn main() {
let v: Vec<CompactString> = vec![CompactString::from("ABCDEFGHIJKLMNOPQRSTUV"); 10000000];
// do some kind of processing
}
Eficácia(Exemplo real de um Pull Request) ¶
No exemplo a seguir, strings curtas são manipuladas com a CompactString:
Isso proporcionou uma redução de uso de memória de cerca de 20%.
Exclua campos desnecessários em estruturas de longa duração¶
Estruturas que continuam retidas em memória durante a execução do processo podem afetar o uso geral de memória. No Hayabusa, as estruturas a seguir (na versão 2.2.2), em particular, são retidas em grande quantidade.
A remoção de campos associados às estruturas acima teve algum efeito na redução do uso geral de memória.
Antes ¶
Por exemplo, o campo DetectInfo era, até a versão 1.8.1, o seguinte:
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
pub record_information: CompactString,
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
Depois ¶
Ao excluir o campo record_information da seguinte forma
#[derive(Debug, Clone)]
pub struct DetectInfo {
pub rulepath: CompactString,
pub ruletitle: CompactString,
pub level: CompactString,
pub computername: CompactString,
pub eventid: CompactString,
pub detail: CompactString,
// remove record_information field
pub ext_field: Vec<(CompactString, Profile)>,
pub is_condition: bool,
}
Eficácia(Exemplo real de um Pull Request) ¶
No exemplo a seguir, quando testado com dados onde o número de registros de resultado de detecção era de cerca de 1,5 milhão,
- Reduced memory usage of DetectInfo/EvtxRecordInfo #837
- Reduce memory usage by removing unnecessary regex #894
conseguimos alcançar uma redução de cerca de 300MB no uso de memória.
Benchmarking¶
Use a função de estatísticas do alocador de memória.¶
Alguns alocadores de memória mantêm suas próprias estatísticas de uso de memória. Por exemplo, no mimalloc, a função mi_stats_print_out() pode ser chamada para obter o uso de memória.
Como obter estatísticas ¶
Pré-requisitos: Você precisa estar usando o mimalloc conforme explicado na seção Troque o alocador de memória.
- No
Cargo.toml, seção dependencies, adicione o crate libmimalloc-sys: - Sempre que você quiser imprimir as estatísticas de uso de memória, escreva o código a seguir e, dentro de um bloco
unsafe, chame a mi_stats_print_out(). As estatísticas de uso de memória serão enviadas para a saída padrão. -
O valor
peak/reservedno canto superior esquerdo é o uso máximo de memória.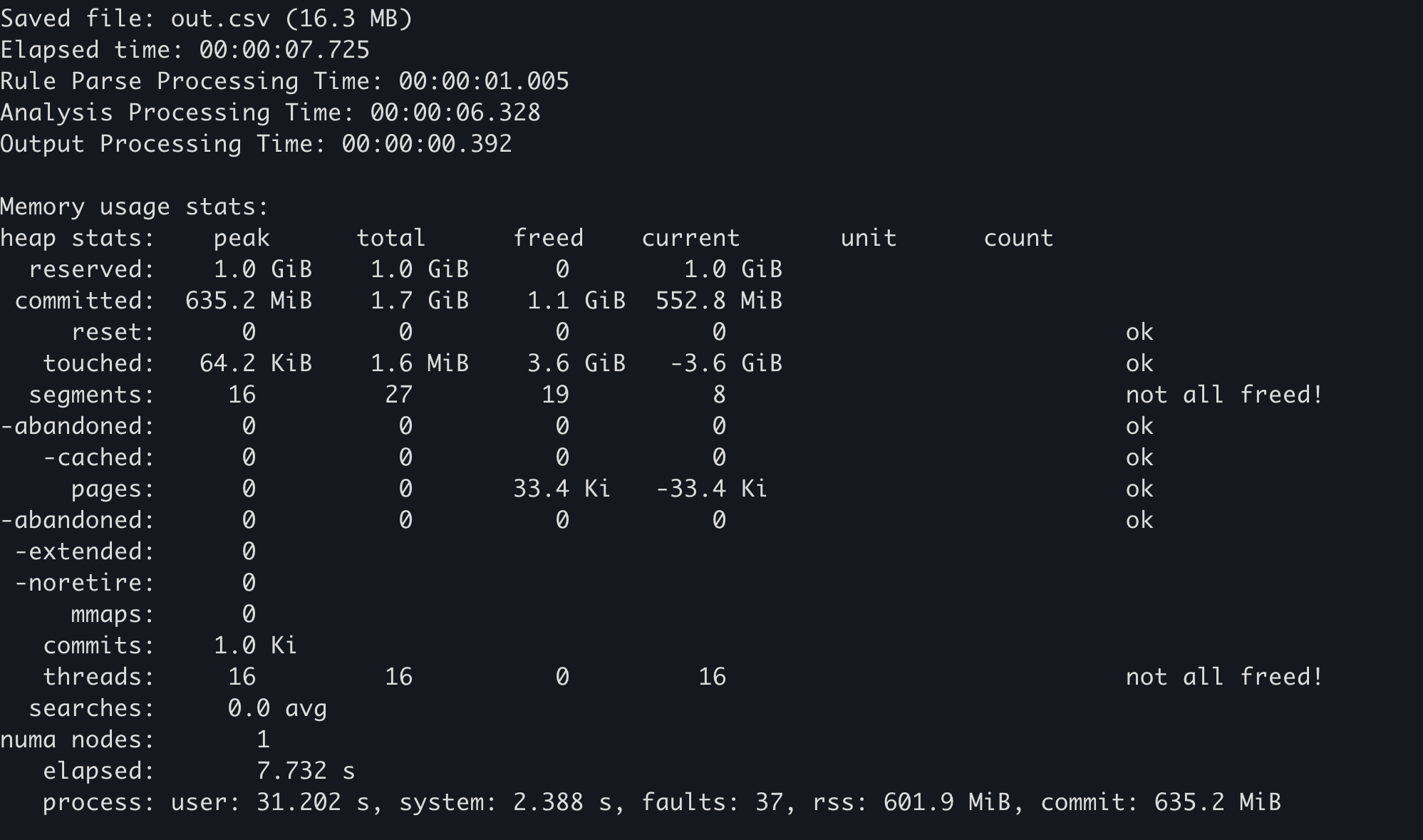
Exemplo ¶
A implementação acima foi aplicada no seguinte:
No Hayabusa, se você adicionar a opção --debug, as estatísticas de uso de memória serão exibidas ao final.
Use o contador de performance do Windows¶
Vários usos de recursos podem ser verificados a partir de estatísticas que podem ser obtidas do lado do SO. Neste caso, os dois pontos a seguir devem ser observados.
- Influência do software antivírus (Windows Defender)
- Apenas a primeira execução é afetada pela varredura e é mais lenta, então os resultados da segunda execução em diante após a build são adequados para comparação. (Ou você pode desabilitar seu antivírus para resultados mais precisos.)
- Influência do cache de arquivos
- Os resultados da segunda vez em diante após a inicialização do SO são mais rápidos que a primeira vez, porque evtx e outros IOs de arquivos são lidos do cache de arquivos em memória, então os resultados da primeira vez após o SO inicializar são mais ideais para realizar benchmarks.
Como obter ¶
Pré-requisitos:O procedimento a seguir só é válido para ambientes onde o PowerShell 7 já está instalado no Windows.
- Reinicie o SO
- Execute o comando Get-Counter do
PowerShell 7, que registrará continuamente o contador de performance a cada segundo em um arquivo CSV. (Se você quiser medir recursos além dos listados abaixo, este artigo é uma boa referência.) - Execute o processo que você quer medir.
Exemplo ¶
O seguinte contém um procedimento de exemplo para medir performance com o Hayabusa.
Use o heaptrack¶
O heaptrack é um sofisticado profiler de memória disponível para Linux e macOS. Ao usar o heaptrack, você pode investigar minuciosamente os gargalos.
Como obter ¶
Pré-requisitos: Abaixo está o procedimento para o Ubuntu 22.04. Você não pode usar o heaptrack no Windows.
- Instale o heaptrack com os dois comandos a seguir.
- Remova o seguinte código do mimalloc do Hayabusa. (Você não pode usar o profiler de memória do heaptrack com o mimalloc.
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L32-L33
- https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L59-L60
-
https://github.com/Yamato-Security/hayabusa/blob/v2.2.2/src/main.rs#L632-L634
-
Exclua a seção [profile.release] no arquivo
Cargo.tomldo Hayabusa e altere-a para o seguinte: -
Construa uma release build:
cargo build --release - Execute
heaptrack hayabusa csv-timeline -d sample -o out.csv
Agora, quando o Hayabusa terminar de executar, os resultados do heaptrack abrirão automaticamente em uma aplicação GUI.
Exemplos ¶
Um exemplo dos resultados do heaptrack é mostrado abaixo. As abas Flame Graph e Top-Down permitem que você verifique visualmente as funções com alto uso de memória.
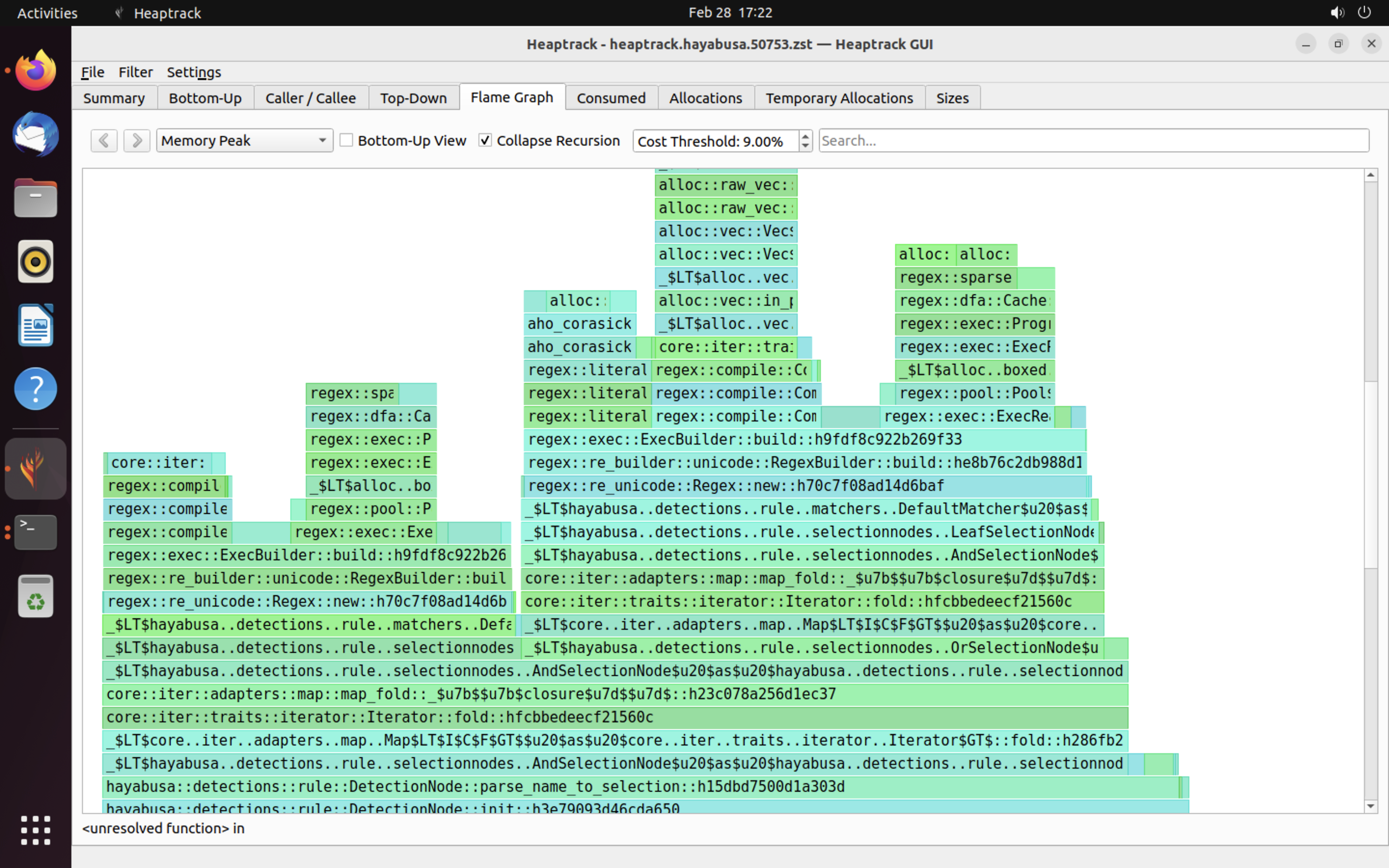
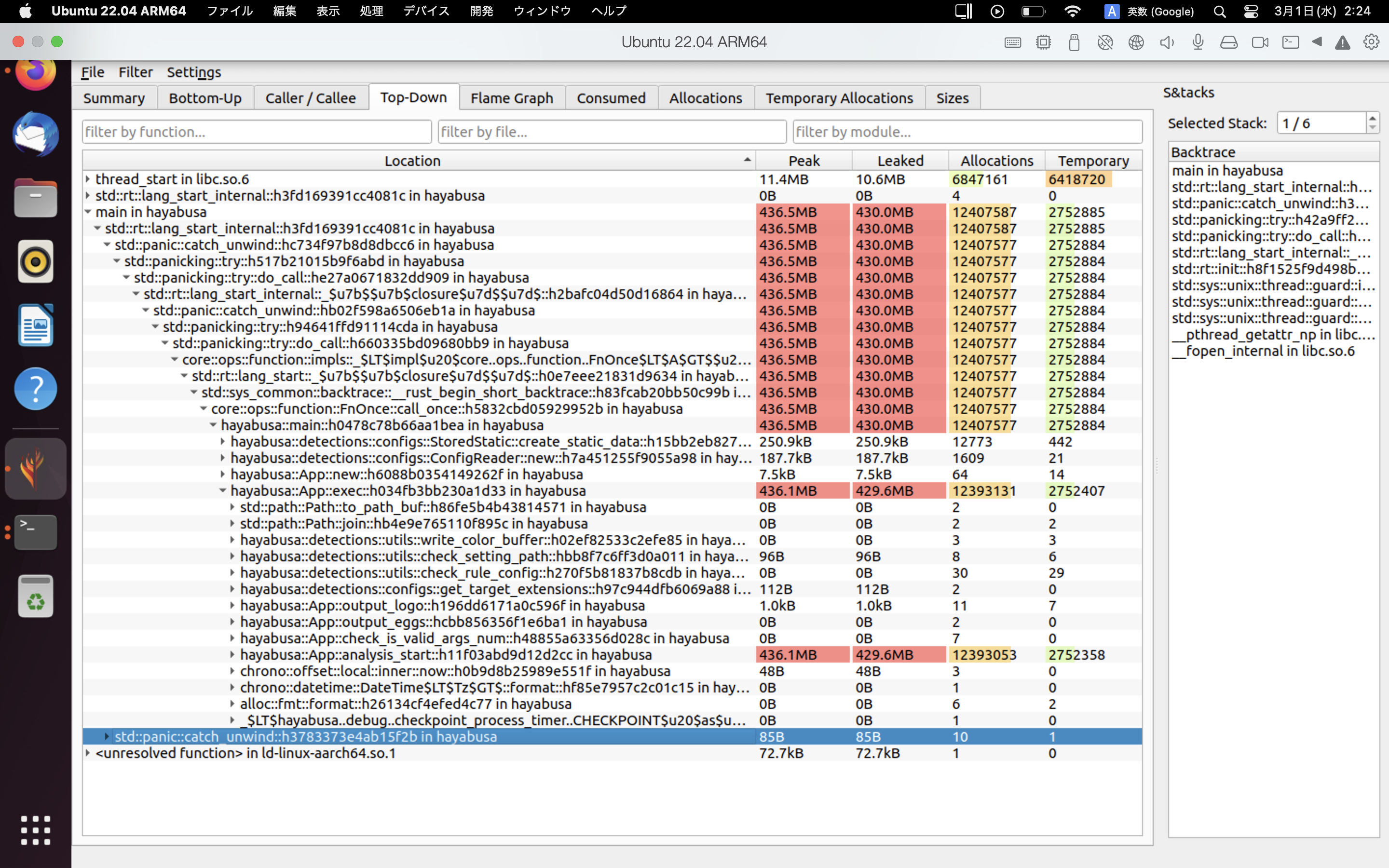
Referências¶
Contribuições¶
Este documento é baseado em descobertas de casos reais de melhoria no Hayabusa. Se você encontrar quaisquer erros ou técnicas que possam melhorar a performance, por favor, envie-nos uma issue ou pull request.